
本篇文章的稳定性实践会从下图的闭环流程展开介绍:
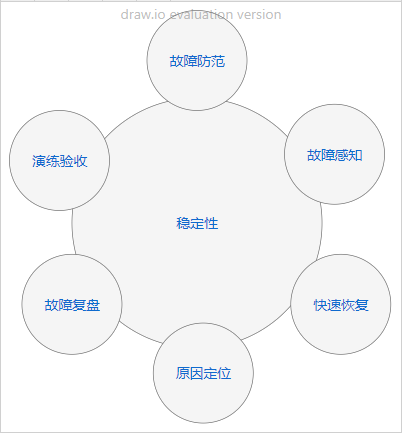
故障防范
- 我们的目标永远都是希望可以将故障发现的阶段提前,少遗漏或者不遗漏到线上环境
- 梳理核心链路,故障演练、压测等线下的发现问题的过程,都属于故障防范
- 将稳定性目标加入到提测流程中,对于核心功能或核心接口提测会提出稳定性标准
- 对于新增接口,需要进行接口不可用模拟及模拟下游服务不可用等常见稳定性问题,将稳定性融入迭代
这里介绍一个非常轻量便捷的工具来进行前端接口模拟,安装过程可以参考 https://www.w3ctech.com/topic/285。
安装成功后,可以看到chrome浏览器上多了一个这样的图标。

以访问百度为例:
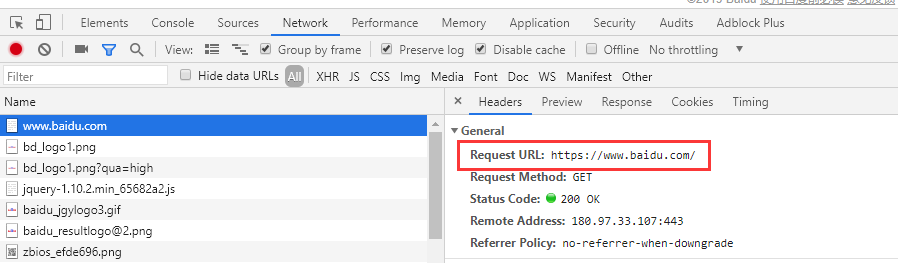
如果需要模拟该接口未获取到资源或者接口访问出错,可设置映射如下:
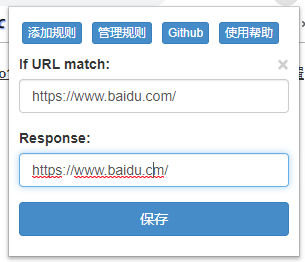
设置成功后可刷新访问页面,查看页面展示情况。之前我们的模拟中发现某些接口访问404,会导致整个页面白屏。对于这种情况,是需要前端做降级处理的。
核心链路梳理
- 从核心链路出发,梳理核心链路上下游依赖服务,区分强弱依赖
- 梳理更加体系化,区分强依赖和弱依赖,并给出针对性的故障预案
- 强依赖:一损俱损;弱依赖:一损有损。
强依赖尽可能修改为弱依赖,弱依赖要做到解耦,降级
例如,这是我们进入首页后的P0核心链路梳理模板:
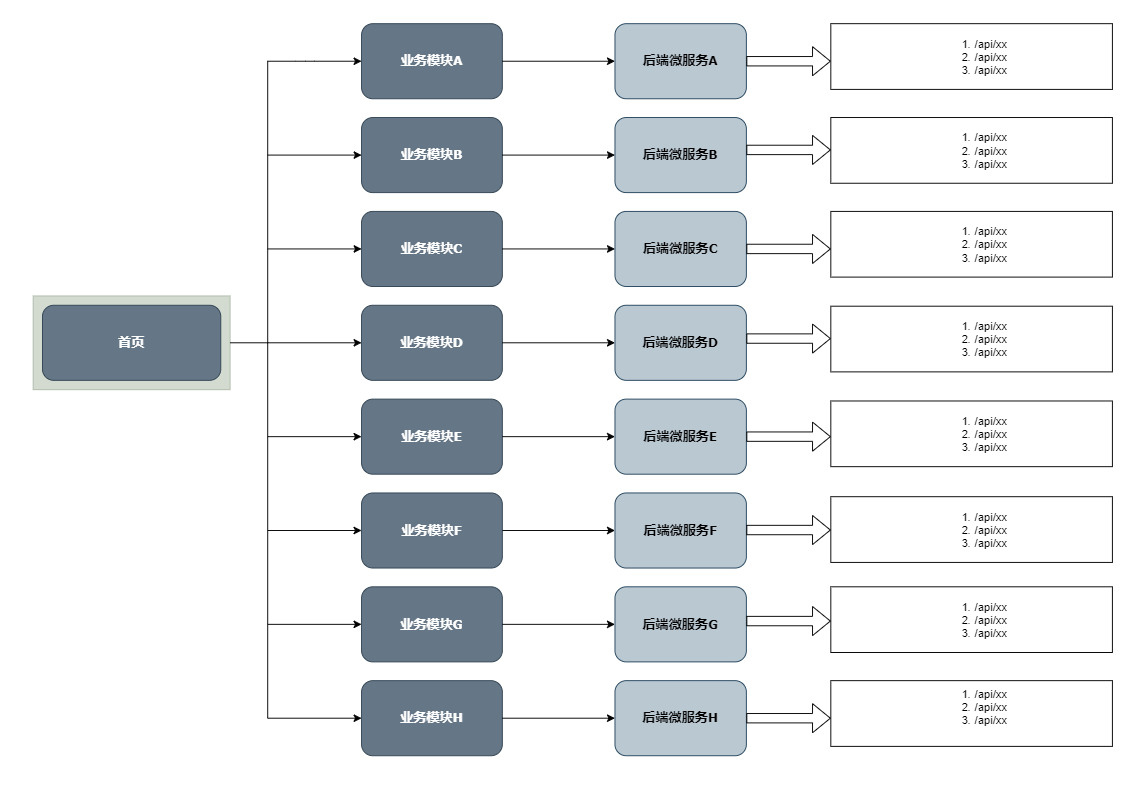
梳理完核心链路后,我们会对链路上的接口及服务做对应的故障演练。
之前故障演练的时候发现某个非核心的接口返回值不符合预期,会影响核心页面展示。
故障演练
- 从单场景的故障演练转化为全链路的故障演练,从梳理出的核心链路出发针对性的给出演练方案
- 故障演练前需给出详细的处理预案,并验证预案的正确性
- 更详细的演练手段,包括但不限于用iptables模拟下游服务不可用,磁盘IO溢出等
- 从以往经验及故障演练BP来看,后端稳定性问题主要分为单服务问题及服务间调用
从以往经验及故障演练BP来看,后端稳定性问题主要分为单服务问题及服务间调用

稳定性工作前移,融入迭代
- 对于核心业务,在提测的时候就提出稳定性要求
- 测试同学日常测试中,需要进行简单的故障演练,包括但不限于模拟前端接口不可用及模拟下游服务不可用的方法,便于提前发现问题
故障感知
- 利用现有警报系统,合理系统的设置警报规则
- 从线上故障出发,不断完善监控警报
- 对于页面链接错误能及时发现,可结合一些链接检测工具
故障快速恢复
- 通过故障演练提高研发快速恢复故障的能力,每次故障演练需提前给出修复预案,并在故障演练中验证预案的有效性
- 制定故障响应SOP,用于故障处理时的快速恢复
原因定位及故障复盘
- 对于线上故障,第一时间应该是先恢复故障
- 故障恢复后,需要对故障进行深度复盘,提出可落地的改进action
演练验收
- 这其实也是很重要的一个环节,对于线上因为依赖或者基础设施故障产生的问题,落地的action需要进行线下验证
- 对于线下故障演练优化后的action,需要在下一次的故障演练中做验收
关注我们
酷家乐质量效能团队热衷于技术的成长和分享,几乎每个月都会举办技术分享活动(海星日),每半年举办一次技术专题竞赛分享(火星日),并将优秀内容写成技术文章。
我们尽可能保障分享到社区的内容,是我们用心编写、精心挑选的优质文章。如果您想更全面地阅读我们的文章,请您关注我们的微信公众号"酷家乐技术质量"。

{kind=link}