
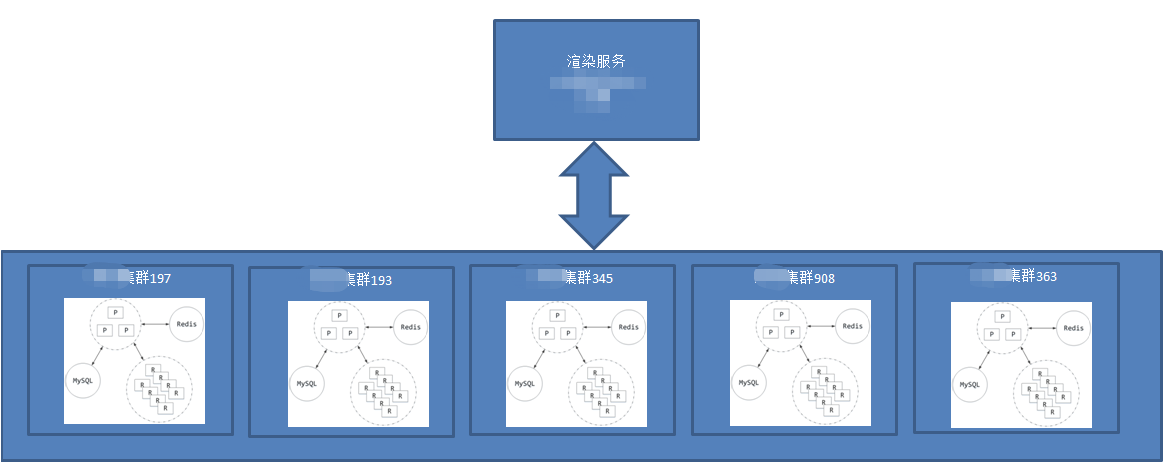
渲染后台架构
渲染集群几个机房,每个机房有proxy、renderservice、redis、mysql
- Proxy:控制节点,角色为 master 或 slave,每个集群至少部署 2 个以成环;
- Render:渲染节点,每个集群有上百个;
- Redis:存储任务信息、配置信息等等,以主备的方式部署;
- MySQL :存储任务调度信息、任务结果等持久化数据。

演练项
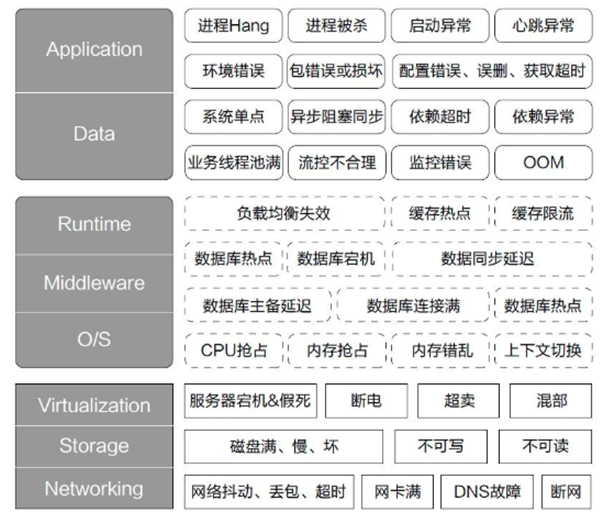
(图片来自网络)
渲染后台是较为底层的服务,redis是主要依赖的中间件,也是发生故障最多的地方。所以演练的重点是redis;
Redis
- 单点故障:kill one sentinel,kill all sentinel,kill master,
- 主从切换:来回 kill master
- 服务器宕机:one sentinel宕机,all sentinel 宕机,master宕机,all 宕机
- 网络异常: one sentinel网络不通,master网络不通
- 内存异常:redis maxme meroy打满,服务器内存耗尽
- CPU异常:one sentinel满载,master满载
- 磁盘异常:disk io 高,磁盘写满
- 备用redis切换
proxy
- 单点故障
- master 选举
- 负载均衡
- proxy 高负载压测
后续目标:
- CPU异常、网络异常、内存异常、磁盘异常
- 千台大集群proxy验证
mysql
- 网络异常
- 异常重连
网络
淮南机房目前渲染服务器接近一半的渲染资源在淮南机房。淮南机房公网出口为了稳定性保障,网络组已经部署两条电信线路:合肥和 江苏 ,目前现网渲染业务走合肥线路,江苏线路做为备份线路
主要模拟场景:当合肥线路中断后,防火墙自动切换到江苏线路后,业务层面使用域名DNS地址从合肥ip地址切换到江苏ip地址,保证业务能正常运行
演练目的
- 预案有效性:主要验证“备胎”靠不靠谱;系统强依赖的模块需要有降级、备用方案;需要对这类方案做有效性验证;
- 监控报警:报警的有无、提示消息是否准确、报警实效是5分钟还是半小时;
- 故障复现:故障的后续Action是否真的有效,完成质量如何,只有真实重现和验证,才能完成闭环。发生过的故障也应该时常拉出来练练,看是否有劣化趋势;
- 架构容灾测试:主备切换、负载均衡,流量调度等为了容灾而存在的手段的时效和效果,容灾手段本身健壮性如何;
- 参数调优:限流的策略调优、报警的阈值、超时值设置等;
关注我们
酷家乐质量效能团队热衷于技术的成长和分享,几乎每个月都会举办技术分享活动(海星日),每半年举办一次技术专题竞赛分享(火星日),并将优秀内容写成技术文章。
我们尽可能保障分享到社区的内容,是我们用心编写、精心挑选的优质文章。如果您想更全面地阅读我们的文章,请您关注我们的微信公众号"酷家乐技术质量"。

{kind=link}