
背景
酷家乐户型几何计算服务(下文简称kam)是计算密集型的服务,主要负责酷家乐户型业务的三维造体、渲染以及算量等模块,服务的特性是吞吐量低,cpu计算密集。
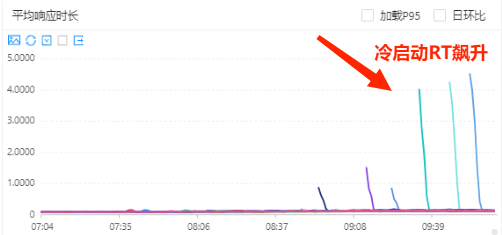
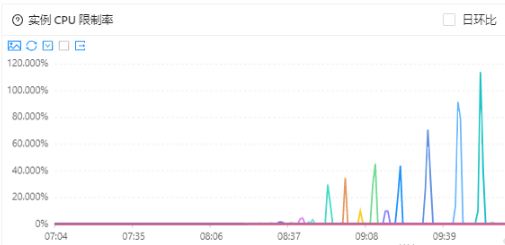
在高峰期进行动态扩缩容的时候,kam冷启动的表现一直以来都比较严峻,cpu使用率和cpu限制率会迅速飚高,进而影响服务的rt,严重时响应时间会到5s的程度,亟需治理。
在进行治理过程中,我们遇到2个奇怪的问题:
- 高分期扩容时冷启动初始流量高,无权重变化。详细见一次服务预热问题的定位排查记录(1)。
- prod环境开启预热反而比没有预热的效果更好,本文围绕这个问题,我们做了以下排查和定位。
问题表现
线上环境开启预热反而比没有预热的效果更好,表现如下:
开启预热:服务cpu使用率飙升到100%,cpu限制率飙升到150%,响应时间飙升到5s以上。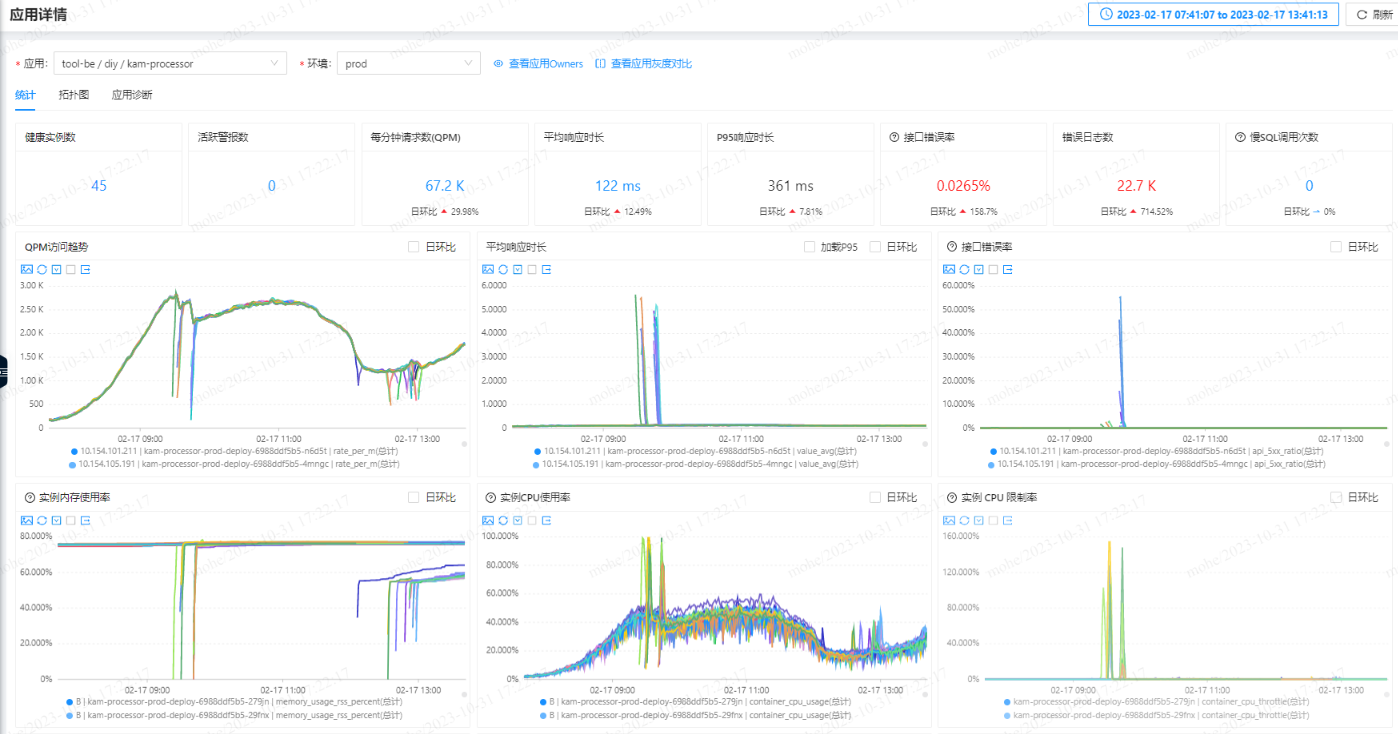
关闭预热:服务CPU使用率偶尔会有90%,cpu限制率基本还在40%以下,响应时间基本不波动,偶尔会抖。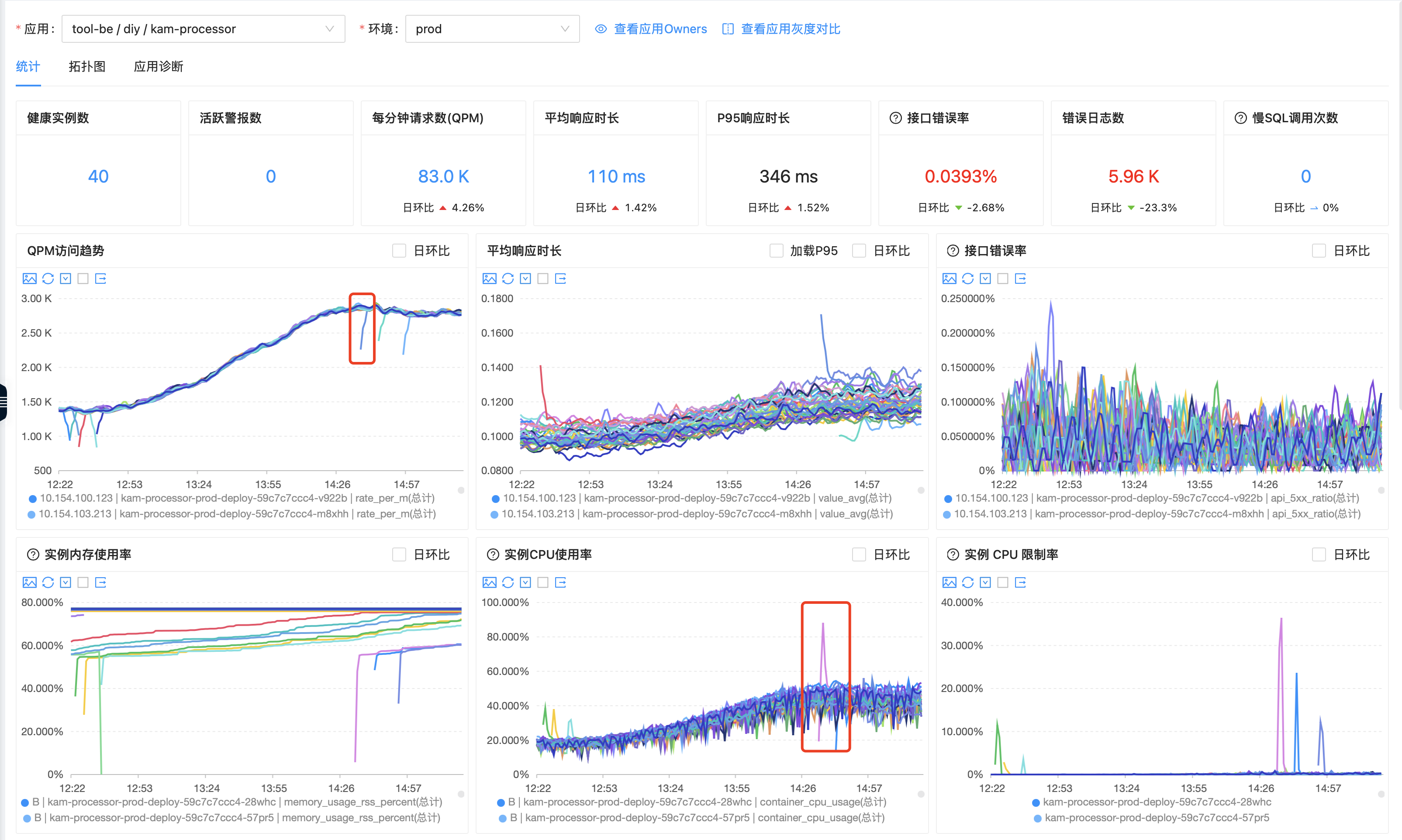
定位过程
观察prod的启动秒级流量,截图如下:
而开启预热的情况,截图如下:
我们得到以下开启预热和关闭预热的两种启动流量趋势图:
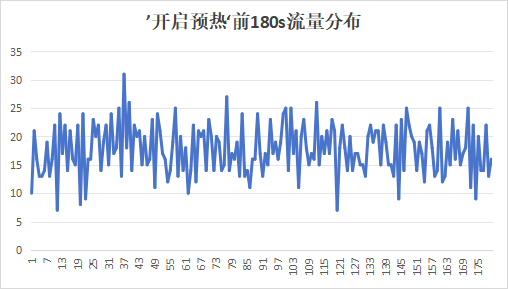
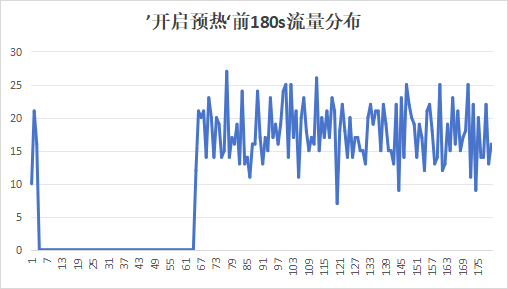
可以看到,发现不开启预热的时候,会出现流量截断的情况,会在初始几秒进来流量,过了几秒之后发现流量降到0,持续60s,然后再涌入流量;而开启预热的时候没有出现这种流量截断的情况。
很奇怪,咨询了soa中间件,讨论后,发现这个是由于之前接入优雅上线的poststart脚本中,有soa下线和上线逻辑,两者中间刚好有个调服务预热的逻辑,而预热时间刚刚好是60秒。代码如下:
# 开始健康检查,直到成功或者超时(600秒超时)
http_code=0
for (( i = 0; i < 60; i++ )); do
http_code=$(curl -s --max-time 10 -w "%{http_code}" -s -o /dev/null -X GET --header 'Accept: application/json' "${self_healthz_url}")
if [ "${http_code}" = 200 ]; then
echo "调用健康检查接口成功:url:${self_healthz_url}, code:${http_code}" >> ./logs/grace_log_
break
else
echo "调用健康检查接口失败:url:${self_healthz_url}, code:${http_code}" >> ./logs/grace_log_
sleep 10
fi
done
# 健康检查是否通过
if [ "${http_code}" != 200 ]; then
echo "健康检查未通过!" >> ./logs/grace_log_
exit 1
fi
# 由于soa的原因,调用上线之前要先调用一下下线接口
self_shut_down_url=${self_start_up_url//"${DEFAULT_START_UP_PATH}"/"${DEFAULT_SHUT_DOWN_PATH}"}
resultCode=$(curl -s --max-time 10 -X POST -w "%{http_code}" -s -o /dev/null --header 'Accept: application/json' --header ${coops_header} "${self_shut_down_url}")
if [ "${http_code}" != 200 ]; then
echo "调用shutDown接口出错,url:${self_shut_down_url},http_code:${resultCode}" >> ./logs/grace_log_
exit 1
fi
# 调用预热加载功能,对接口不敏感
resultCode=$(curl -s --max-time 150 -X GET -w "%{http_code}" -s -o /dev/null --header 'Accept: application/json' --header ${coops_header} "${pre_start_up_url}")
# 调用上线接口
result=$(curl -s --max-time 10 -X POST --header 'Accept: application/json' --header ${coops_header} "${self_start_up_url}")
if [ "${result}"x = '"ALREADY_UP"'x ] || [ "${result}"x = '"OK"'x ]; then
echo "soaPostStart成功:url:${self_start_up_url}, result:${result}" >> ./logs/grace_log_
else
echo "soaPostStart失败:url:${self_start_up_url}, result:${result}" >> ./logs/grace_log_
exit 1
fi
同时我们搜索了对应的日志,发现注册和注销时间点和秒级日志时间点也对的上。
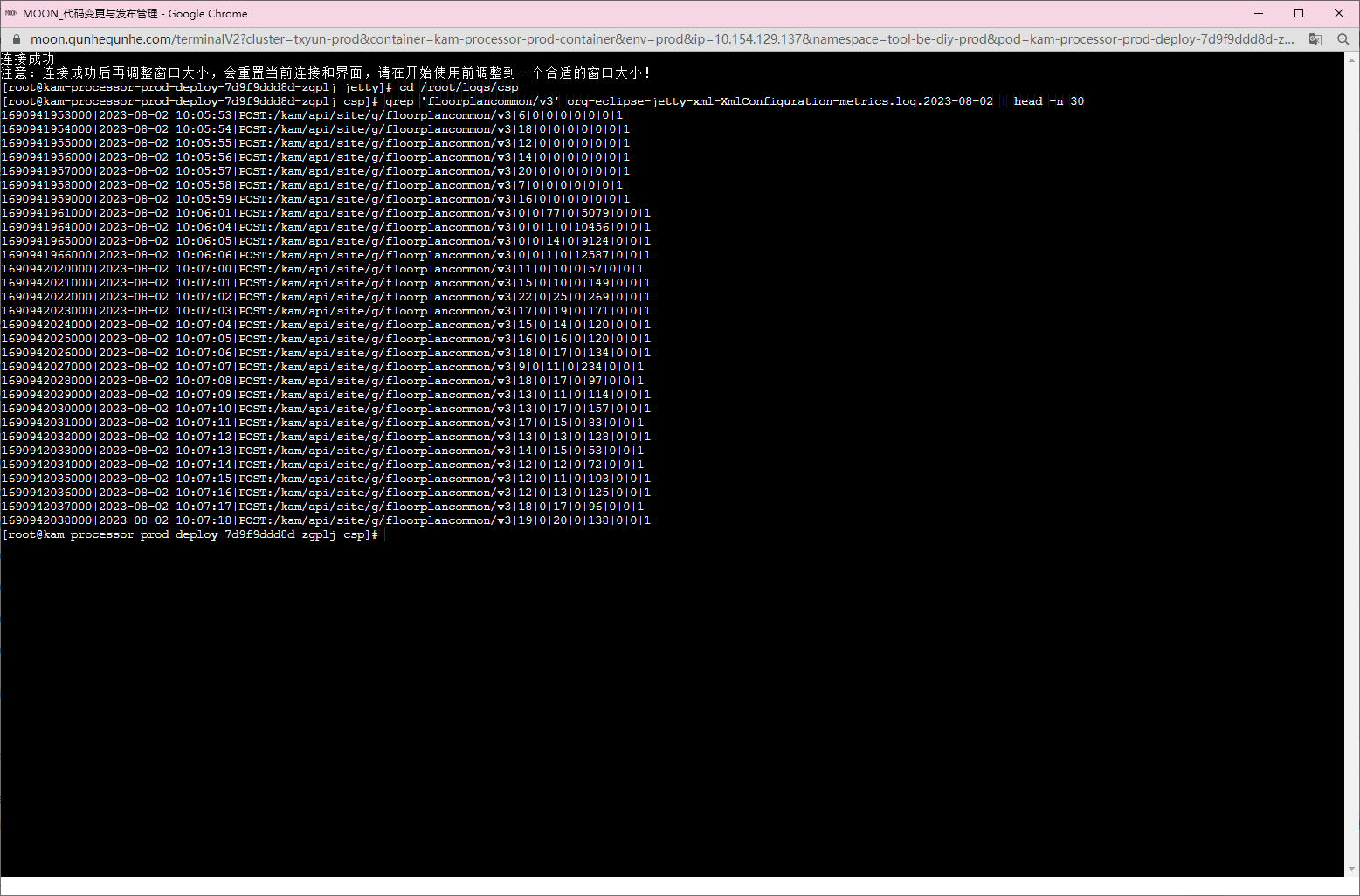


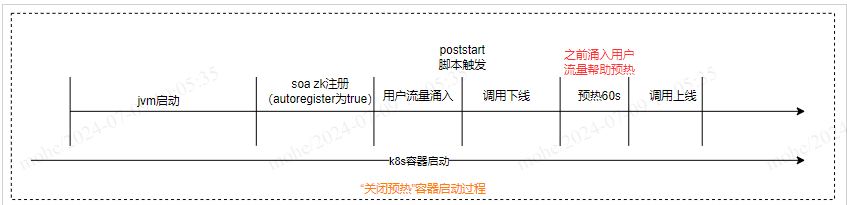
也就是说,如上述流程所示,因为用户请求被截断,前置请求被作为了服务预热的一部分,再加上1分钟的自定义逻辑的预热,当脚本调用上线接口恢复用户流量时,prod环境的接口耗时,cpu限制率都处于一个比较能接受的水平,服务指标如下:
我们想到难道kam,用用户流量进行预热,比触发预热逻辑来进行预热,效果要更好。
由此,我们有一个思路,是否可以在当前预热现状(prod流量迁移至prod_warm环境,预热表现尚可)的基础上,在poststart脚本中模拟关闭预热的情况,来进一步改善预热,思路:先调用服务接口进行hbase/redis等连接→ 调用上线接口,等待5s用户请求→ 调用下线接口→ 进行服务预热逻辑→ 调用上线接口,流程如下。这样相比于关闭预热,我们可以预处理一些中间件的连接,保证服务上线后第一次用户请求不会有连接超时导致的错误,同时也能起到加速jit编译的效果。
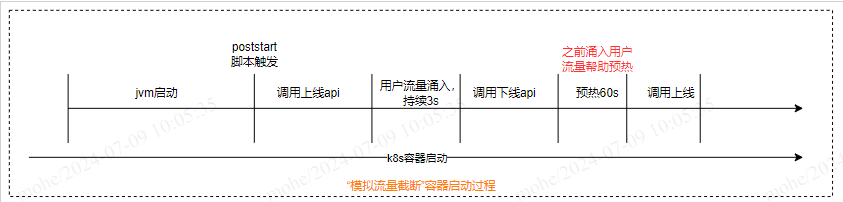
验证
为了验证上述结论:
- 是否是poststart脚本导致“prod关闭预热反而比开启预热效果更好”。
- 新的思路“先调用服务接口进行hbase/redis等连接→ 调用上线接口,等待5s用户请求→ 调用下线接口→ 进行服务预热逻辑→ 调用上线接口”,是否可行,效果是否更好。
我们尝试进行内网压测验证,总结压测结果,表现如下:
| 场景(每种压测两次) | 最高rt |
|---|---|
| 不开启预热 | 平均4s |
| 开启预热 | 平均2.7s |
| 截断流量,用户请求预热 | 平均0.8s |
压测结论:通过内网压测,可以看出来,冷启动在不同配置下,确实效果会有这样一个效果差异:用用户流量进行服务预热 > 关闭预热 > 开启预热
结论
所以我们可以得出结论:
- poststart脚本导致“关闭预热反而比开启预热更好”。
- 按照压测结果,先调用服务接口进行hbase/redis等连接→ 调用上线接口,等待5s用户请求→ 调用下线接口→ 进行服务预热逻辑→ 调用上线接口”,效果更好。
如何解决:
小流量服务预热模型:
相⽐于⼀般场景下,刚发布微服务应⽤实例跟其他正常实例⼀样⼀起平摊线上总 QPS。⼩流量预热⽅法通过在服务消费端根据各个服务提供者实例的启动时间计算权重,结合负载均衡算法控制刚启动应⽤流量随启动时间逐渐递增到正常⽔平的这样⼀个过程帮助刚启动运⾏进⾏预热,详细 QPS 随时间变化曲线如图所示:
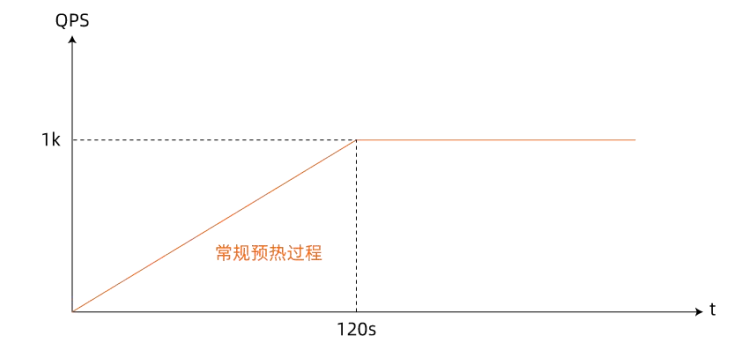
服务提供端在向注册中⼼注册服务的过程中,将⾃身的预热时⻓ WarmupTime、服务启动时间StartTime 通过元数据的形式注册到注册中⼼中,服务消费端在注册中⼼订阅相关服务实例列表,调⽤过程中根据 WarmupTime、StartTime 计算个实例所分批的调⽤权重。刚启动StartTime 距离调⽤时刻差值较⼩的实例权重下,从⽽实现对刚启动应⽤分配更少流量实现对其进⾏⼩流量预热。
开源 Dubbo 所实现的⼩流量服务预热模型计算如下公式所示:
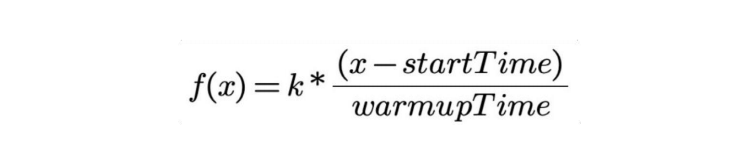
模型中应用 QPS 对应的 f(x) 随调用时刻 x 线性变化,x 表示调用时刻的时间,startTime 是应用开始时间,warmupTime 是用户配置的应用预热时长,k 是常数,一般表示各实例的默认权重。
这种方式需要soa做一次soa流量权重的控制,基于这个预热模型,再加上一层强制控制一段时间流量不超过上限,可以达到服务平稳上线的效果。
逐步开放流量:
通过冷启动机器的流量大小, 用低流量来先去诱发JIT, 再把发布机器的流量设置到正常水位, 避免在JIT过程中, 因为全量流量进来导致的CPU飚高、LOAD飚高、RT飚高等问题, 使得应用发布或重启时顺滑平稳。较为典型的是应用中的RPC服务,通过将项目中的HSF服务分批发布,逐步放开HSF调用的流量,可以减小由于大流量导致的JIT编译,缓解c2 compiler线程骤增对CPU占用过高的问题。应用启动后,利用网关的流量控制功能,按照时间间隔逐步放入流量,如:10%,20%...100%,或者给予不同的访问权重,使得服务能够逐渐到达正常访问的热度。例如,如果发现应用是重启,则开启流量分步加载策略,每当入口流量达到流量上限, 线程就Sleep下一秒,过后继续放量。根据时间间隔,逐步放开流量限制。
这种方式其实就是我们公司的soa流量权重控制,可以通过qunhe.service.warmUpTimeInSeconds进行配置权重变化的时间。但是这种方式显然就是本文第一个问题所阐述的没办法解决吞吐量小、上游多的时候,初始流量高、无权重变化的问题。
龙井预热:
阿里内部在OpenJdk的基础上进行了扩展形成Ajdk,拥有更多的功能,而龙井(DragonWell)是Ajdk定制版的开源版本,供各界使用学习。Jwarmup正是Ajdk的功能。
JwarmUp的基本原理:根据前一次程序运行的情况,记录热点代码以及类加载顺序等信息。在应用下一次启动的时候积极主动地对相关类进行加载,并积极编译相关代码,进而使得应用尽快使用上C2编译优化的指令。从而在流量进来之前,提前完成类的加载、初始化和方法编译, 跳过解释阶段, 直接执行编译好的native code, 避免一面解释执行一面后台编译带来的CPU与load飙高, rt超时等问题。
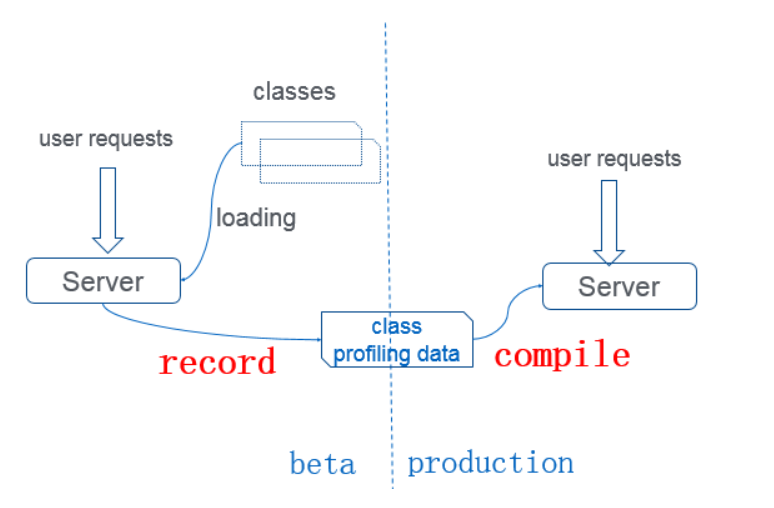
jwarmup使用的场景如下图蓝色曲线所示:项目发布阶段,大量的解释执行时把CPU占满,导致没有足够的CPU进行编译,会导致CPU打满并长时间在解释运行,没有机会编译,CPU的利用率会长时间居高不下。而开启了jwarmup后如下图红色曲线所示,大大缩短了编译的时间。也就是说jwamup可以跳过解释直接进入编译阶段。
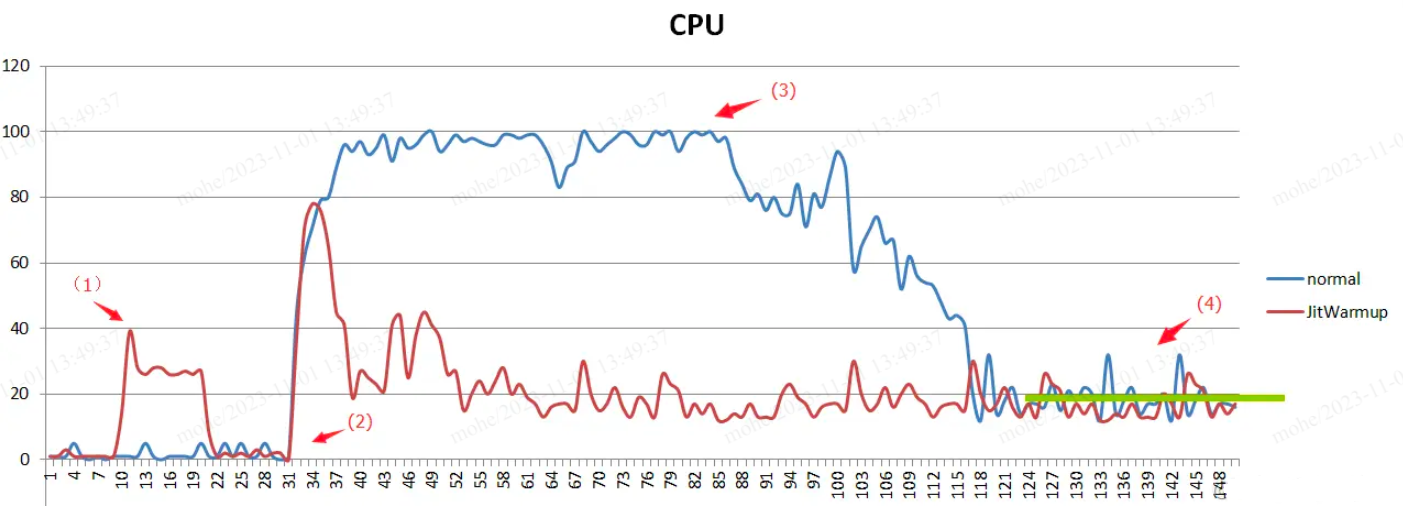
对于kam来说,它是由于激进的jit编译导致cpu飙升。jwarmup可以跳过解释直接进入编译阶段,并不能解决kam的问题。
AppCDS-java10特性
CDS的全称是 Class-Data Sharing,CDS的作用是可以让类可以被预处理放到一个归档文件中,后续Java程序启动的时候可以直接带上这个归档文件,这样 JVM 可以直接将这个归档文件映射到内存中,以节约应用启动的时间。
这个特性其实JDK 1.5就开始引入了,但是CDS只能作用与Boot Class Loader加载的类,不能作用于App Class Loader或者自定义的 Class Loader 加载的类,其实有点鸡肋,而且这个是Oracle JDK的商业特性,在OpenJDK中似乎没有。
在Java 10中,则将CDS扩展为AppCDS,顾名思义,AppCDS不止能够作用于Boot Class Loader,App Class Loader和自定义的Class Loader也都能够起作用,大大加大了CDS的适用范围。有了AppCDS,可以给Java的应用程序带来两个方面的好处:
- 可以提升一些大型的Java应用的启动速度。
- 可以提升Serverless的应用程序的启动速度。我觉得这个点可能是 Java 10 提供 AppCDS 的主要原因,Serverless 极可能成为未来的应用的一种非常常见的形态,而把 Java 应用在 Serverless 上,相比于其他的语言来说,一个很大的劣势就是 JVM 的启动速度太慢了,虽然像 AWS 的Lambda,会给Java的Serverless应用加上-client来用Client模式跑加快启动速度,但是实际上效果甚微。有了AppCDS,可以大大加快Serverless应用的启动速度,按照 AppCDS 的 JEP 的说明,对于一个JEdit来说,AppCDS可以为JEdit提升20%到30%的启动速度。
AppCDS主要在于提高应用程序的启动速度,思路类似jwarmup,它可以跳过类加载提前进入解释和编译阶段,对于kam痛点主要在于初始流量高以及激进的jit编译导致的cpu超限问题,AppCDS不能解决kam的问题。而且公司目前仍旧使用java8,对于升级带来的工作量也是比较大的,但是可以作为一个新的思路尝试做探索。
总结
kam因为吞吐量低、cpu密集的特性,冷启动的情况严峻,具体包括两个方面:
- 冷启动初始流量大,导致cpu限制率飙升,rt变高。
- 会有反直觉的效果,开启服务预热,相比没有服务预热,效果反而会变差。
我们深入分析了这两个问题,原因分别是:
- 上游过多,并发比较高的时候,到下游起始流量高。
- 因为同时接入优雅上下线以及关闭了预热,导致有流量截断的情况,初始流量作为了预热的一部分,反而增强了服务冷启动性能。
从而得出kam更加倾向于用户流量进行预热的预热方式。预热新思路:目前kam的预热已经优化至比较理想的状况,在此基础上,我们在poststart脚本中模拟流量截断的过程,来进一步增强冷启动的性能。
参考
- 谈谈Java应用发布时CPU抖动的优化
- Alibaba Dragonwell
- Sentinel
- APPCDS
- 《微服务治理技术白皮书》
){kind=link}