
背景
酷家乐户型几何计算服务(下文简称kam)是计算密集型的服务,主要负责酷家乐户型业务的三维造体、渲染以及算量等模块,服务的特性是吞吐量低,cpu计算密集。
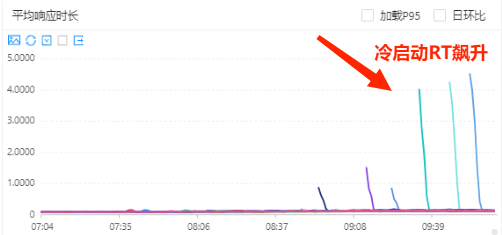
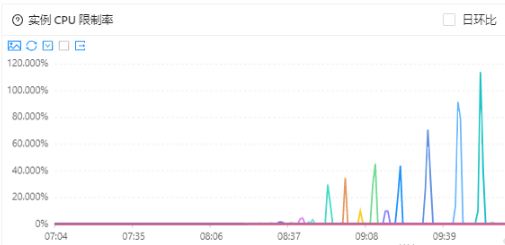
在高峰期进行动态扩缩容的时候,kam冷启动的表现一直以来都比较严峻,cpu使用率和cpu限制率会迅速飚高,进而影响服务的rt,严重时响应时间会到5s的程度,亟需治理。
在进行治理过程中,我们遇到1个奇怪的问题:高分期扩容时冷启动初始流量高,无权重变化。围绕这个问题,我们做了一系列排查和定位。
问题表现
通过sentinel的秒级监控,我们统计了kam启动的前180s流量变化,趋势图如下:
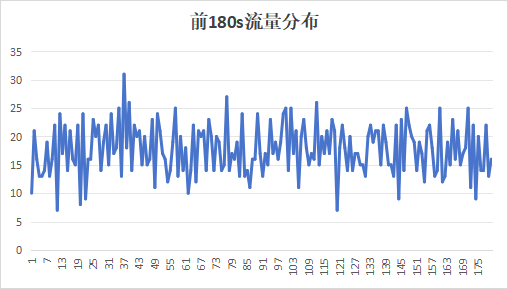
服务冷启动的时候初始流量很高,瞬间达到线上平均QPS,虽然配置了180秒的流量预热时间(机器流量的权重会在180s内从0均匀增加到100),但是并没有看上去并没有生效。
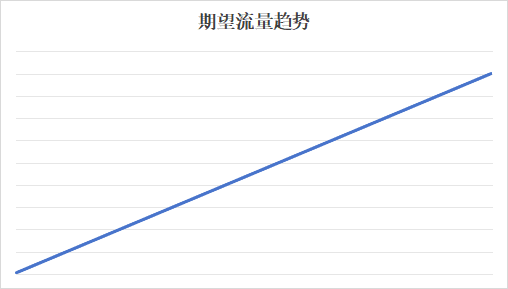
而我们理想状况下,希望启动机器的流量如下分布,随着流量逐步增加,服务不会一下被打死,服务的性能随着jit编译预热的进行逐步提高。
定位过程
先来看下kam目前的客户端负载均衡算法,用到的是平滑加权轮询算法,类似代码如下,流程详看注释:
public Server choose(final ILoadBalancer lb) {
int maxWeight = 0;
int minWeight = Integer.MAX_VALUE;
int weightSum = 0;
// linked map记录加入顺序
final LinkedHashMap<Server, IntegerWrapper> weightMap = new LinkedHashMap<>();
final List<Server> svrs = serverList;
for (int i = 0; i < svrs.size(); i++) {
final int weight = getWeight(svrs.get(i));
// 所有weight中的最大值
maxWeight = Math.max(maxWeight, weight);
// 所有weight中的最小值
minWeight = Math.min(minWeight, weight);
if (weight > 0) {
weightMap.put(svrs.get(i), new IntegerWrapper(weight));
weightSum += weight;
}
}
final int curIndex = nextIndexAI.getAndIncrement();
// 存在不同的权重,则使用weighted round robin算法
if (maxWeight > 0 && minWeight < maxWeight) {
// 在total weight中的位置
int mod = curIndex % weightSum;
// 逆向推算mod位置是什么元素
for (int i = 0; i < maxWeight; i++) {
// 按元素顺序轮询
for (final Map.Entry<Server, IntegerWrapper> entry : weightMap.entrySet()) {
final Server svr = entry.getKey();
final IntegerWrapper w = entry.getValue();
// 已完成mod次排放
if (mod == 0 && w.getValue() > 0) {
return svr;
}
if (w.getValue() > 0) {
// 排放一个svr
w.decrement();
mod--;
}
}
}
}
// 退化为取模轮询
return svrs.get(curIndex % svrs.size());
}
搞个简单的单测看下不同权重的调用情况:
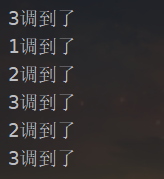
如果设置a的权重为3,b的权重为2,c的权重为1,并且是按照顺序调用的。那么结果的调用数量和调用顺序就是abc abc ab这样。 理论上kam新启动的机器应该有一个流量权重的变化。但是在问题表现中我们看到初始流量就很高了。
有点奇怪,我们和中间件一起做了定位,定位后发现负载均衡有一个固有缺陷,如下:
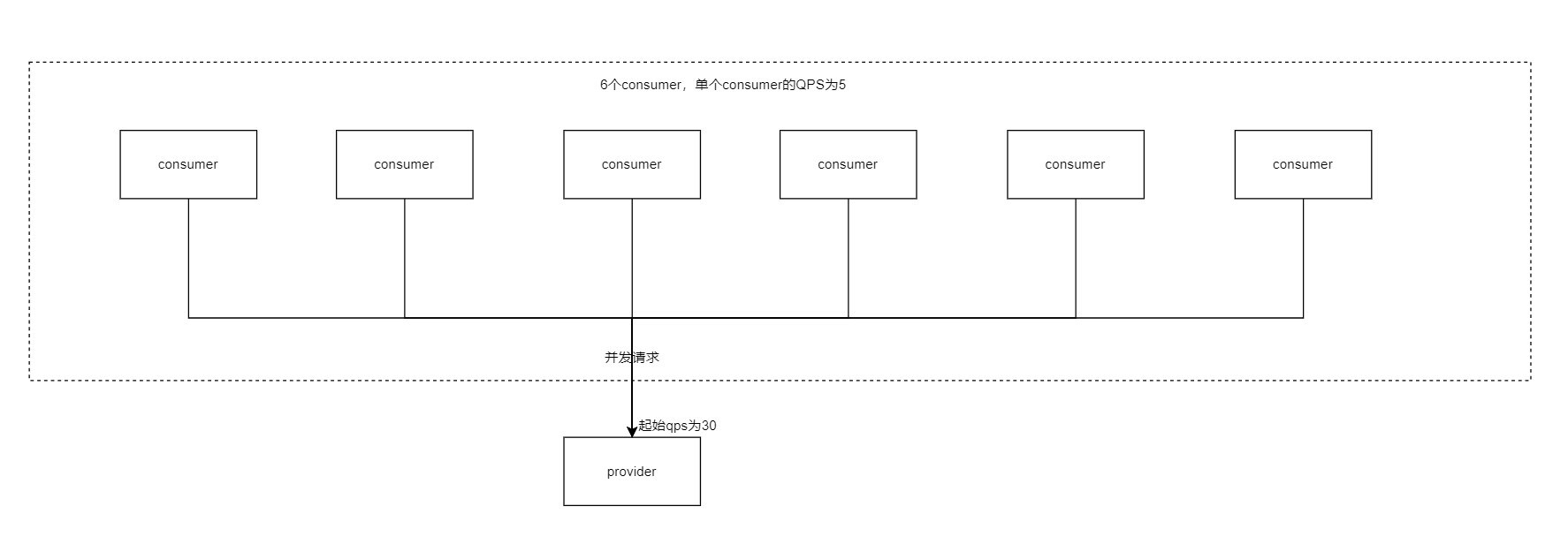
如果一个服务有6个consumer,每台consumer的qps有5,我们不考虑网络阻塞或者服务器抖动这种外界因素,虽然会通过加权轮训算法进行负载均衡,但是到达provider的流量为(consumer*consumer qps)/provider机器数,瞬间就能够到达30qps。
那么我们有理由猜测,没有权重变化的原因完全可能和服务特性和上游服务太多有关系,因为kam属于吞吐量小的服务,单台qps为20-30左右,而上游的consumer服务很多,有42个服务。
假设每个服务有10台机器,qps为4,那么到达kam的流量就会到达1600qps,kam线上高峰有70台机器,所以单台就有20-30的qps,起始就会有一个比较大的基础流量,符合问题表现中启动流量趋势的表现。
验证
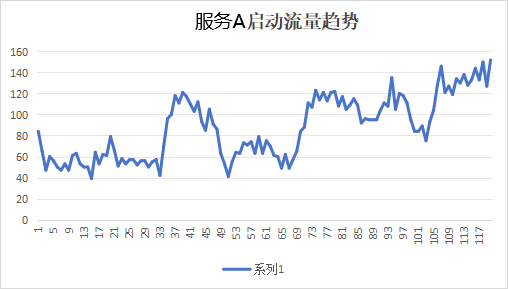
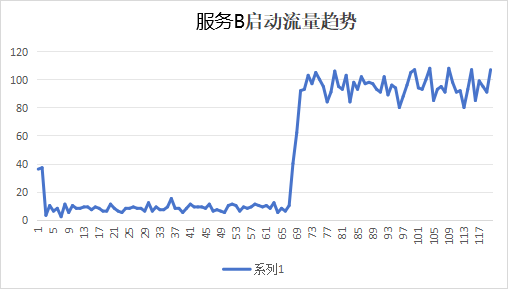
我们再挑一个和kam本身比较类似的有较多上游服务A,以及一个上游数量少的服务B, 服务A上游有40个左右,服务B上游较少,只有7个。我们统计了他们的启动流量趋势,来做验证,趋势图如下:
从上图表现可以看出:
- 服务A上游较多,可以看到流量类似kam从一开始就到了一个比较高的水位50qps左右;
- 服务B上游较少,虽然没有明显的线性过程,但是有明显的从0到100权重变化的过程,到70s左右到达服务平均qps。
结论
所以我们就可以验证这个结论:上游越多,qps权重变化越明显,冷启动的qps越高;上游越少,qps权重变化越明显,冷启动的初始qps越低。
换个角度思考,如果能做到冷启动时候起始qps足够低,有权重的变化,服务应该就能够有充足的cpu资源进行预热编译,那么服务在预热完成后启动表现出来的性能也就能更加稳定。
如何解决以及总结
针对现实场景,对于kam这样上游如此多,流量基数特别大,而本身吞吐量又小的服务,在流量平稳的情况下,平滑加权轮询算法是非常合适的,它的流量分布比较均匀,有利于动态调整提供者权重。但是它仍然存在固有的缺陷:在冷启动的时候初始流量高。而且常用的客户端式负载均衡算法比如随机、加权轮训、最小连接数、最小活跃数等都会有相同的问题 ,无法避免。除非可以在客户端做一些全局的限流,但是有待验证可行性。而且经过调研(比如sentinel的warmup的流控模式是个研究方向,但是对于请求来说是有损),业界貌似也没有相关的实践来解决这个启动流量的问题。
但是我们可以换个角度来解决这个问题,既然初始流量高我们暂时解决不了,那么我们就需要从提升服务性能的角度来提高冷启动的性能。那如何针对实际情况来提高kam启动性能,我们留到下一篇文章再来讨论这个话题。
){kind=link}