
背景
你是否因为经常需要查询服务日志害怕遗漏潜在问题到线上出现质量问题而担心;
你是否因为成千上万条的错误日志顾暇不及而不知如何下手;
你是否因为每次通过日志发现问题后人肉记录的重复过程感到枯燥无趣;
那么你现在可以加入我们的日志走查平台,我们已经将 日志走查→发现问题→聚合问题→上报问题→消息通知 整个过程自动化掉,你只需要简单的平台化配置即可解决上述问题,节省人力,提升人效,避免可能遗漏的潜在质量问题;
目前该平台已经在硬装业务线运行一年时间,已经有23个服务加入,所以快点加入我们来体验吧!
走查逻辑
1.数据获取
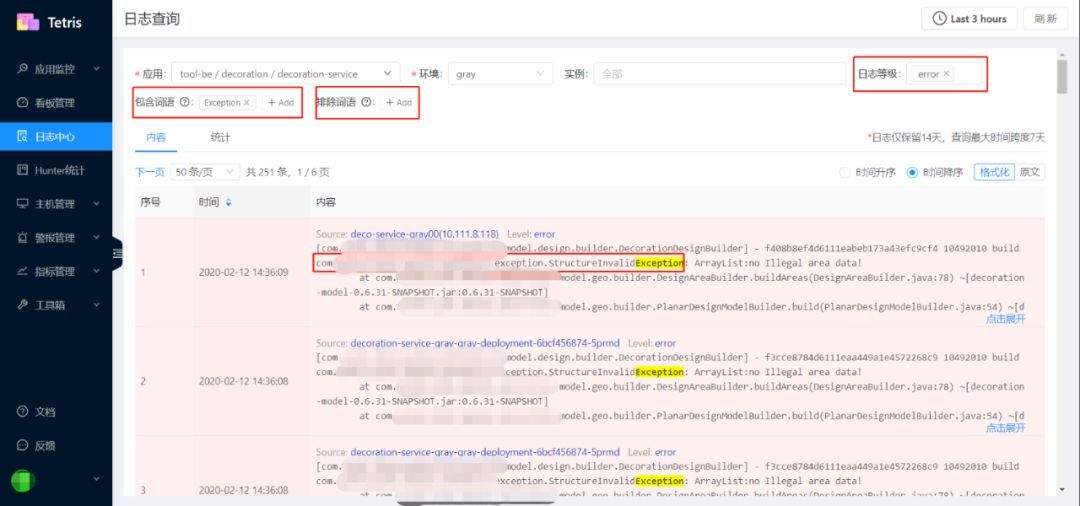
数据源来自于Tetris日志中心,现阶段数据获取规则如下:
- 日志等级:error
- 包含词语:Exception
- 排除词语:需要排除的关键词,一般是ExceptionType
- 默认限制条数:一万条,根据工具线每日异常数量分析后定的此限制数值,现阶段一般不会超出此数目
- 时间范围:today so far
2.异常统计
- 根据ExceptionType归类统计,归类异常后过滤出数量>=3的异常、对应的堆栈信息及hunterId,部分逻辑如下:
originalMap.put(exceptionType,originalMap.get(exceptionType) == null ? 1 : originalMap.get(exceptionType) + 1);
validMap = Maps.filterValues(originalMap, r -> r >= 3); - 异常栈存在多个ExceptionType的情况取最后一个Cause by的ExceptionType进行统计
- 上报的异常会记录到异常问题表方便比对及后期趋势分析,指定应用指定环境下当天统计过的异常不被再次记录
3.问题上报
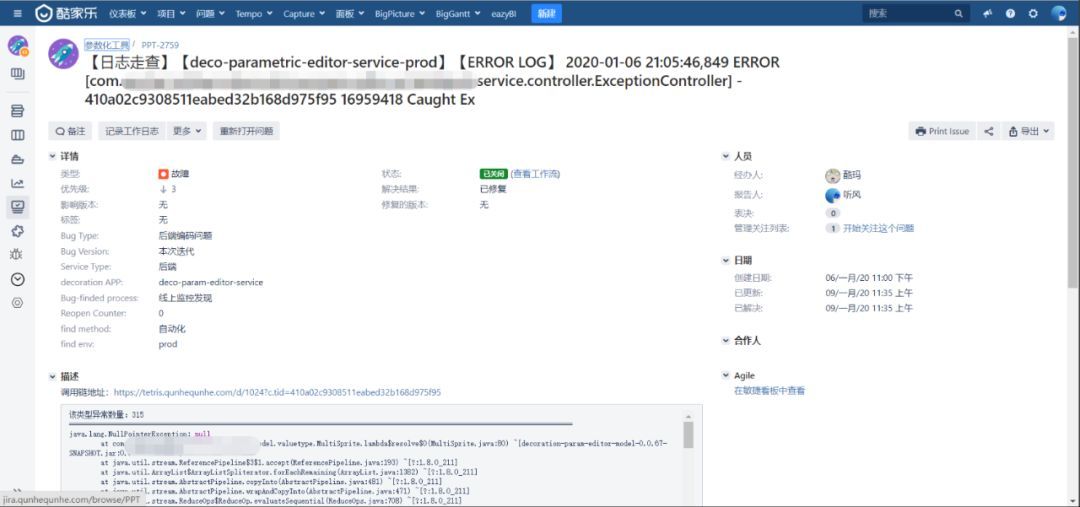
将最终发现的问题提交到Jira或者Kaptain中,Bug标题以【日志走查】+【服务环境】+【ERROR LOG】开头;
Bug详情信息包括:
- 类型
- 优先级
- Bug Type
- Service Type
- decoration APP
- Bug-finded process
- find method
- find env
Bug描述信息包括:
- 调用链地址
- 异常统计数量
- 异常堆栈
平台使用
新建项目
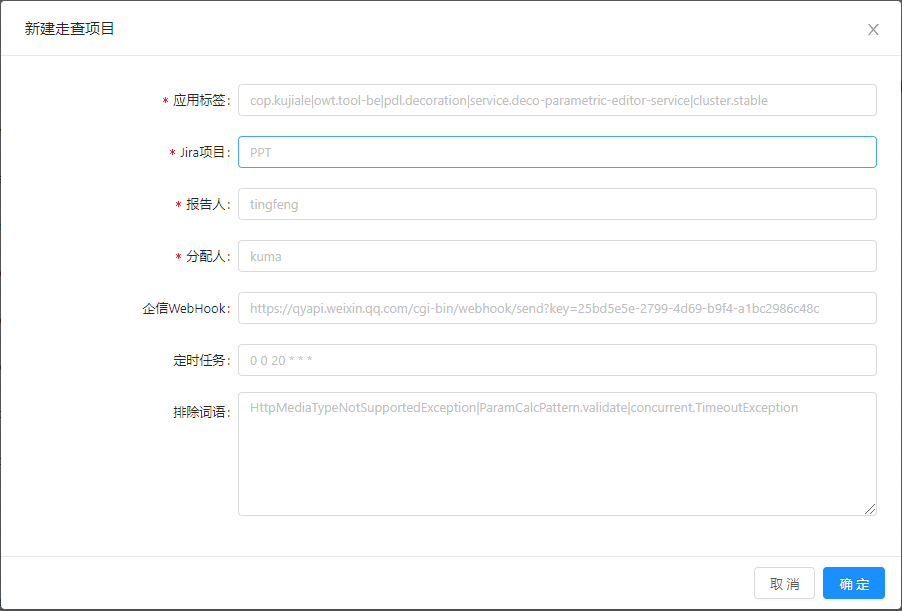
应用标签:必填项,可以从cmdb上查看,具体到cluster级别;例如:cop.kujiale|owt.web-be|pdl.saas|service.tob|cluster.prod;
Jira项目:必填项,走查发现的问题会提交到设置的Jira项目中,目前在增加对Kaptain的支持;
报告人:必填项,走查发现问题的上报人,一般设置成自己;
分配人:必填项,走查发现问题的分配方,一般指定为具体的开发人员;
企信WebHook:选填项,此处设置企信机器人地址,走查发现问题后会通知到机器人所在群,方便配合定时任务快速发现问题;
定时任务:选填项,使用cron表达式配置,业务方可以根据自身需求去灵活设置,如硬装业务线灰发环境配置:0 0 14,15,16,17,18,21 * * WED,THU(每周周三周四14、15、16、17、18、21点定时走查);
排除词语:选填项,对应Tetris日志中心的排除词语功能,词语之间使用|进行分割,对于不想记录的异常或者特定问题可以设置此选项;如设置TimeoutException,所有包含“TimeoutException”关键字的异常都会被过滤掉;如果想更精确的排除异常,则需要更精确的设置排除词语,如“SocketTimeoutException”;随着排除词语的积累,走查提交的问题的有效性也会逐步提升;
项目列表
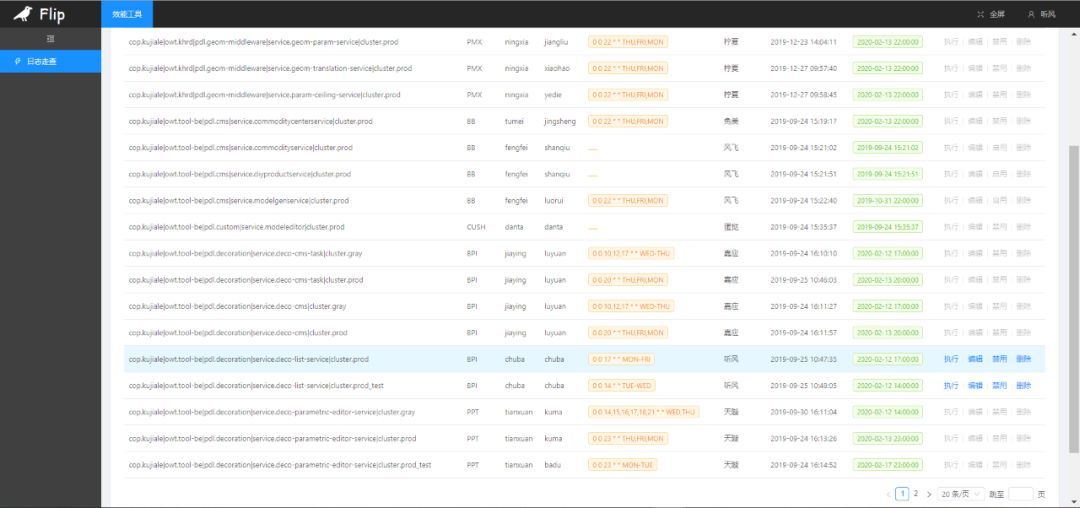
一条创建好的走查项从左到右依次为
- 项目cmdb tag
- Jira Key/Kaptain projectId
- 分配人
- 报告人
- 定时任务设置
- 项目创建人
- 创建时间
- 下次走查触发时间
- 操作:包括执行(手工)、编辑、禁用/启用、删除,进行了权限控制(非走查项目创建者禁止操作)
消息推送
在走查项目设置企信机器人链接的情况下,走查完成后除了上报问题还会向机器人所在企信群发送消息通知;
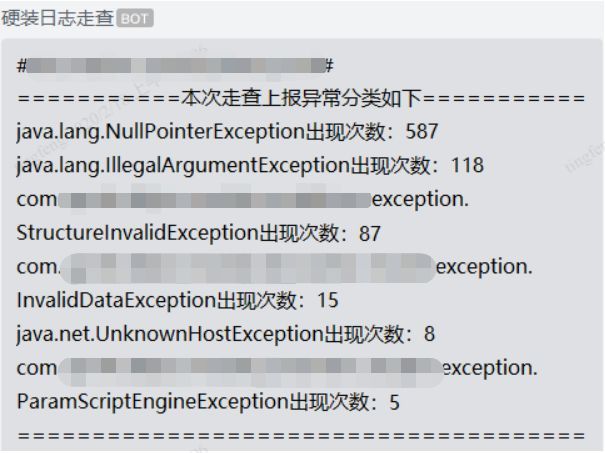
消息内容
- 异常发生的具体服务+环境
- 每种异常数量>=3的ExceptionType及数量
消息展示
实践收益
以硬装参数化业务线为例:2019H2线下bug数384,日志走查发现并且已修复bug数54,占比14%;
除了业务问题以外还包括性能、脏数据、兼容性、缓存、序列化、未评估出的依赖、权限校验、状态码设置不合理、服务间调用超时等问题;
以一个问题从发现到记录耗时10分钟保守估计,节省了540分钟时间;部分问题列举如下:
业务问题
数据问题
状态码设置不合理

性能问题

超时问题
缓存问题

依赖评估问题

兼容性问题

权限问题

数据库问题

使用感受
- 无需每天再花时间去搜索异常日志,配合定时任务后更多的精力可以放在走查上报了什么问题、问题的原因与解决方式
- 前期可以将上报问题分配给自己来观察项目中是否需要大量的排除某些异常及问题,这个过程也是提升自己排查和分析能力的过程
- 配合定时任务灰度期间更快的发现上报问题并通知到群,让灰发更安心,硬装组使用此方式实践收益较多
- 稳定性提升的一种手段与方式,从历史记录问题分析,除业务问题外,潜在的性能、缓存、兼容性、依赖、权限、脏数据、超时等问题可以通过这种方式得以暴露
优化点
正在进行中的优化及后期计划优化包括:
- 增加对Kaptain支持,用户根据项目需要选择提交到Jira或者Kaptain
- 已落库异常归类二次分析,进行异常趋势的可视化追踪
- 产品的易用性建设
关注我们
酷家乐质量效能团队热衷于技术的成长和分享,几乎每个月都会举办技术分享活动(海星日),每半年举办一次技术专题竞赛分享(火星日),并将优秀内容写成技术文章。
我们尽可能保障分享到社区的内容,是我们用心编写、精心挑选的优质文章。如果您想更全面地阅读我们的文章,请您关注我们的微信公众号"酷家乐技术质量"。
