
酷家乐多语言技术架构

简单描述就是前端代码和后端代码在不同语种情况下,都是通过获取CDN中存储的各类多语言的信息,也就是创建多语言词条会返回一个唯一KEY,这个KEY对应的是各类语种的value,但是由于酷家乐双发到国际化之后,是同一份代码,会导致有一部分中文忘记用词条了,或者后端服务没有用,就导致中文对外漏出。针对于目前国际化多语言的情况,测试团队现有的语言检测只有【接口扫描】
接口扫描流程图
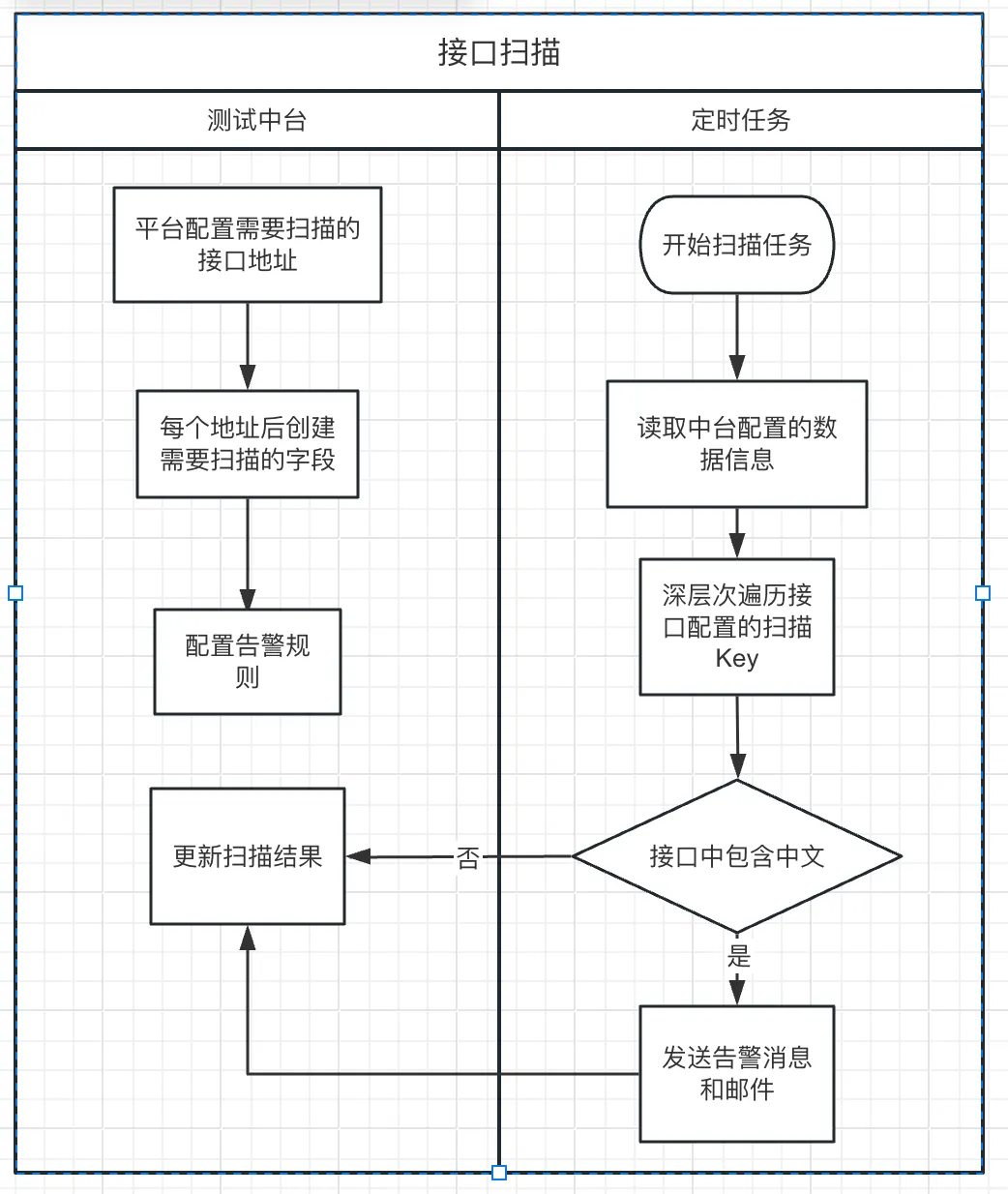
即根据接口中返回是否为中英文以此作为判断,来校验是否包含中文,但是前端的内容大部分文本非接口返回,为词条中获取,以此为背景结合UI自动化对前端文本做中文扫描校验。以下图片中展示的是,22年至23年期间,出现的中文问题,几乎每个月都能出现一次,可以看出国际化的中文问题较多。
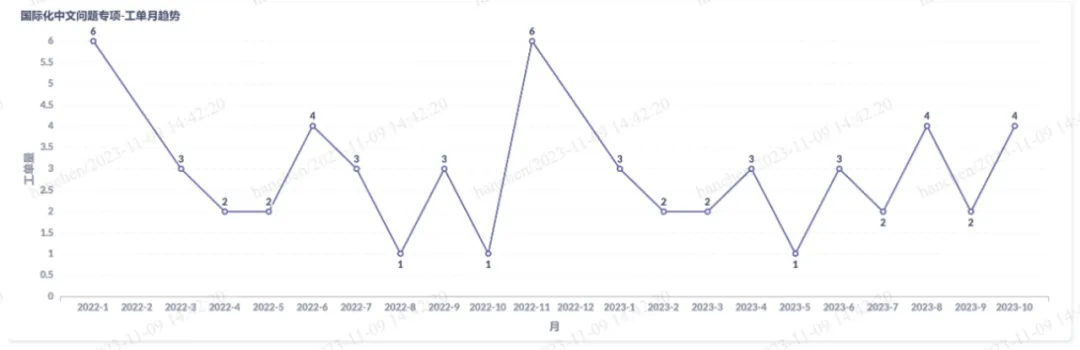
为了解决这类高频问题,思考通过别的途径解决该问题。
价值
现状:
- 接口扫描所断言的中文信息不全
- 扫描缺少交互性:各个业务场景所用到的中文,会根据入参变化。目前是固定参数来获取固定返回
- 扫描覆盖度不高,不能完全覆盖各词条
解决的问题:
- 全HTML文本:扫描并做检验
- 根据用户操作习惯,所见即所得。将用户操作路径中携带交互所产生的文案,获取并检验
- 校验接口扫描不能透出的各类词条文案
具体实施方案
流程图:
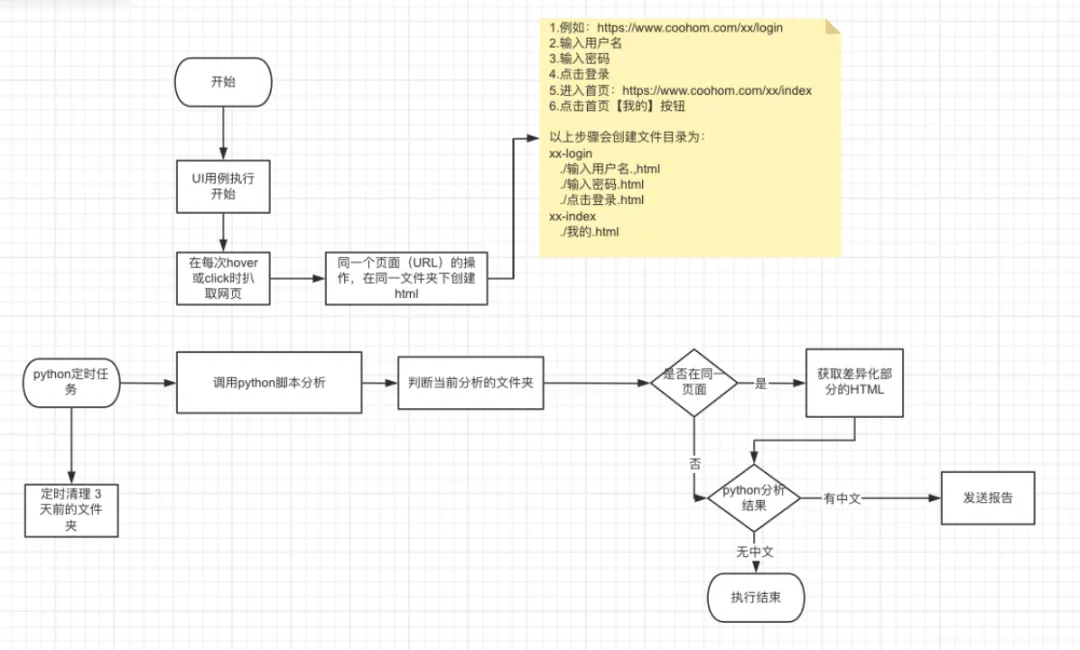
具体效果
- 我们假如当前页面是英文的情况下,出现了漏翻译的情况,如下图展示,几乎整片网页全是中文,具体如下
- 页面效果:
我们想要的效果是将页面中的文字全部提取出来,然后对中英文做区分。
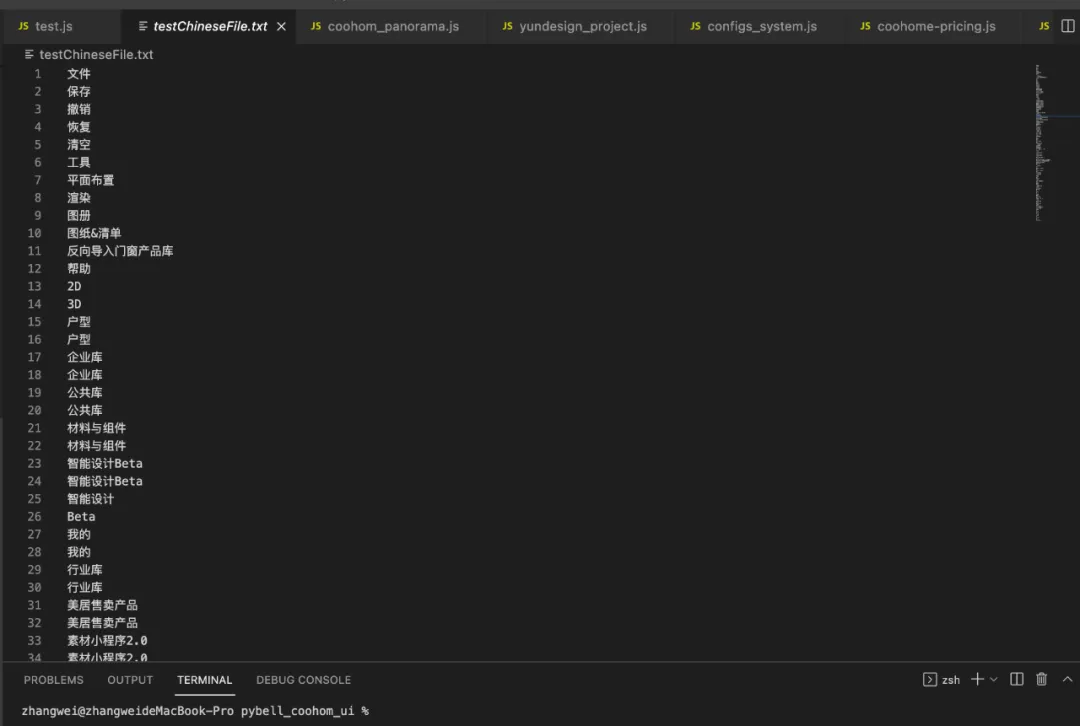
实现过程:以puppeteer为例,页面每次点击或者对于页面做hover的时候,页面元素都会产生相应变化,那么在页面产生变化的时候,将整个HTML DOM元素获取下来。则会得到一个动态情况下,网页文本情况,具体实现细节:我们获取HTML网页的时候,需要确保整个网页完全加载完了,这里采用【window.performance.timing.loadEventEnd -window.performance.timing.navigationStart】,windows下的方法,可以获取到整个浏览器完全加载完成的时间,减去网页刚开始加载的时间,获取到一个时间差,如果大于0则认为当前网页已经完全加载完。
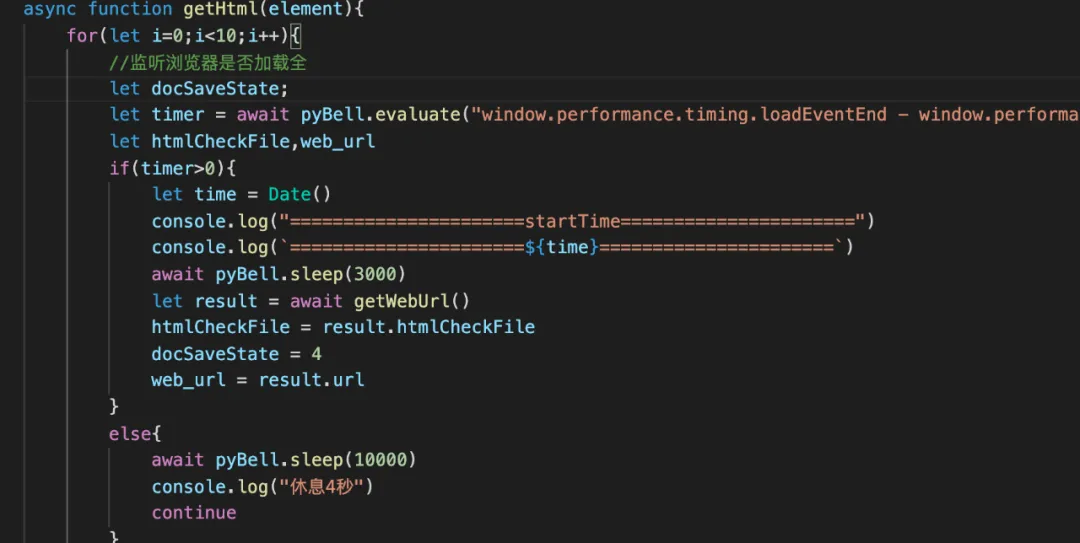
然后通过:document.documentElement.innerHTML。方法获取整个网页的内容,最终存储在本地。
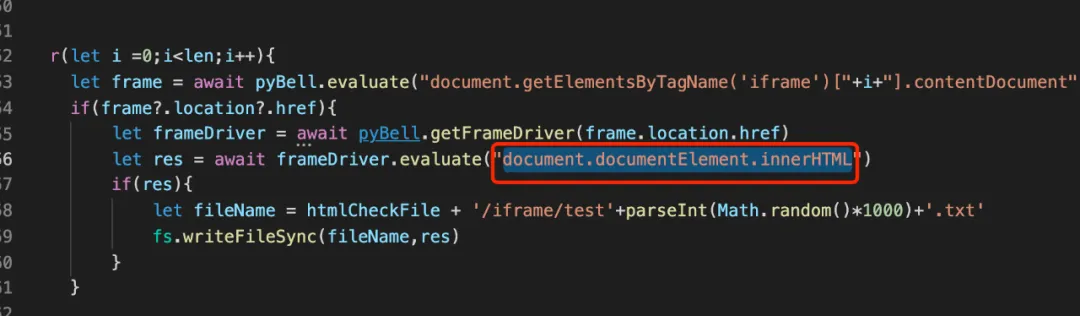
通过传入的元素,对getHtml再做一层封装,hover也类似,最终hover和click都具备网页爬取的能力。
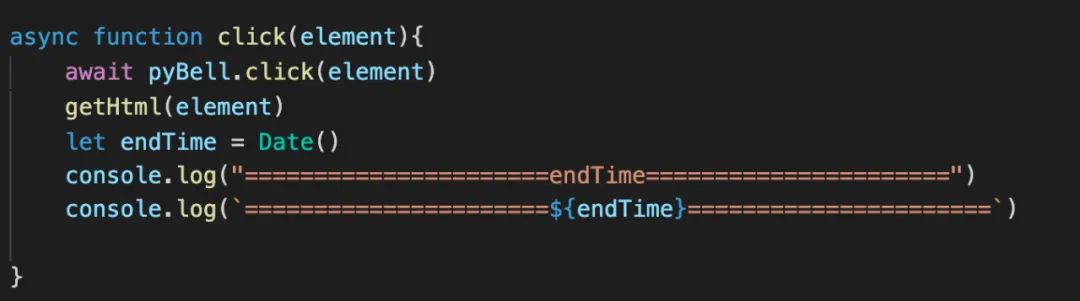
分析HTML的逻辑是通过beautifulSoap的python标准库来进行扫描,通过将HTML内的中文提取出来,然后通过中文的Unicode的编码区间,来判断当前页面中是否有英文。
最终通过部署在远程机器的python脚本每天分析一次,将测试结果以邮件的形式推送出来。

最终报告:
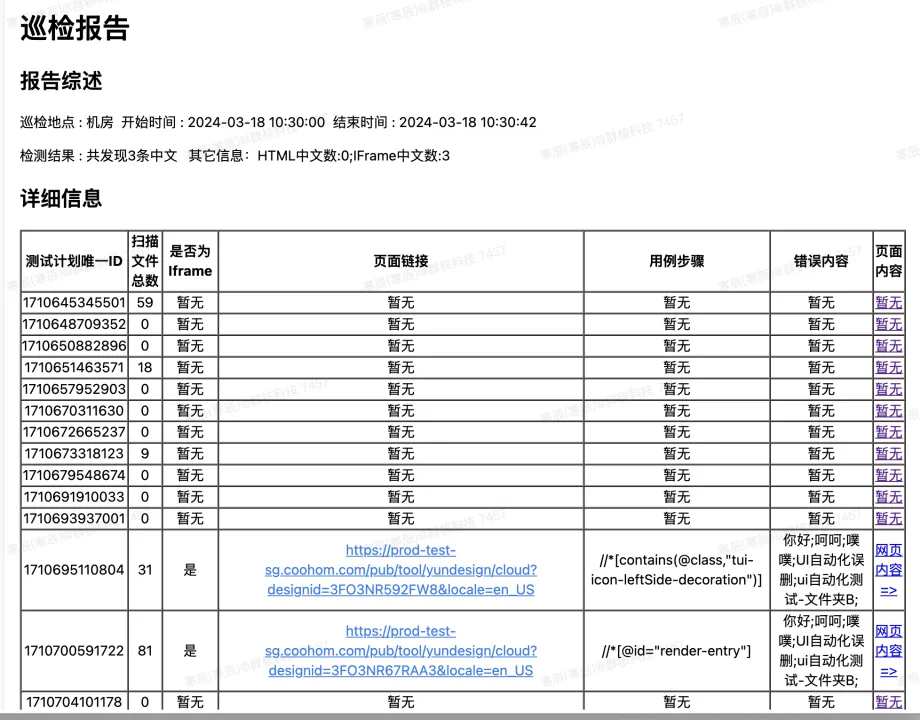
最终得到的结果:截止2023-11-9 为起始时间至今( 2024-2-20 ) 共扫描103次,非测试数据中文数:10个总共发现中文数:52次网络原因导致错误数:4次测试数据导致中文数:46次
后续的展望:
- 和现有的平台做聚合网页巡检平台做配合,这样就可以脱离UI自动化代码,不需要人为去维护,只需要配置网页的URL自动去扒取网页中的文本,具体做法
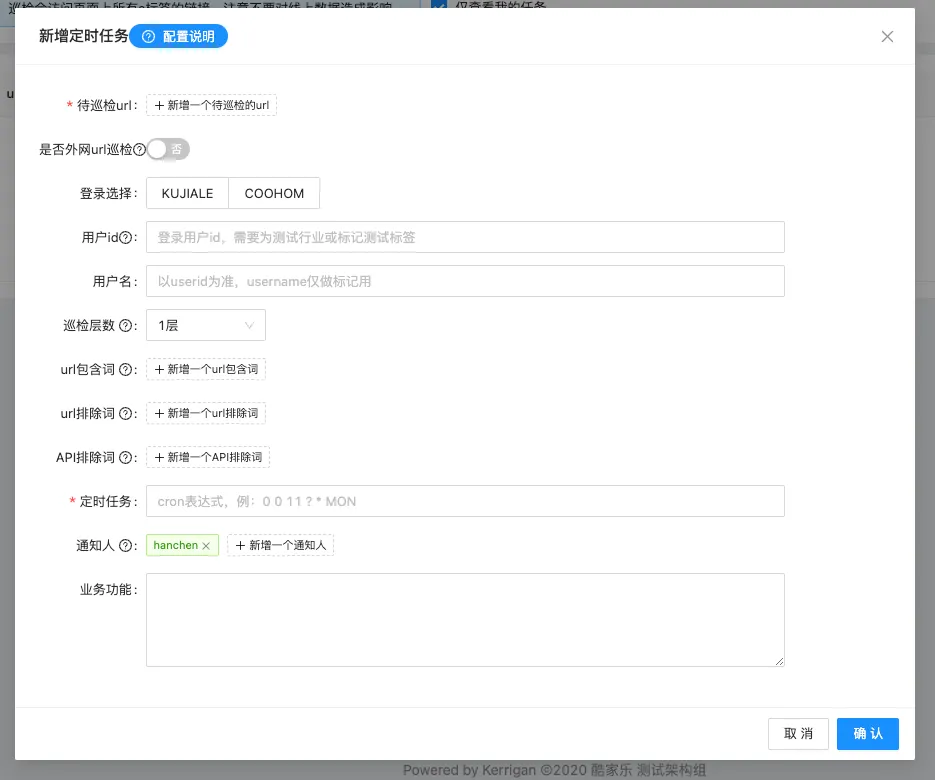
我们网页巡检已经具备的能力:
从图中可以看到,当前网页如果存在A标签的话,会根据所设定的巡检层数来进行递归,例如当前巡检层数设置为3,网页有5个A标签,此时会将5个页面全部扫出来,5个网页继续打开,直到递归到第三层就算结束,但是由于此平台检测的能力只有3个
- console报错:浏览器F12控制台看到的Error类型内容
- 接口报错:状态码非200和非304的接口,响应内容中c!=0的接口
- 配置错误:外网网站配置了内网域名(需要开启“是否外网url巡检”开关)
2. AI扫描
我们目前只能做最基础的中文文本检测,但是我们是否能根据大模型的能力来进行扫描,目前调研的结果是可以的,以市面上常见的chatgpt就能将翻译后的英文,语义、错别字、等等都能一一扫描出,我们可以将python脚本提取出来的文本,传递给chatgpt从而达到,语言是否有中文,以及语言是否翻译准确了。
总结
多语言的要想做到精准验证接入AI的辅助必然是一个趋势,不然扫描出来的文本无法得到准确性,以及正确性的验证。团队内其他重复测试场景且现阶段无法做到自动化的还有很多,例如白标(简单理解白标的含义,各商家的logo是否包含特定酷家乐的标识)这类图标有各类长短分辨率大小不一的图片,要做到批量验证,也需要借助AI的能力,后续我们将提供更多的AI结合自动化的探索!
{kind=link}