
一、产生背景
众所周知,酷家乐是国内首屈一指的大家居全案设计平台及生态解决方案提供商,致力于为数字化升级提供一站式的解决方案,客户多是以中文为主的公司。虽然有英文版,但是实际使用上还是会遇到很多问题:
- 语言问题:酷家乐以中文为主,英文版支持不够完整,且无其他语言。
- 部署问题:酷家乐没有全球部署, 在海外服务的加载和访问速度会受限制
- 模型问题,酷家乐的模型库模型受众主要是国内的,非海外本地审美。
由此诞生了海外版本--coohom。
目前coohom线上共支持7种语言,受众最大的是英语客户,并且他们也最接受不了中文的存在。coohom的功能基本上都是从酷家乐延伸的,有些模块甚至是双发的(酷家乐发布新版,coohom自动更新),这就导致酷家乐一旦新增或者修改某个功能,都有可能影响到coohom,导致在线上出现中文。
因此存在以下中文的痛点:
- coohom对接用户线较多,云图,定制,硬装,快搭等,这些细节问题采用人肉测试,效率太低,需要有自动化的检测工具辅助测试;
- 工具每周发布回归,周期短,迭代快,工作量大,上线时间紧,测试资源有限,一些细小的问题(如商品类目,名称等)不会一个个去看,因此急需一种自动化工具帮助回归检测;
- 由于coohom现在主要语言是英语,而且出问题比较多的是英语中混有中文,因此先检测英文环境下是否含有中文的问题。若检测有效,再推广到其它语言。
- coohom目前没有独立的模型库/素材库,跟酷家乐使用一套数据,且模型以及素材都是运营手动添加,不会过多考虑多语言,因此时常有模型/素材未翻译的问题。
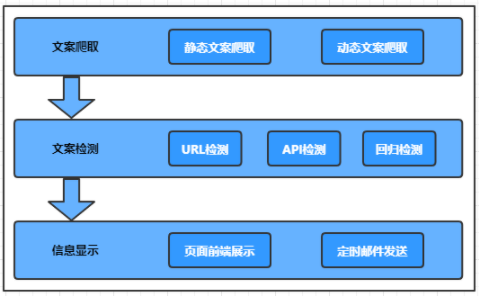
二、实现方案
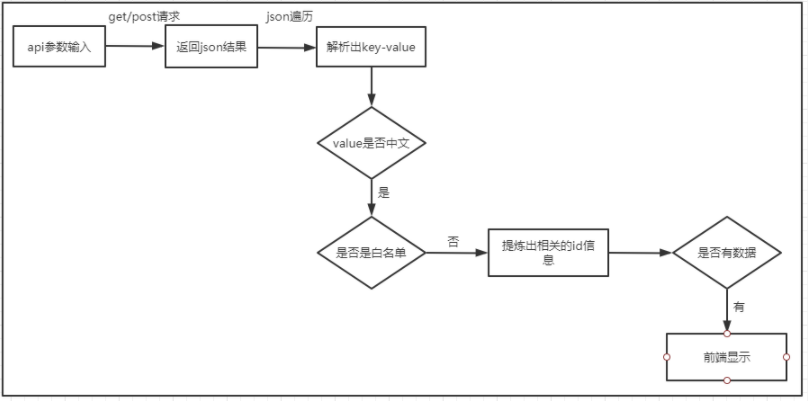
多语言检测方案主要分为三个部分:爬取文案、检测文案以及文案信息展示。
第一步:文案爬取分为静态网页文案爬取和动态网页文案爬取,静态文案可以直接通过html获取,获取比较容易,但是动态文案就比较麻烦了,虽然在浏览器中可以看到,但是在html源码中却发现不了,调研选择了两种方案,分别是“使用自动化测试工具对网页进行模拟访问”以及“直接Ajax请求,得到返回的json数据”,通过分析对比,采用模拟ajax的方法去获取动态文案。
第二步:由于前期只是检测英文中是否有中文存在,所以文案检测部分就相对简单一点,可以通过中文的unicode编码范围进行检测。
第三步:文案信息展示,主要是定时检测发送邮件。
三、文案爬取
3.1 静态文案爬取
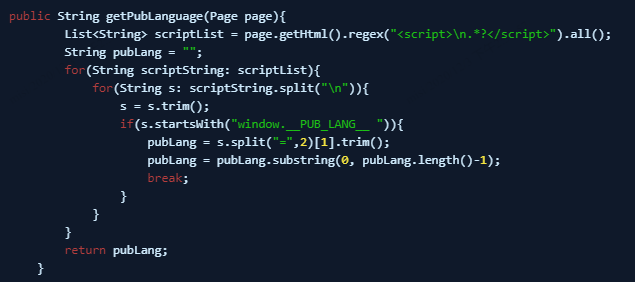
前端代码直接展示的文案,包括鼠标hover的文案、弹窗的文案、按钮的文案可以直接通过html源码中的”window.__PUB_LANG__”关键字获得
以工具为例,红框处的文案为静态文案
可以直接通过”window.__PUB_LANG__”获取各个插件的静态文案,以“yundesign_kaf_plugin”为例,只需要看每个key对应的值是否为中文

实际的获取方法如下:
3.2 动态文案获取
目前抓取动态文案主要有三种方法:
1. 使用自动化测试工具对网页进行模拟访问:
在抓取阶段,在爬虫中内置一个浏览器内核,执行js渲染页面后,再抓取。常用的工具为Selenium、HtmlUnit、PhantomJs、Puppeteer等。如下图所示,通过webdriver模拟登陆是可以拿到对应的文案的。

该方案需要知道控件的xpath,模拟手工操作,由于渲染的时间无法预估,所以存在一定的效率问题,同时也不是那么稳定。好处是编写规则同静态页面一样。该方法适用于一次性或者小规模的需求。
2. 直接Ajax请求,得到返回的json数据(有些数据是加密过的,需要解密):
因为js渲染页面的数据也是从后端拿到,而且基本上都是AJAX获取,所以分析AJAX请求,直接拿到对应的数据,也是比较可行的做法。

相对于页面样式,这种接口变化可能性更小。缺点就是要找出所有的接口,并进行模拟,是一个相对困难的过程,也需要相对多的分析经验。比较适用于长期性的、大规模的需求。
模拟访问法和ajax请求法各有优缺点,由于前者需要依据xpath,根据coohom ui自动化的经验,各个控件的xpath会经常变化,需要定期去维护;而且如果要爬取整个网站,如果去整理每一步的xpath,将会是一个很庞大的工程;
模拟ajax请求法虽然要整理所有的接口,但是目前已有接口整理文档(参考cemon巡检),而且接口相对于xpath来说,不仅数量小的多,而且变化的可能性也更小,更容易维护。
因此,本次采用模拟ajax的方法去获取动态文案。
3. Ajax请求法
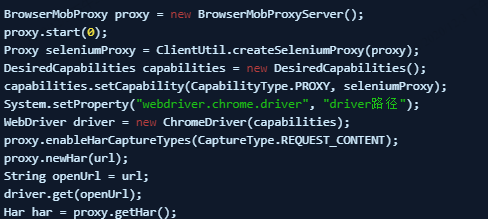
现采用开源的工具包selenium+browsermob-proxy模拟浏览器访问,来自动获取接口信息。
browsermob-proxy是基于Java的代理服务,它的具体流程有点类似与Fidder或Charles。即开启一个端口并作为一个标准代理存在,当HTTP客户端(浏览器等)设置了这个代理,则抓取并有能力修改所有的请求细节并获取返回内容。调用方式如下:
3.3 异常文案获取
目前异常文案是根据unicode编码来获取的,目前只是考虑中文,中文的编码范围是 [\u4e00-\u9fa5](不考虑中文标点之类的)
调用方法如下:

四、检测方式
目前前端主要有3种检测方式,分别是URL检测,API检测以及回归检测
4.1 URL检测
该检测方式主要是根据输入的URL爬取静态文案,使用Ajax请求法爬取动态接口文案,最后根据unicode编码抓取出匹配的异常文案(中文)并在前端展示。
适用范围:coohom SAAS后台的所有链接,不适用于工具


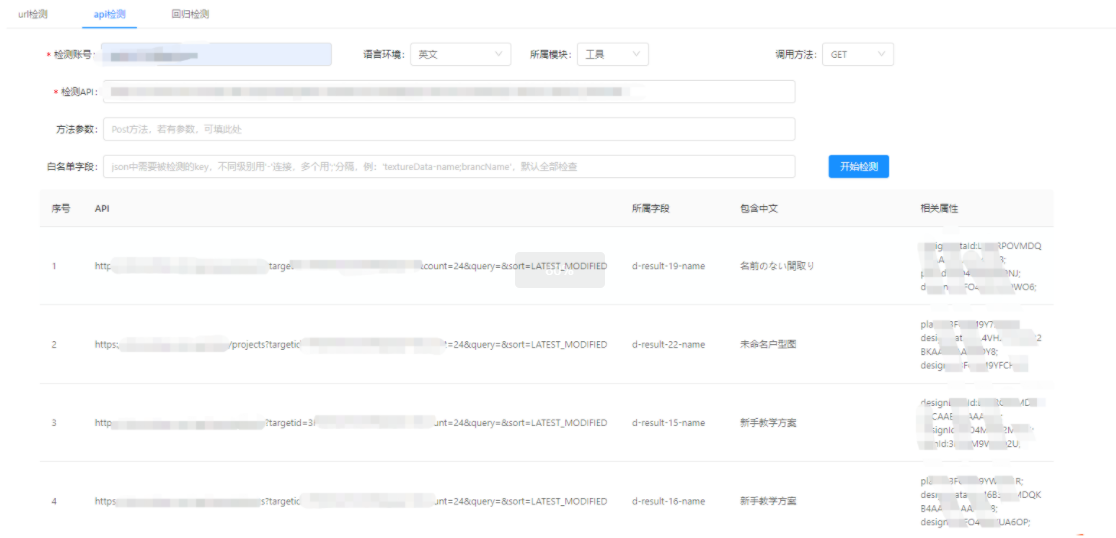
4.2 API检测
该检测方式主要是根据输入的接口爬取接口返回文案,最后根据unicode编码抓取出匹配的异常文案(中文)并在前端展示。
适用范围:目前只支持GET、POST接口,包括coohom SAAS后台以及工具
为了辅助定位问题,会把异常文案的接口,所在字段以及一些相关的id属性都会打印出来
4.3 回归检测
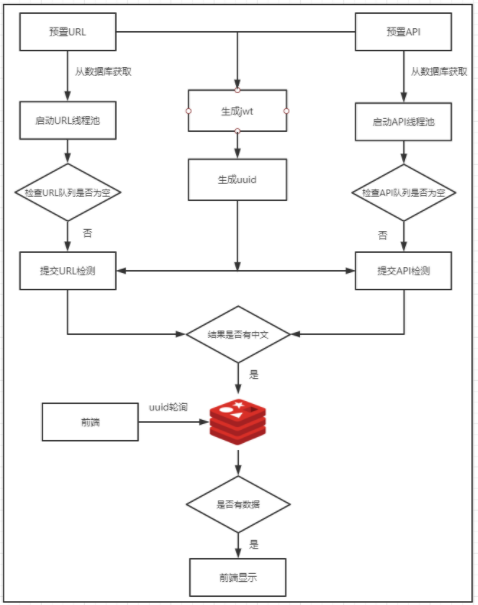
先预置url以及接口信息在数据表中,检测时根据所选的模块分别调用去爬取数据检测
saas后台主要是url信息,检测方式按照4.1,其余都是接口信息,检测方式按照4.2,也可以选择全量检测所有,回归检测时传入的url和接口太多,一次性跑完需要时间较长,会导致前端超时或者一直处于loading状态,显示很不友好,现采用多线程+redis存储机制解决。

五、信息显示
第4节中已经包含了前端页面的展示部分,但前端页面的展示每次都需要人为去前端操作才能获取,想要有任务可以按时间每天自动去检测并且发送邮件,因此开发了定时自动检测功能。
1.coohom saas后台自行维护,文案相关改动较小,属于可控范围
2.工具是每周集成kujiale的,并且运营会上新一些新的模型以及素材,会导致模型名称以及品牌等为中文的情况
基于以上,自动检测拿的是回归检测中的工具的api接口的部分,检测内容以及检测流程在第二部分已经具体描写了,这里主要是定时检测并发邮件
定时任务比较简单,就是基于注解@Scheduled,使用Cron表达式来创建定时任务。
邮件内容采用以下方式:
用freemarker模版来确定邮件格式
具体框架图如下:
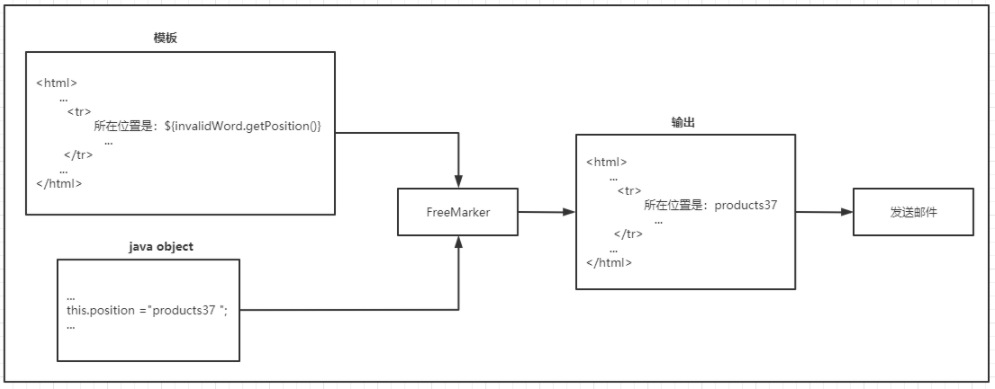
3.邮件成品

六、小结
成果:
1. 对于新加的页面,输入url,一键检测中文,例如新增的快搭,定制商家后台等迁移过来的功能。
2. 对于模型/素材数据,检测到中文,并获取相应的路径以及id,以方便运营修改。
3. 覆盖saas后台以及工具端,使用灵活,既能检测页面也能检测接口。
4.回归检测每日定时运行,无需手动执行,省时省力
展望:
1. 由于回归检测目前接口都是手动预先填的,需要探索自动获取接口的方法。
2. 模型/素材名称等中文问题,支持自动翻译修复,解放运营。
3. 对KA客户使用语言,例如韩语,增加检测项。
{kind=link}