
涉及到网络层面的问题一般都比较复杂,场景多,定位难,成为了大多数开发的噩梦,应该是最复杂的了。下面通过一个实际的例子来阐述遇到了要怎么办。
现象
部署在矩阵机房的较多应用频繁报出toad异常,Encounter unknown error when watch config change, sleep for 10s, cause java.net.SocketTimeoutException: Read timed out.
ps:Toad(蟾) 是一个功能全面的应用配置中心,能够集中化管理应用不同环境的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
排查思路
第一反应是接口是不是返回的数据量太大,导致读超时,排查发现数据量很小,却SocketTimeoutException,首先就排除了业务接口返回数据量过大的原因。
那会不会是哪个链路拖慢了整个请求呢?
接着发现日志中有好多关于该接口的慢sql(后面翻代码才看到是异步入库处理的--),猜想是不是矩阵机房到阿里云rds的网络不太通畅导致的。后面通过运维大佬的建议,在报错的业务机器上 tcpping toad,以及 tcpping toad到阿里云rds的网络,发现网络是非常通畅的,所以,网络不通畅导致SocketTimeoutException,排除。

网络及业务上的原因都排除了,那么是不是底层有一些限制,连接数限制?
矩阵机房的toad是部署在k8s上的,运维大佬反馈 ingress没有做限制,那么问题来了,SocketTimeoutException应该是更底层的问题了。
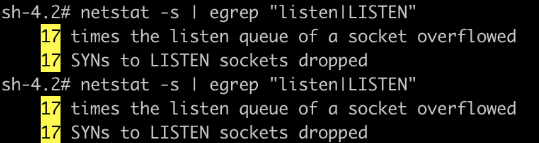
经过排查,发现socket overflowed了。
命令:
netstat -s | egrep "listen|LISTEN"
ss -lnt

如上图所示,overflowed表示全连接队列溢出的次数,sockets dropped表示半连接队列溢出的次数。
查看pod somaxconn 发现是默认的128,意味着只能有128个建立连接,后续进来的连接都得排队。自此问题找到:默认的somaxconn不够用。

ps:somaxconn相关概念请看下文总结。
解决
在 k8s deployment文件container同级增加如下配置,
"securityContext": {
"sysctls": [
{
"name": "net.core.somaxconn",
"value": "1024"
}
]
}
修改该配置需要重启操作,将somaxconn改成1024后,问题解决。
总结
网络层面的问题在此做个总结,从tcp层、应用层以及工具的使用等方面进行阐述。
超时
超时错误大部分处在应用层面,所以这块着重理解概念。超时大体可以分为连接超时和读写超时,某些使用连接池的客户端框架还会存在获取连接超时和空闲连接清理超时。
- 读写超时。readTimeout/writeTimeout,有些框架叫做so_timeout或者socketTimeout,均指的是数据读写超时。注意这边的超时大部分是指逻辑上的超时。soa的超时指的也是读超时。读写超时一般都只针对客户端设置。
- 连接超时。connectionTimeout,客户端通常指与服务端建立连接的最大时间。服务端这边connectionTimeout就有些五花八门了,jetty中表示空闲连接清理时间,tomcat则表示连接维持的最大时间。
- 其他。包括连接获取超时connectionAcquireTimeout和空闲连接清理超时idleConnectionTimeout。多用于使用连接池或队列的客户端或服务端框架。
我们在设置各种超时时间中,需要确认的是尽量保持客户端的超时小于服务端的超时,以保证连接正常结束。
在实际开发中,我们关心最多的应该是接口的读写超时了。
如何设置合理的接口超时是一个问题。如果接口超时设置的过长,那么有可能会过多地占用服务端的tcp连接。而如果接口设置的过短,那么接口超时就会非常频繁。
服务端接口明明rt降低,但客户端仍然一直超时又是另一个问题。这个问题其实很简单,客户端到服务端的链路包括网络传输、排队以及服务处理等,每一个环节都可能是耗时的原因。
TCP队列溢出
tcp队列溢出是个相对底层的错误,它可能会造成超时、rst等更表层的错误。因此错误也更隐蔽,所以我们单独说一说。
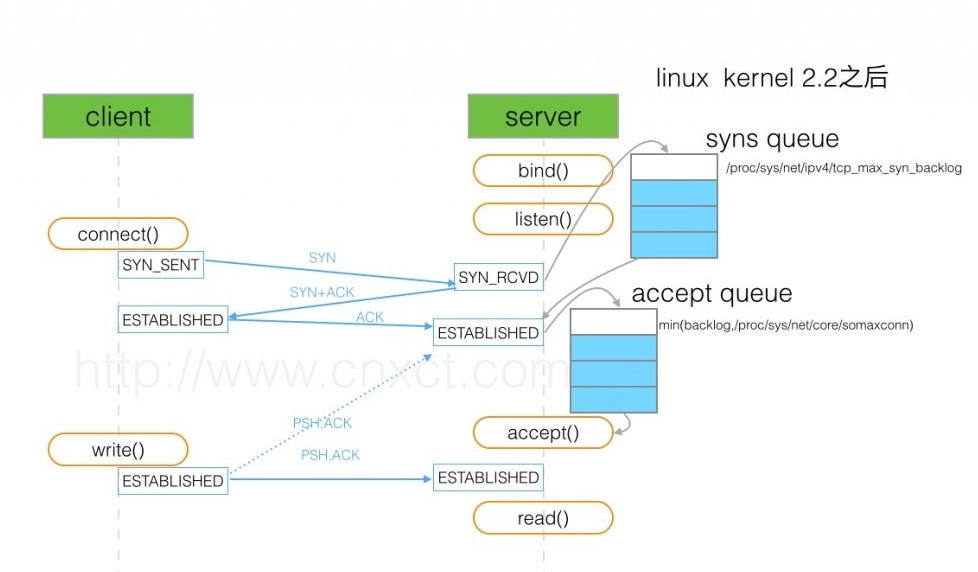
剽一张图。如上图所示,这里有两个队列:syns queue(半连接队列)、accept queue(全连接队列)。三次握手,在server收到client的syn后,把消息放到syns queue,回复syn+ack给client,server收到client的ack,如果这时accept queue没满,那就从syns queue拿出暂存的信息放入accept queue中,否则按tcp_abort_on_overflow指示的执行。
tcp_abort_on_overflow 0表示如果三次握手第三步的时候accept queue满了那么server扔掉client发过来的ack。tcp_abort_on_overflow 1则表示第三步的时候如果全连接队列满了,server发送一个rst包给client,表示废掉这个握手过程和这个连接,意味着日志里可能会有很多connection reset / connection reset by peer。
那么在实际开发中,我们怎么能快速定位到tcp队列溢出呢?
netstat命令,执行
netstat -s | egrep "listen|LISTEN"

如上图所示,overflowed表示全连接队列溢出的次数,sockets dropped表示半连接队列溢出的次数。
ss命令,执行
ss -lnt

上面看到Send-Q 表示第三列的listen端口上的全连接队列最大为5,第一列Recv-Q为全连接队列当前使用了多少。
接着我们看看怎么设置全连接、半连接队列大小吧:
全连接队列的大小取决于min(backlog, somaxconn)。backlog是在socket创建的时候传入的,somaxconn是一个os级别的系统参数。而半连接队列的大小取决于max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog)。
在日常开发中,我们往往使用servlet容器作为服务端,所以我们有时候也需要关注容器的连接队列大小。在tomcat中backlog叫做acceptCount,在jetty里面则是acceptQueueSize。
RST异常
RST包表示连接重置,用于关闭一些无用的连接,通常表示异常关闭,区别于四次挥手。
在实际开发中,我们往往会看到connection reset / connection reset by peer错误,这种情况就是RST包导致的。
端口不存在
如果像不存在的端口发出建立连接SYN请求,那么服务端发现自己并没有这个端口则会直接返回一个RST报文,用于中断连接。
主动代替FIN终止连接
一般来说,正常的连接关闭都是需要通过FIN报文实现,然而我们也可以用RST报文来代替FIN,表示直接终止连接。实际开发中,可设置SO_LINGER数值来控制,这种往往是故意的,来跳过TIMED_WAIT,提供交互效率,不闲就慎用。
客户端或服务端有一边发生了异常,该方向对端发送RST以告知关闭连接
我们上面讲的tcp队列溢出发送RST包其实也是属于这一种。这种往往是由于某些原因,一方无法再能正常处理请求连接了(比如程序崩了,队列满了),从而告知另一方关闭连接。
接收到的TCP报文不在已知的TCP连接内
比如,一方机器由于网络实在太差TCP报文失踪了,另一方关闭了该连接,然后过了许久收到了之前失踪的TCP报文,但由于对应的TCP连接已不存在,那么会直接发一个RST包以便开启新的连接。
一方长期未收到另一方的确认报文,在一定时间或重传次数后发出RST报文
这种大多也和网络环境相关了,网络环境差可能会导致更多的RST报文。
之前说过RST报文多会导致程序报错,在一个已关闭的连接上读操作会报connection reset,而在一个已关闭的连接上写操作则会报connection reset by peer。通常我们可能还会看到broken pipe错误,这是管道层面的错误,表示对已关闭的管道进行读写,往往是在收到RST,报出connection reset错后继续读写数据报的错,这个在glibc源码注释中也有介绍。
我们在排查故障时候怎么确定有RST包的存在呢?当然是使用tcpdump命令进行抓包,并使用wireshark进行简单分析了。tcpdump -i en0 tcp -w xxx.cap,en0表示监听的网卡。

接下来我们通过wireshark打开抓到的包,可能就能看到如下图所示,红色的就表示RST包了。

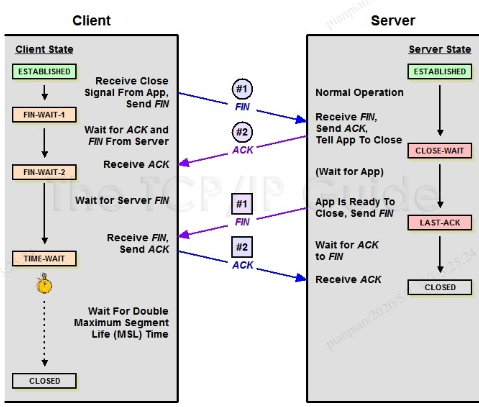
TIME_WAIT和CLOSE_WAIT
TIME_WAIT和CLOSE_WAIT是啥意思相信大家都知道,这里放一张图来供回忆。
在线上时,我们可以直接用命令netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'来查看time-wait和close_wait的数量
用ss命令会更快ss -ant | awk '{++S[$1]} END {for(a in S) print a, S[a]}'

TIME_WAIT
time_wait的存在一是为了丢失的数据包被后面连接复用,二是为了在2MSL的时间范围内正常关闭连接。它的存在其实会大大减少RST包的出现。
过多的time_wait在短连接频繁的场景比较容易出现。这种情况可以在服务端做一些内核参数调优:
#表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭net.ipv4.tcp_tw_reuse = 1#表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭net.ipv4.tcp_tw_recycle = 1
当然我们不要忘记在NAT环境下因为时间戳错乱导致数据包被拒绝的坑了,另外的办法就是改小tcp_max_tw_buckets,超过这个数的time_wait都会被干掉,不过这也会导致报time wait bucket table overflow的错。
CLOSE_WAIT
close_wait往往都是因为应用程序写的有问题,没有在ACK后再次发起FIN报文。close_wait出现的概率甚至比time_wait要更高,后果也更严重。往往是由于某个地方阻塞住了,没有正常关闭连接,从而渐渐地消耗完所有的线程。
想要定位这类问题,最好是通过jstack来分析线程堆栈来排查问题,具体可参考上述章节。这里仅举一个例子。
例子:开发同学说应用上线后CLOSE_WAIT就一直增多,直到挂掉为止,jstack后找到比较可疑的堆栈是大部分线程都卡在了countdownlatch.await方法,找开发同学了解后得知使用了多线程但是确没有catch异常,修改后发现异常仅仅是最简单的升级sdk后常出现的class not found。
Cover Photo by Taylor Vick on Unsplash
关注我们
酷家乐质量效能团队热衷于技术的成长和分享,几乎每个月都会举办技术分享活动(海星日),每半年举办一次技术专题竞赛分享(火星日),并将优秀内容写成技术文章。
我们尽可能保障分享到社区的内容,是我们用心编写、精心挑选的优质文章。如果您想更全面地阅读我们的文章,请您关注我们的微信公众号"酷家乐技术质量"。

{kind=link}