
一、背景
进行性能测试时,常用的一些技术指标能够发现大部分常见问题,但是有一些不够明显的性能异常可能需要做更深入的分析。本文详细记录了一些性能场景下相关数据分析方法及思路,对不够明显的数据变动做深入性能分析,从而发现性能问题,希望能够对后续的性能测试提供帮助。
二、定位工具图解
2.1 CPU
CPU:当收到CPU使用率过高告警时,从监控系统中直接查询到,导致 CPU 使用率过高的进程;然后再登录到进程所在的 Linux 服务器中,分析该进程的行为。你可以使用 strace,查看进程的系统调用汇总;也可以使用 perf 等工具,找出进程的热点函数;甚至还可以使用动态追踪的方法,来观察进程的当前执行过程,直到确定瓶颈的根源。
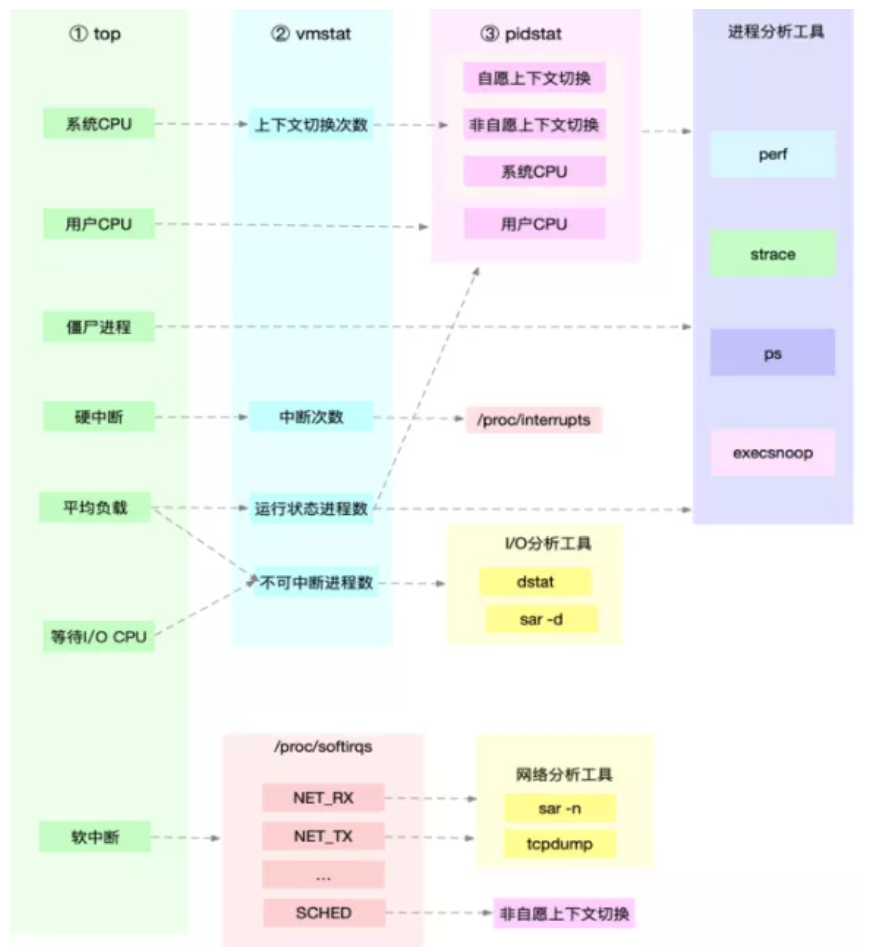
2.2 内存
内存:当收到内存不足的告警时,首先可以从监控系统中,找出占用内存最多的几个进程。
然后再根据这些进程的内存占用历史,观察是否存在内存泄漏问题。
确定出最可疑的进程后,再登录到进程所在的服务器中,分析该进程的内存空间或者内存分配,最后弄清楚进程为什么会占用大量内存。
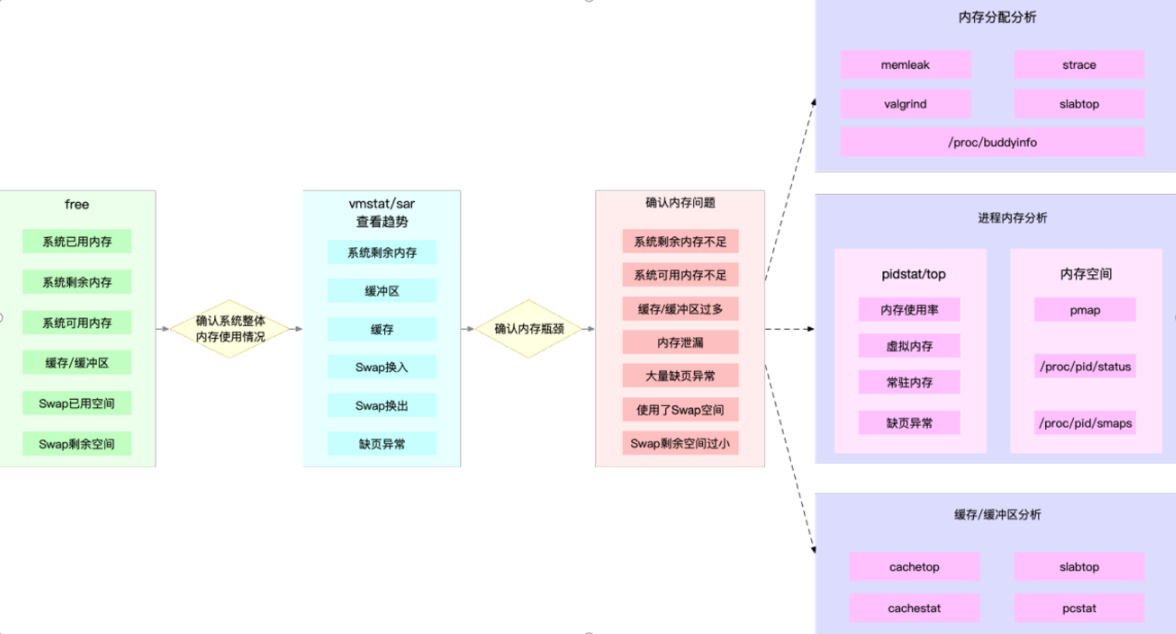
2.3 磁盘
磁盘:当使用 iostat发现磁盘 I/O 存在性能瓶颈(比如 I/O 使用率过高、响应时间过长或者等待队列长度突然增大等)后,可以再通过 pidstat、 vmstat 等,确认 I/O的来源。
接着,再根据来源的不同,进一步分析文件系统和磁盘的使用率、缓存以及进程的 I/O等,从而确定 I/O 问题原因
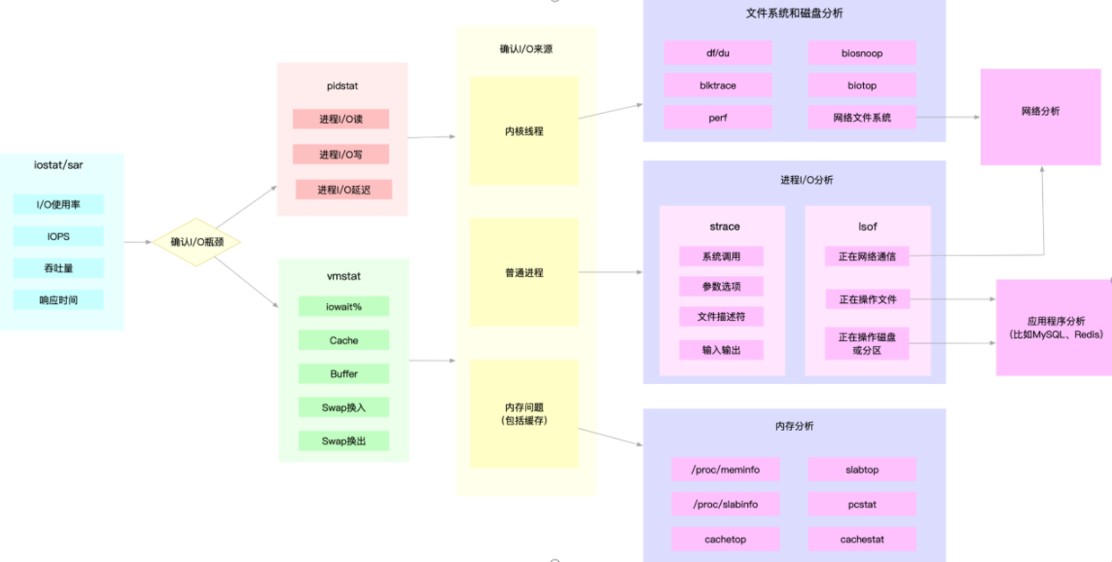
2.4 网络
网络:分析网络的性能,要从这几个协议层入手,通过使用率、饱和度以及错误数这几类性能指标,观察是否存在性能问题。比如 :
在链路层,可以从网络接口的吞吐量、丢包、错误以及软中断和网络功能卸载等角度分析;
在网络层,可以从路由、分片、叠加网络等角度进行分析;
在传输层,可以从 TCP、UDP 的协议原理出发,从连接数、吞吐量、延迟、重传等角度进行分析;
在应用层,可以从应用层协议(如 HTTP 和 DNS)、请求数(QPS)、套接字缓存等角度进行分析。
同前面几种资源类似,网络的性能指标也都来源于内核,包括 /proc 文件系统(如/proc/net)、网络接口以及 conntrack 等内核模块。
这些指标同样需要被监控系统监控。
这样,当你收到网络告警时,就可以从监控系统中,查询这些协议层的各项性能指标,从而更快定位出性能问题。
比如,当你收到网络不通的告警时,就可以从监控系统中,查找各个协议层的丢包指标,确认丢包所在的协议层。
然后,从监控系统的数据中,确认网络带宽、缓冲区、连接跟踪数等软硬件,是否存在性能瓶颈。
最后,再登录到发生问题的 Linux 服务器中,借助 netstat、tcpdump、bcc 等工具,分析网络的收发数据,并且结合内核中的网络选项以及 TCP 等网络协议的原理,找出问题原因。

三、深入数据分析案例
不同的业务会对应不同的场景,产生问题的原因也各不相同,下面是实际压测过程中发现的一些深入的性能问题以及分析定位过程,有一定的代表性和参考意义
3.1 数据爬坡问题及分析
背景:定制业务需要将核心服务pmbs收拢接入中台,为了验证接入中台后的性能,需要做接入前后的性能对比,在性能不变坏的情况下方可平滑接入
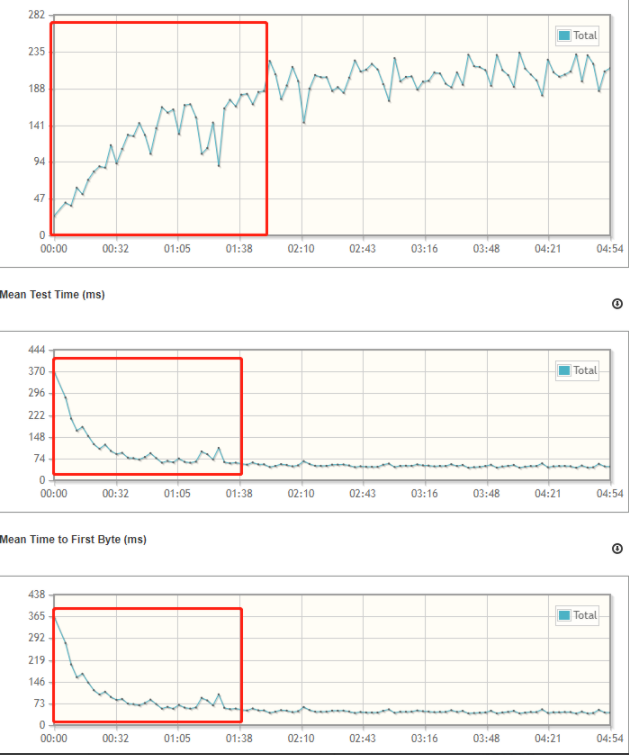
过程记录:pmbs接入中台压测过程中发现,每次并发请求开始一段时间TPS都会出现爬坡现象(时间长度不定,参数文件大小一定的前提下取决于当前TPS),初步分析结果为与接口和参数有比较大的关联,继续深入分析发现,在TPS曲线爬坡时parammodeldetail接口与数据库的交互相对于TPS稳定时存在较大差异,主要表现为爬坡时间段内该接口与product、brandgood、fenshua123数据库发生大量交互(与开发沟通确认,属于逻辑判断问题),暴露目前缓存机制问题。
优化建议:优化读缓存数据不存在时的处理逻辑,减少与数据库的交互频次
响应时间:
慢SQL查询:
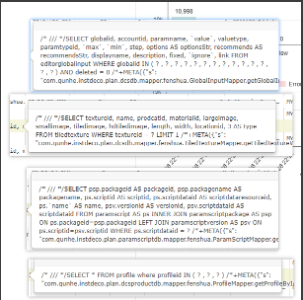
高并发下数据库交互:
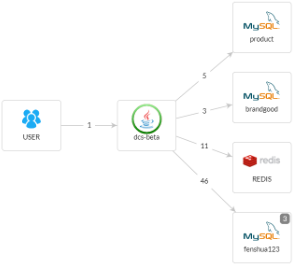
正常并发下数据库交互:
总结:发现有爬坡的爬坡的qps,可以重点分析一些SQL查询的情况,很可能是一些慢查询导致,进而深入代码定位原因
3.2 堆栈数据分析
背景:定制业务迁移,需要做接入云图的性能压测,在现有业务数据的支持下,计算接入后的压力进行压测,并记录相应的性能数据,主要包括dcs服务的保存核心接口等。
过程记录:定制接入云图dcs接口压测过程中发现,并发不断增加的情况下,低于12并发的压力都能够有正常的响应,保持12并发线程请求一段时间后,出现部分报错且响应时间明显增长,tps逐渐下降到0,分析调用链及线程堆栈信息发现瓶颈与存储中台有关,主要使用到了上文提到的内存分析工具,详细内容参考定制接入云图dcs接口性能测试报告。以下是相应业务表现及数据分析结果,通过分析堆栈信息,发现问题根源
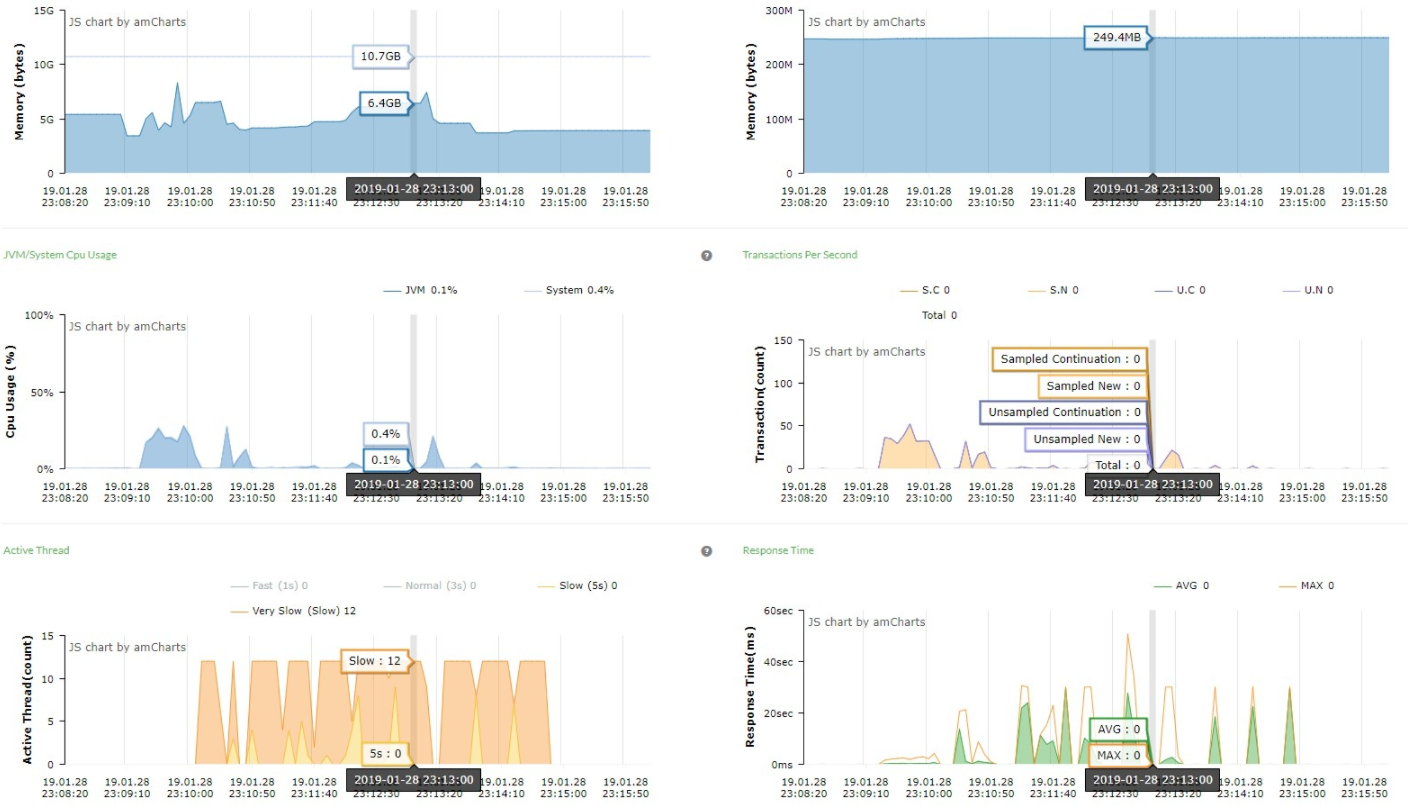
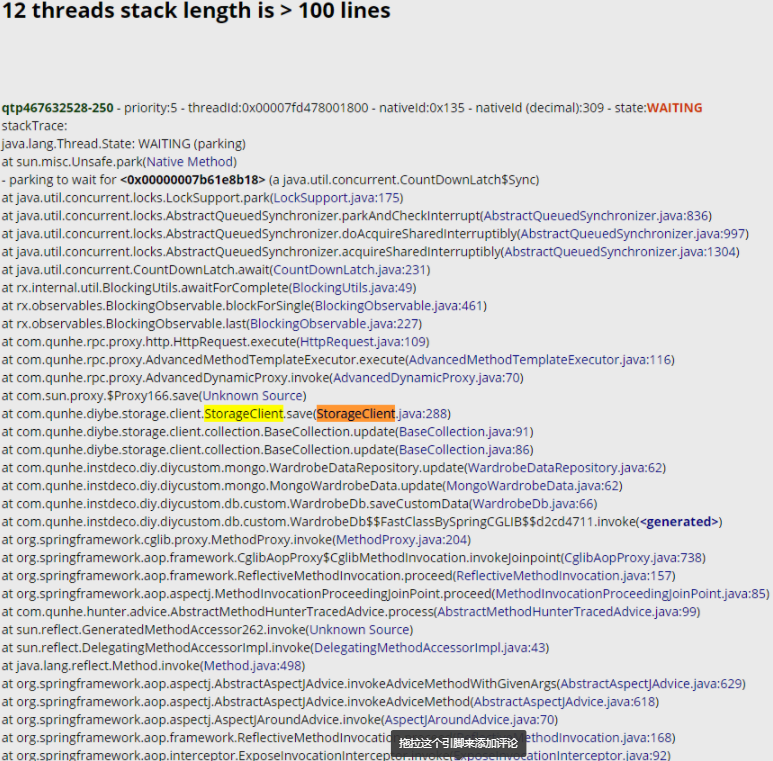
01、性能表现较低且几乎停止服务期间,线程表现:
有12个业务处理线程特别慢,平均响应时间 3秒+
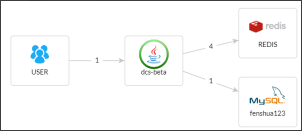
02、分析被测服务堆栈信息发现,12个处理比较慢的线程均与projectstorage服务有关,及存储中台。
怎么看火焰图,参考http://www.ruanyifeng.com/blog/2017/09/flame-graph.html
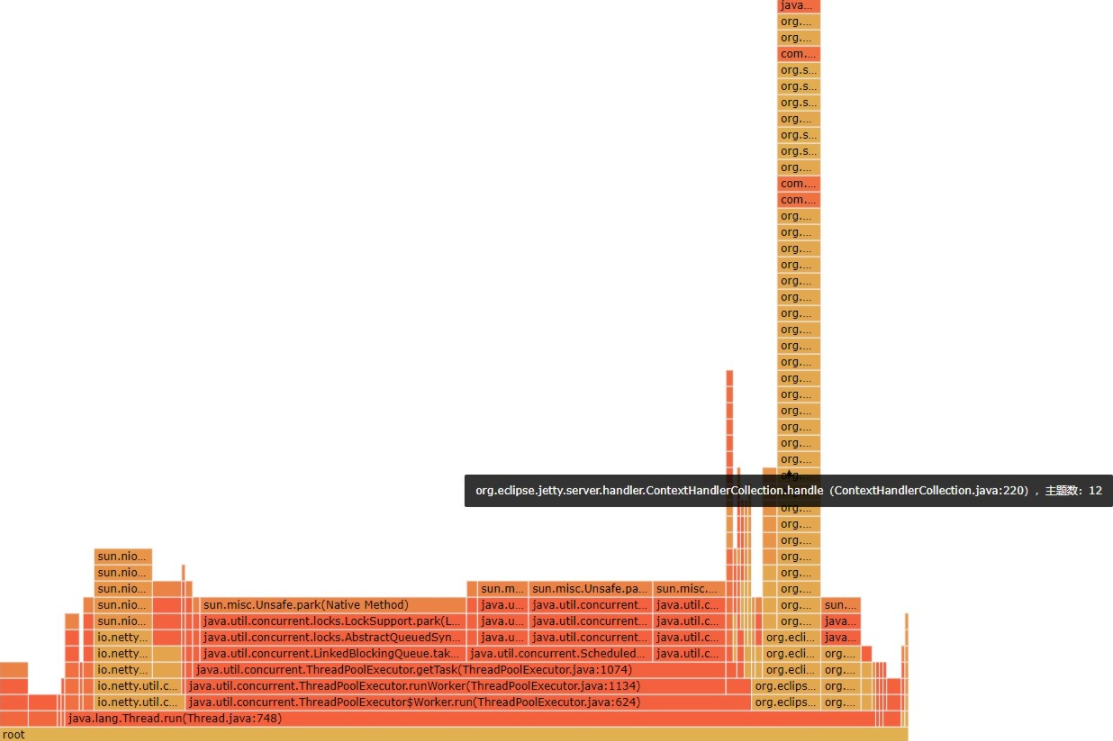

03、获取存储中台相关信息如下:
Beta机器:2台 每台配置:2C4G JVM:-Xmx3G
Online机器每台配置:4C16G JVM:-Xmx12G
压测期间存储中台机器资源使用如右图所示
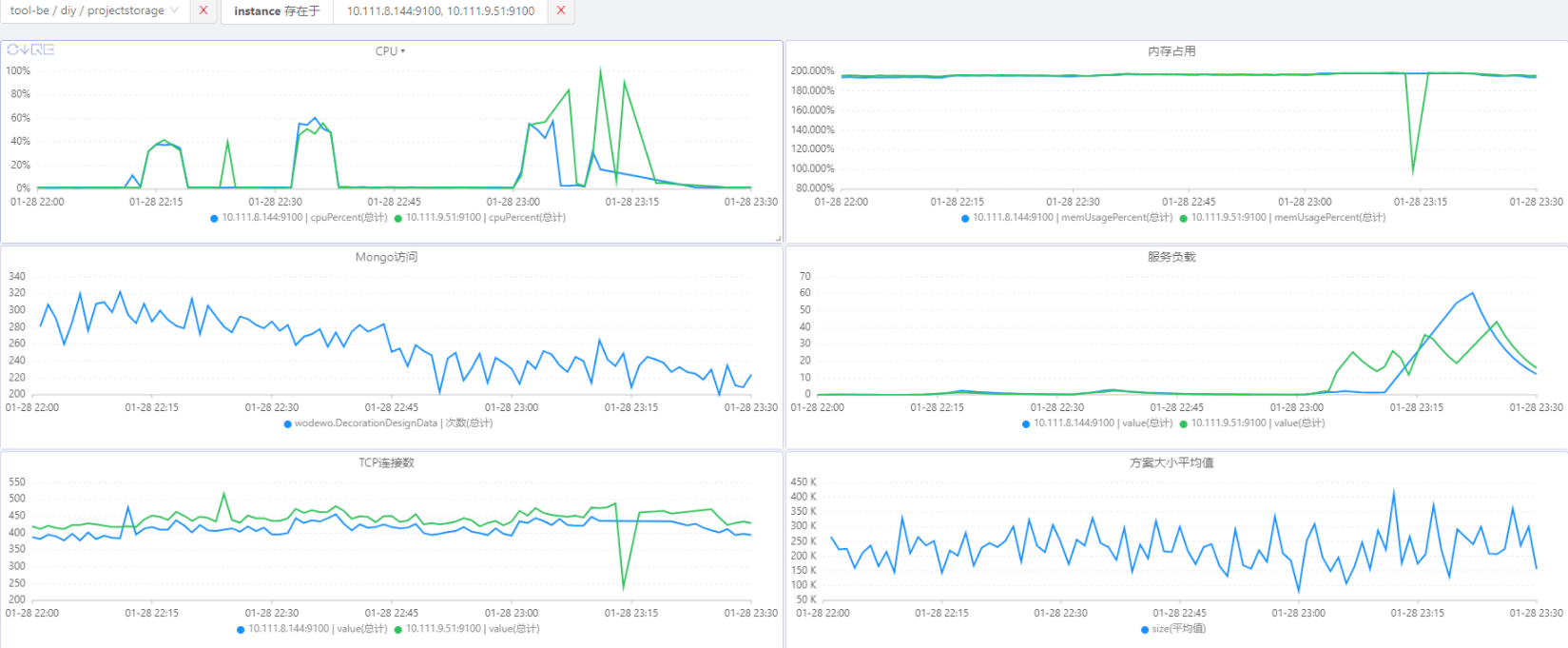
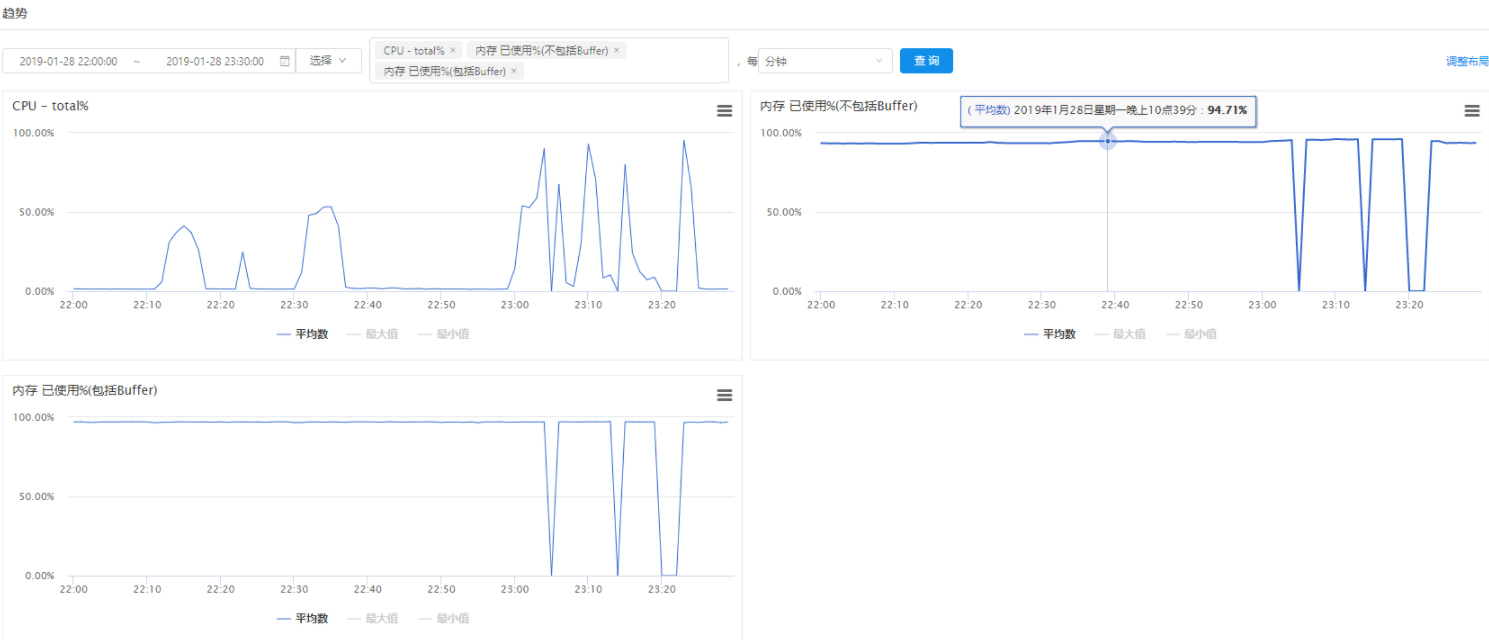
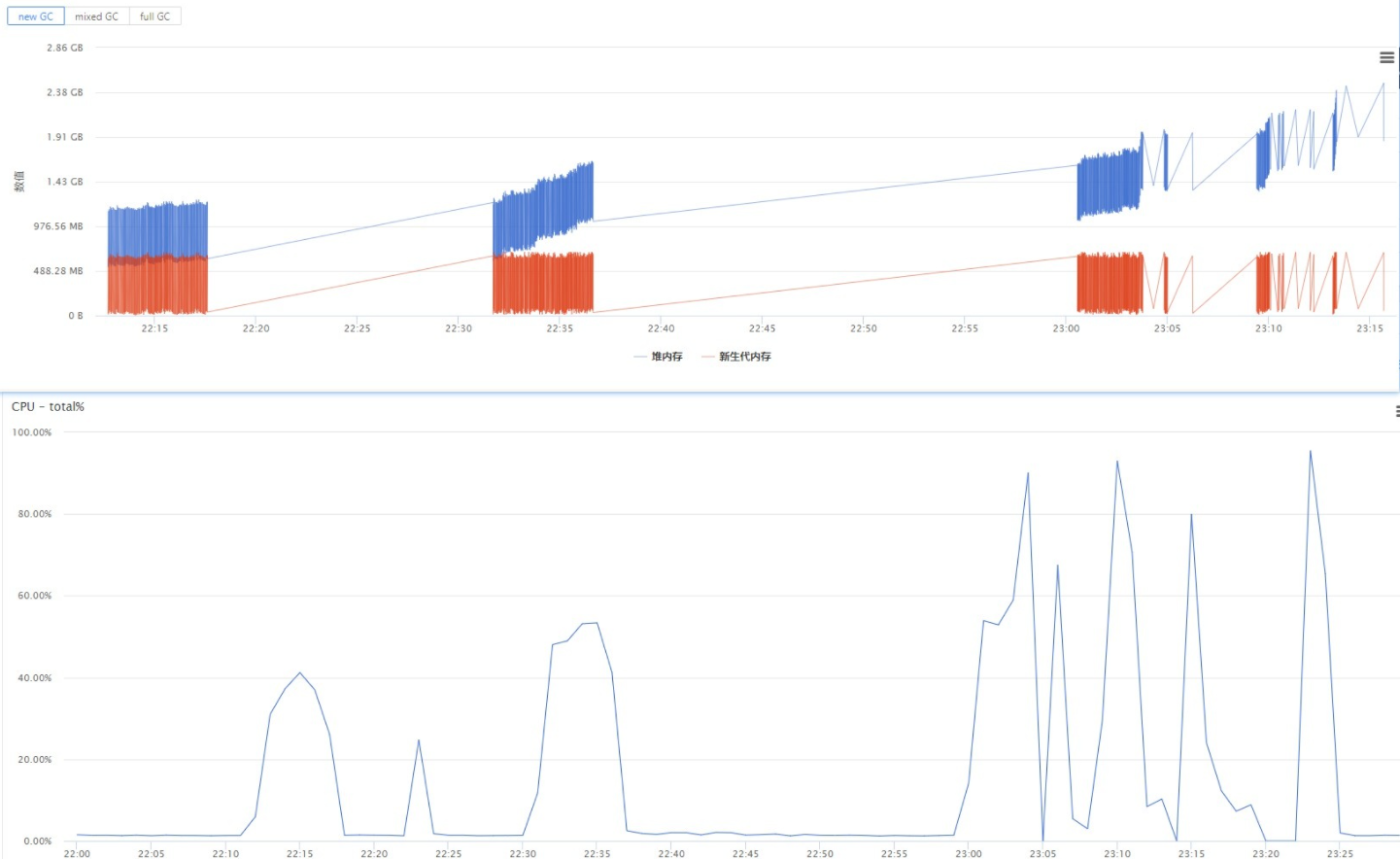
04、从数据表现来看,由于存储中台CPU使用率达到98%+ ,导致服务几乎终止,进而影响到上游被测服务;而存储中台CPU使用率高的原因可能有以下几种:
1、资源配置较线上低很多,频繁GC消耗大量CPU资源
2、物理内存不足,导致大量页面换入患处及线程等待
3、测试期间有其他服务大量请求进入存储中台(询问后并无此情况)
总结:出现服务资源没有被占用,但是接口却无反应,整体处于假死状态,可能是依赖服务处于瓶颈状态,可以针对相关依赖服务做一些排查。
3.3 单接口耗时分析优化
背景:在grep压测过程中,为了进一步的缩短grep核心接口的响应时间,针对单接口深入分析每个过程的耗时,针对性的对不同阶段进行优化,整个处理过程包括以下阶段,为了收集这些数据,开发在不同阶段做了埋点来记录时间并记录到日志中,跑完请求后测试用python脚本对数据进行统计。参考Grep接口耗时分布分析(beta),以下是不同阶段的耗时,用不同的颜色进行区分
buildParamModels:模型build时间
buildBaseModelInfoMap:构建模型信息时间
buildElements:模型从参数化域到图纸域的转换时间
buildGrepRemains:模型build完成后生成所有grep的时间
Full:整个过程按序经历了上面四个步骤,full是包含以上及加解密序列化的所有响应时间
- 优化前后耗时分布对比如下:
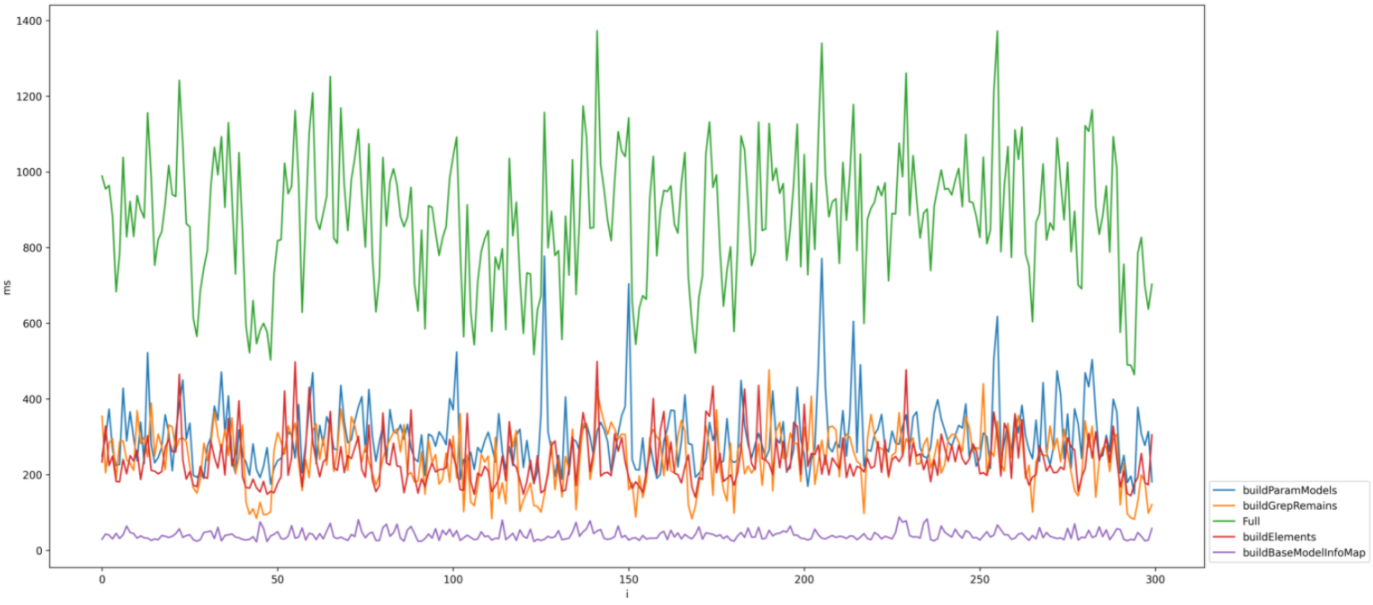
图1 优化前
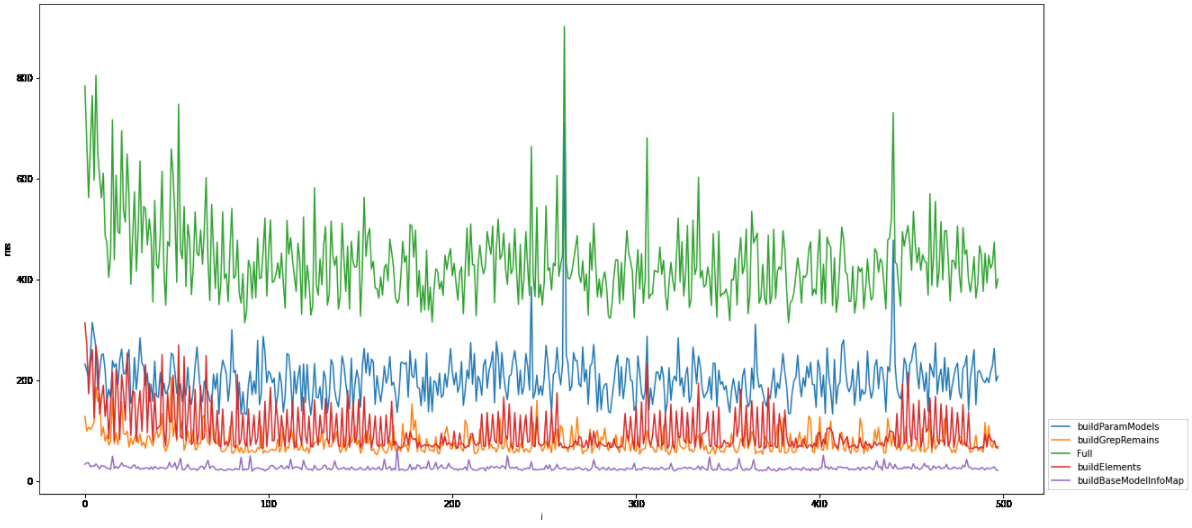
图2 优化后
优化前数据分析
1.耗时的瓶颈仍然在build部分,build模型的时间仍然是占比最高的部分且不太稳定(蓝线部分);
2.构建模型信息时间(红线部分)和之前测试环境的数据出入较大,以当前测试数据为准,该部分时间仅次于build模型时间,两者耗时占比超过full时间的三分之二,有优化空间
优化策略
1.开启pmbs Session保持,同一模型build打到同一台机器
2.参数化模型生成attach 使用缓存
3.pmbs build 前的prepareAppendType 使用缓存
优化后效果
build模型的时间仍有了一定程度的降低,整体响应时间降低20%~30%
总结:单接口耗时,不同阶段的时间分布,可以对不同阶段进行耗时分析,进一步分析可以优化的空间
四、总结
性能测试是比较有深度的测试内容,明显的tps、响应时间、资源占用过高等常见现象比较好定位问题,但是不太明显的性能现象就比较难定位了,本文以实际案例来做深入分析,将性能测试过程发现的不明显现象进行抽丝剥茧找到问题根源,可能不能套用但是有一定借鉴意义;在性能测试过程中,更深入的分析一些异常现象很可能挖掘出隐含的问题,能够防范于未然避免线上问题的发生!
推荐阅读

公众号:酷家乐技术质量 知乎:酷家乐技术质量
TesterHome:kujiale-qa (酷家乐质量效能)