
前言
我们对jvm-sandbox-repeater流量回放框架的实践依然在继续,前文介绍了平台化搭建初期和应用推广初期暴露的问题,以及我们的应对方案。随着酷家乐流量回放平台(kurepeater)的推广和使用,产品整体可用性的问题开始暴露出来。篇幅有限,这里仅介绍3例产品可用性的实践案例。
一、问题简介
流量的录制和回放是jvm-sandbox-repeater的两个主要功能,基本上可用性的问题都和这两个功能相关。
流量录制的主要时序图如下,用户通过平台页面触发模块安装,将流量回放的插件repeater-bin.tar通过命令下发的方式,安装需要录制流量的应用服务器上。
客户端安装成功后,用户再次通过平台激活机器启动录制,这个过程平台会激活repeater-bin.tar,repeater-bin.tar将拦截到的匹配流量再次回调平台进行保存。
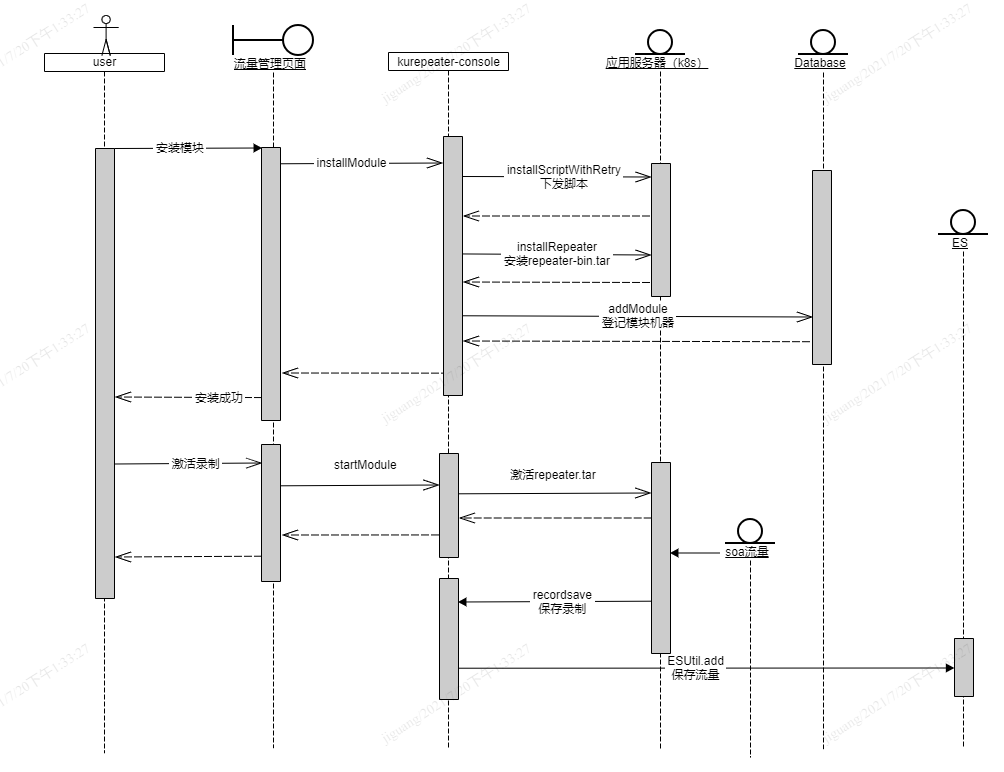
在流量录制的过程中,出现了以下3个问题:
- 流量的明细存储在ES,而ES的容量是有限的,随着接入规模的增加,ES磁盘的告警更加频繁,如何解决?
- repeater-bin.tar拦截的流量,和公司定义的接口表达式没有建立联系,在进行接口聚合的时候,展示不准确的问题如何解决?
- 部分用户提出在流量录制的过程中,只需要关心核心用户流量,如何协助其解决?
二、 回放流量的自动清理
kurepeater录制的流量我们将其存储在ES,但这个ES库不是专属实例,它还共享着公司其他应用。随着一些核心应用接入kurepeater,kurepeater的存储规模也增加起来。
比如下面这个服务,仅一次迭代版本录制的线下流量就达24235条,而这仅仅是录制的流量,用户进行回放后,这个存储的规模还要乘以回放次数,而这仅仅是一个服务的一个版本。

基于这样的背景,公司运维每半年都会找测开同学清理ES数据,避免影响其他应用,而通知清理磁盘的次数最近也越来越频繁。
之前清理过程比较粗糙,根据某个时间戳直接清理库里流量,这会带来一些隐患:
- 首先会产生数据一致性的问题,Mysql维护的用户记录和ES的流量明细不一致,用户会投诉之前录制的流量产生了丢失。
- 基于时间戳清理大量ES数据,会导致ES库cpu飙高,影响实例的稳定性,清理过程中还需要申请运维协助观察,且只能在晚上,过程繁琐。
基于以上背景,kurepeater需要有一套回放流量自动清理机制,整体的时序图如下:
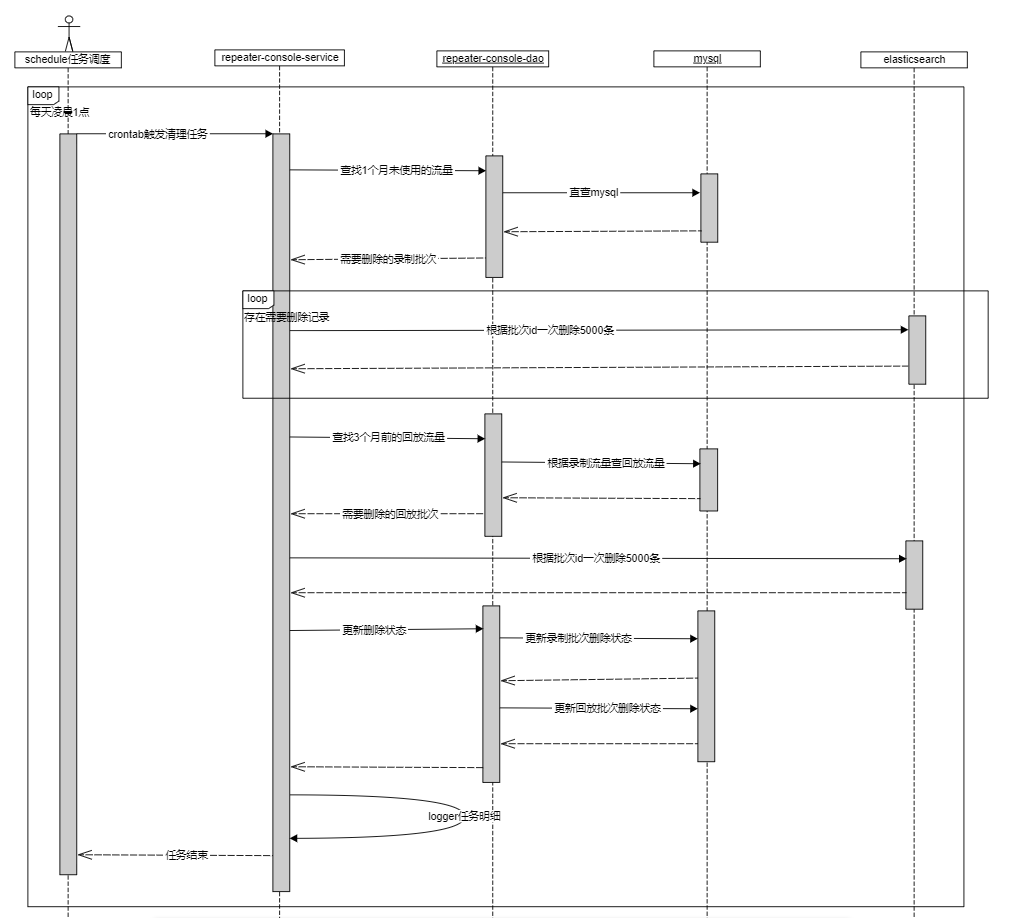
经过5天的清理,清理录制流量1000+批次,回放1400+批次,磁盘占用整体下降2%(包含常规日增长),后续运维也再没有通知测开同学有磁盘告警,需要清理流量数据。

这个过程也踩到了2个坑:
- ES的删除需要先做查询,起初为了追寻效率,查询5000笔作为一个批次,而公司有些接口的请求体和返回体都比较大,出现接口size溢出,后修改成查询100条作为一个批次,后面发现其实效率是一样的。
- ES的工具包,内部会吞掉异常,导致在连接重连或网络异常下漏删,这需要增加异常校验机制,保证es和数据库记录删除状态的一致性,避免漏删。
三、 请求体匹配聚合
repeater拦截的流量主要是url,header,body,在平台上聚合展示给用户的时候,我们选择通过url作为聚合的key,这样会出现问题,如下面2条回放的数据:
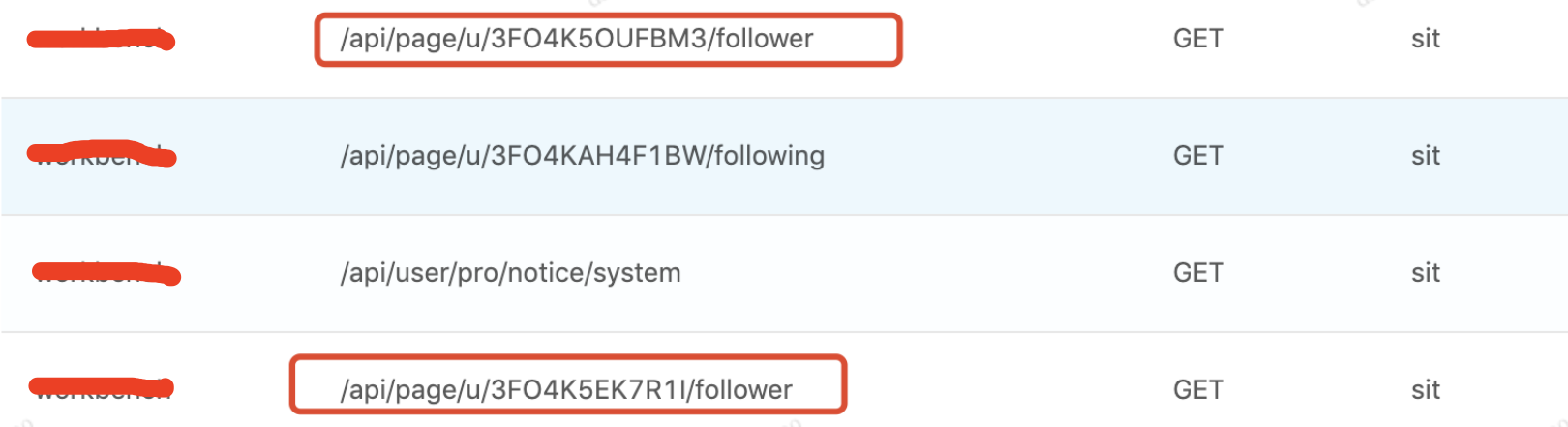
其实是同一个接口表达式,匹配接口定义是:/api/page/{type(?u|pro)}/{obsUserId:3(?:F|f)\w{10}}/follower/{page:\d+}
起初技术同学想通过匹配obsUserId前2位(5F)来替换,但是随着越来越多的服务接入,接口的多样性远比想象的复杂,比如下面的流量:
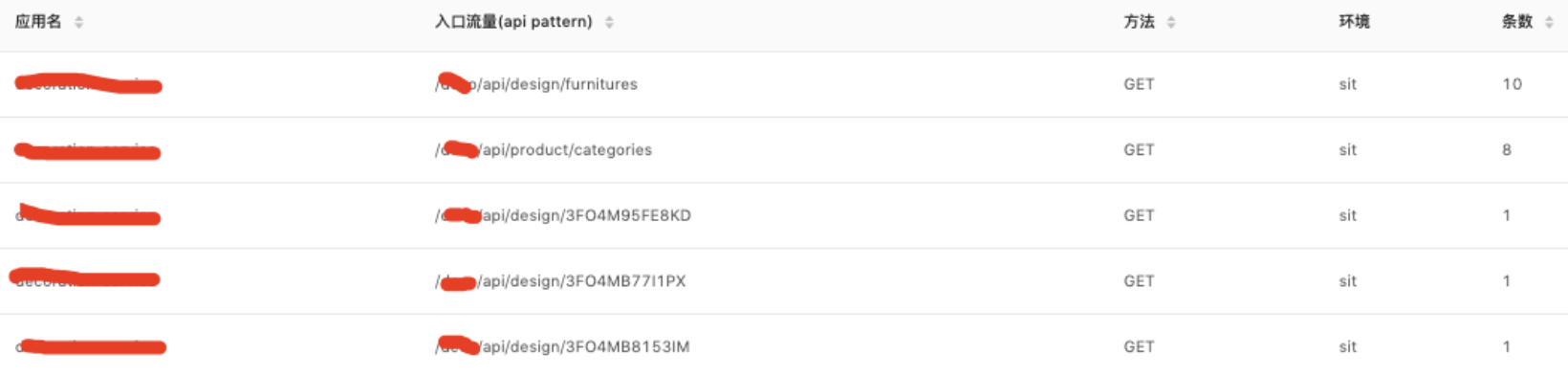
前缀就不是BF,而有些接口存在多个参数,匹配方式就更加复杂,比如下面这个接口基本和研发的风格有关:

经过讨论和调研,最终决定用一种用户自定义规则的匹配方式,为提供5种匹配规则:
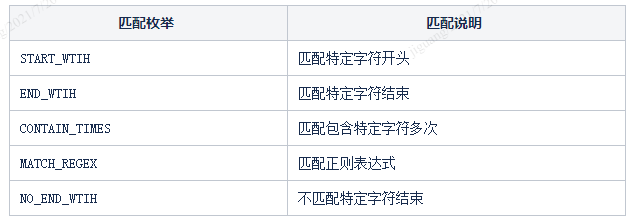
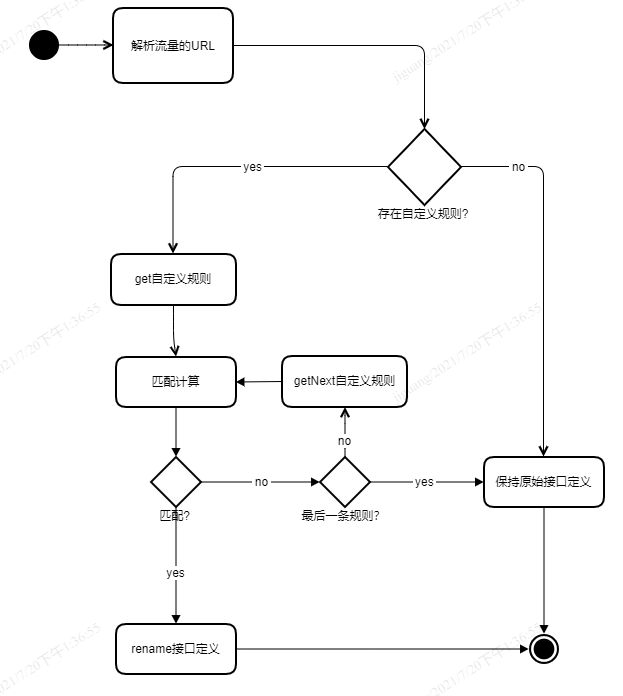
repeater在拦截到流量后,首先检查是否匹配到某一自定义的soa规则,如果匹配,则替换其接口表达式,主要流程图如下:
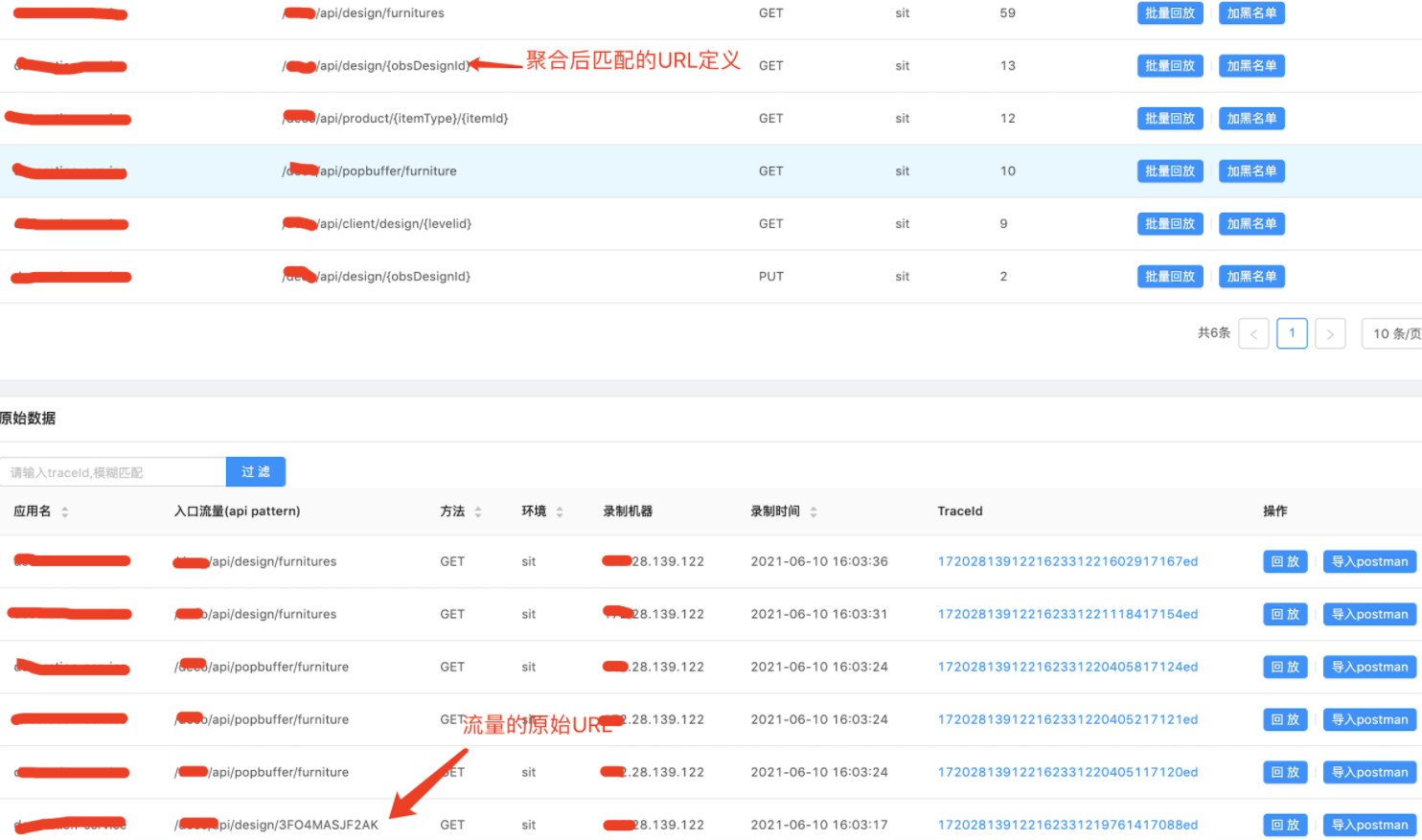
以某应用的2个接口自定义规则为例,接口配置如下:

配置刷新后录制的流量被重新定义URL,进行汇总聚合,同时明细数据展示还是展示原始的URL,不影响回放问题定位,而且还和公司的接口定义进行了关联。
四、对特定用户的流量进行过滤
5月,公司某重要用户接连出现线上问题,该客户和公司多条业务线存在合作关系,各业务线的测试资源分配不均,自动化程度也不一样,这给为整体保证这位用户的质量带来了一定的挑战。
经过测试讨论,可以借用kurepeater的功能,录制该用户线上的流量,在新代码上到预发环境的时候进行回放比对,保证质量,这样可以在极短的时间内提升测试效能。
经过调研,可以通过jvm-sandbox启动发布的通信接口来实现。
jvm-sandbox启动时发布了5个通信的接口,分别是repeat,reload,repeatWithJson,pushConfig,pullLog,其中pushConfig和reload用来更新repeater插件的配置。
而我们要做的是,将用户的userid信息,通过接口同步到服务器的repeater插件上。
经过甄别,最终选择使用reload接口,主要是reload接口会在服务激活的时候,向平台主动拉取配置,这样用户只需要更新配置,重新激活,即可使用新增的流量过滤功能。

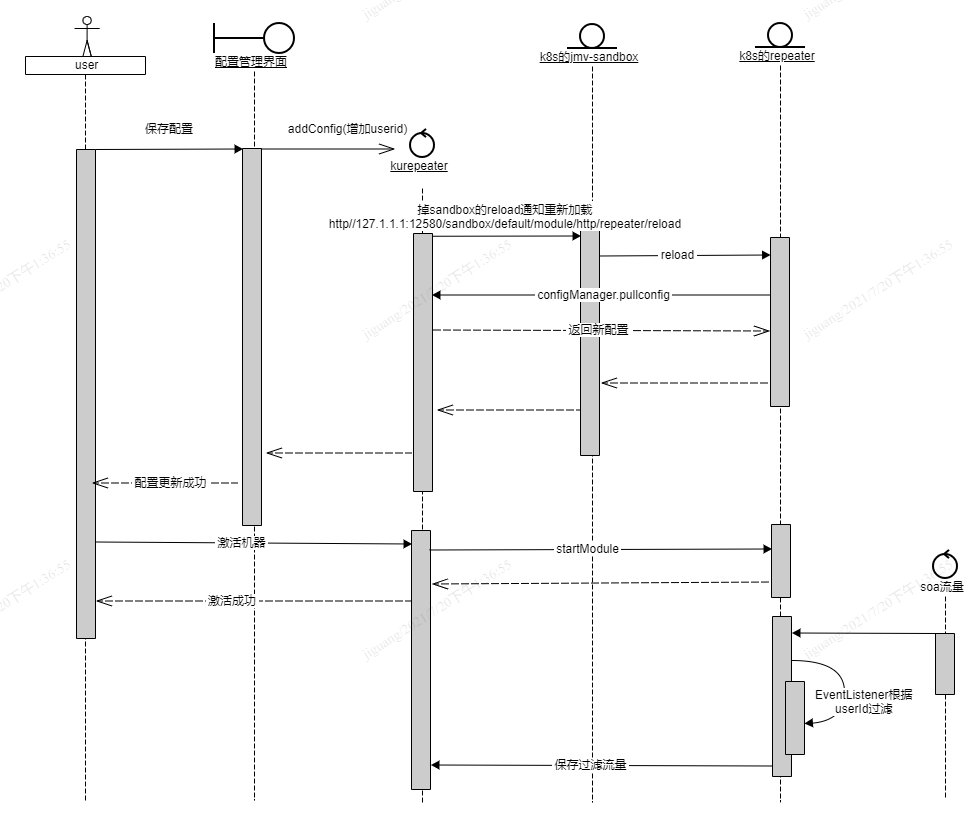
这个过程整体的流程如下,用户在新增配置保存后,kurepeater平台将新的配置存储到数据库中。
然后用户进行服务器激活,repeater重新拉取配置,更新本地的RepeaterConfig变量,将新的userid加入变量。
新的流量在拦截的时候,EventListener根据RepeaterConfig的userid对流量进行过滤,筛选符合需求的流量。
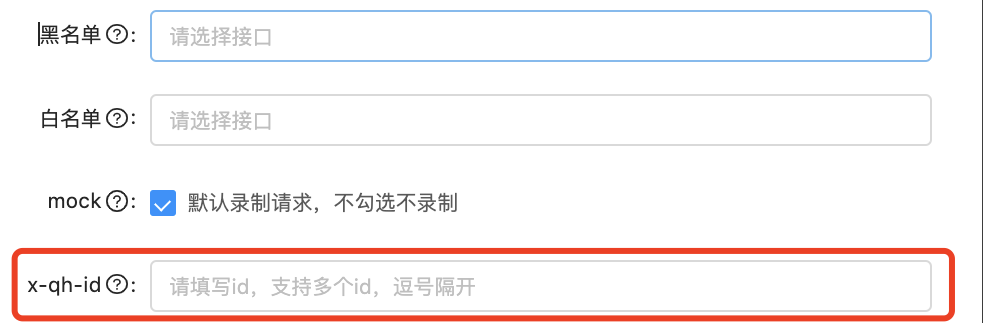
新增的前端交互也比较简单,只需要在配置中增加需要过滤的id,重新激活即可使用。
五、总结
自动清理功能上线后,kurepeater整体数据规模保持在恒定的水平,一定程度上减少测试的维护成本。请求体聚合功能上线后,用户的接口数据展现更加直观,由于聚合配置目前使用人肉的方式,应用新增接口后,需要补充配置新接口,对于接口较多的业务,人为配置存在误配的问题,后续准备基于目前的规则,提供配置智能化生成的功能,同时配置定时任务,实现配置和应用T+1匹配。
推荐阅读

公众号:酷家乐技术质量 知乎:酷家乐技术质量
TesterHome:kujiale-qa (酷家乐质量效能)