
一、背景
随着业务的快速发展,酷家乐数据库量越来越大,其中部分数据表达到二十亿级别。前段时间int整型溢出导致的故障就是一个典型案例,作为公司第一张表达到20亿级别。
单库或单表数据量过大,会导致数据库的查询压力越来越大,数据库读写耗时持续上升。实际工作中我们会发现,对于复杂链路场景,数据库的读写性能往往会成为业务发展的瓶颈。
一般来说对于数据量较大的表,我们会在业务迭代过程中会使用分库分表来降低单实例的查询压力和请求耗时。
此外,不少场景对数据读取耗时要求非常高,尤其是一些关联性非常高的核心表,为了进一步降低请求耗时,也会接入ES等搜索引擎。
二、方案设计
一般数据迁移需要考虑以下两个问题:数据同步的一致性和线上业务无感知
渲染在过去两年内进行了多次的分库分表及数据迁移任务,并攒下了不少经验,供大家参考。
数据迁移大致可以分为以下几个步骤:迁移过程设计、影响范围评估、数据同步与验证、开关操作与代码清理
前面两步相信大家都轻车熟路了,链路梳理完后基本会对业务整体有个清晰的认识,并能给出一个初步的影响范围评估。这个数据迁移过程中核心环节主要有两个:数据同步与验证,开关控制。
为了尽可能降低对业务的影响,实现数据的平滑迁移,一般我们会通过开关控制整个项目进度。确认数据同步完成与校验通过后,逐步打开外网的开关,灰度实现数据的迁移。同时开关为我们提供了一种应急响应方案,迁移过程中一旦新库出现稳定性或数据一致性问题,可快速切回旧库,保证数据库的稳定和数据可靠。
通常我们数据迁移操作主要为以下几个节点:
- 代码上线。开关支持双写切换、读切换,且已在内网验证过;
- 执行双写。打开开关同步写入新老库。默认情况下新库自增主键id来自旧库。
- 存量数据同步。将旧库存量数据同步到新库中;
- 写顺序切换。改写入顺序为先写入新库,旧库自增主键id来自新库。
- 数据同步校验与业务测试验证。
- 切换读开关。改为读新库。
- 观察一段时间,若无问题反馈,则停写旧库、下线开关及迁移代码
通常情况下,线上库每天的写入量是巨大的,因此需要先保证增量数据同步写入新库和旧库后,才会去做存量数据的同步。
这里需要优先保证迁移的代码及其开关上线。数据同步本身的过程相对简单,但是数据源订阅的切换及顺序操作才是风险最大的地方。因此业务逻辑代码实现必须首先得到保障。
另外一个需要注意的地方,数据库迁移之前一定要完成数据表的读写收拢,避免迁库完成后数据不一致,尤其是写入操作主键冲突。一般情况下原数据表是默认有效且可靠的,那么迁表初期自增主键取自旧表;当数据同步完成且校验一致后,自增主键id则可切换到新表。因为外网和beta共用数据库,两个环境顺序不一致就会有可能导致自增主键冲突写入失败,尤其像renderpic,两个环境时刻都在大量写入操作,风险较大。。当然如果数据表比较简单且业务量不大,那么选择深夜直接切换会相对比较简单。
三、数据同步
在进行数据同步时,首先需要确认主键,只有确定了主键ID才能实现数据同步操作。
如果当前表使用了自增主键id,那么在分库分表前需要将主键id的增长规则确定,一般建议采用sequence表同步。
数据同步一般有两种方式:基于特定框架或者工具,自定义代码实现数据同步。
1、存量数据同步
- 代码实现
针对代码中进行数据库的增删改操作时,一般使用游标的方式从旧库分批select数据,经过rehash后批量插入到新库。但是对于大量数据同步处理效率非常慢,执行时间过长。另外如果已经同步过的数据更新,新库与旧库无法保持一致,存在业务风险。因此这种方式一般比较适合简单表或者配置表,对分库分表并不适用。下图为我们其中一次MongoDB数据同步到Hbase,便是采用了代码同步。
/**
* 保存手动灯光配置信息
*/
public Boolean saveLevelLightDataWithConfig(
final String homeDataId,
final String manualLightTemplateId,
final LevelLightDataWithConfig levelLightDataWithConfig) {
if (levelLightDataWithConfig == null) {
return true;
}
final String rowKey = generateNewRowKey(homeDataId, manualLightTemplateId);
LOG.message("saveLevelLightDataWithConfig - hbase log")
.with("rowKey", rowKey)
.info();
try (Table table = connection.getTable(LEVEL_LIGHT_DATA_TABLE)){
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(LEVEL_LIGHT_DATA_COLUMN_FAMILY,
LEVEL_LIGHT_DATA_COL_BYTES, MAPPER.writeValueAsBytes(levelLightDataWithConfig.getLevelLightData()));
if (levelLightDataWithConfig.getManualLightConfig() != null) {
put.addColumn(LEVEL_LIGHT_DATA_COLUMN_FAMILY,
MANUAL_LIGHT_CONFIG_COL_BYTES, MAPPER.writeValueAsBytes(levelLightDataWithConfig.getManualLightConfig()));
}
table.put(put);
return true;
} catch (Exception e) {
LOG.message("saveLevelLightDataWithConfig - failed", e)
.with("rowKey", rowKey)
.error();
return false;
}
}- 框架同步
另一种方式则基于已有的开源工具或者框架定制,比如Canal、maxwell、DataX。同步框架可以定向支持异构数据迁移,非常适合海量数据同步,效率较高。例如Canal的工作原理就是把自己伪装成MySQL slave,模拟MySQL slave的交互协议向MySQL Mater发送 dump协议,MySQL mater收到Canal发送过来的dump请求,开始推送binary log给Canal,Canal解析binary log,再发送到存储目的地,比如MySQL,Kafka,Elastic Search等等。
数据同步一直是拆分最重要的工作。目前我们进行迁移的话会需要采用DTS或者数据库日志binlog同步存量数据。一般建议至少同步两次,一次是原始数据的初步同步,一次在执行双写后执行同步,保证数据的完整覆盖。
酷家乐在开源基础上自研了实时数据管道框架及数据同步方案 ,Oceanus从Vimur的Kafka中获取全量数据进行同步。Vimur是MySQL全量数据和增量实时变更流采集、解析、统一存储的底层数据流订阅方案,有了vimur之后,我们可以全量/增量实时采集数据库中(mysql/tddl)的数据中,存储在消息队列中,供下游用户订阅,感兴趣的可以自行了解下实时数据管道 Vimur 探索之路。当然也可以Oceanus通过直接select 全表的方式,会对线上库产生较大压力,存在一定风险。同步框架如下:
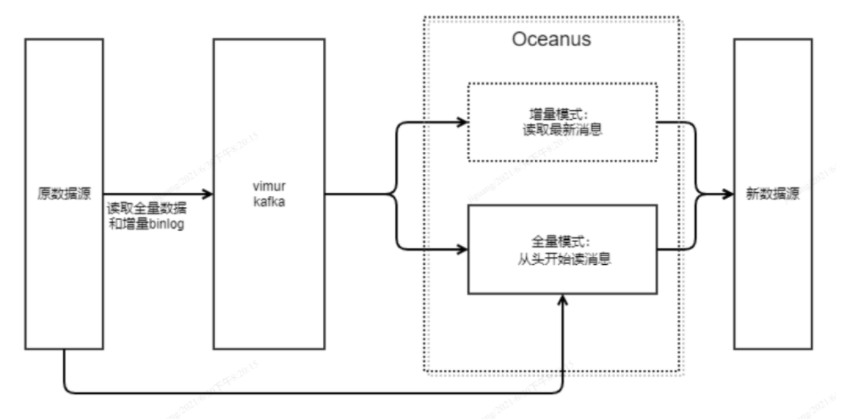
2、增量数据同步
存量数据同步一般也有两种方式:双写(dual write)和数据变更抓取(change data capture, CDC)。
- 双写: 即所有写入操作同时写入旧库和新库,这种方式可以完全控制应用代码如何写数据库,直接进行数据库操作,通过mybatis plugin或AOP方式, 针对insert、update、delete的语句进行处理。听上去简单明了,但它会引入复杂的分布式一致性问题:要保证新旧库中两张表数据一致,双写操作就必须在一个分布式事务中完成,代价太高。如果分库分表设计的数据会很多,这也会影响整体服务性能,因此一般建议一些简单配置表使用双写。下图为我们一次双写的业务代码,通过开关控制是否双写:
@Async("mongoExecutor")
public void insert(final RenderSnapshotData renderSnapshotData) {
if (mFeatureConfiguration.isActive(FeatureSwitchConstants.RENDER_SNAPSHOT_WRITE_TO_HBASE, null)) {
//迁移第一阶段:异步双写进HBase
RENDER_SNAPSHOT_WRITE_EXECUTOR.addSubTask(mRenderSnapshotDataHBase, "insert",
new ThreadTaskInfo(renderSnapshotData.getTaskId(), true), renderSnapshotData);
}
if (mFeatureConfiguration.isActive(FeatureSwitchConstants.RENDER_SNAPSHOT_NO_LONGER_WRITE_TO_MONGO, null)) {
//迁移第三阶段:不再写入MongoDb
return;
}
insert(renderSnapshotData, WriteConcern.ACKNOWLEDGED);
}- 数据变更抓取: 通过数据源的事务日志抓取数据源变更,线上业务只需要保证对旧数据源的增删改操作正常,同步框架会根据事务日志自动同步到新的数据源,而且同步延时非常小。CDC的局限性在于各种数据源的变更抓取没有统一的协议,如 MySQL 用 Binlog,PostgreSQL 用 Logical decoding,MongoDB 里则是 oplog。另外同步任务的实时响应可靠性与时效性也是需要解决的一个问题,需要保证数据不丢、同步不延时,遇到服务异常等原因,会直接影响到整体数据的一致性。CDC比较适合海量数据同步。这里仍旧用Vimur+Oceanus框架实现数据同步,可以保证毫秒级的数据同步。
四、数据校验
1、存量数据校验
数据校验由data-check模块来实现,主要是基于数据库层面的数据对比,逐条核对每一个数据字段是否一致,不一致的话会经过配置的校验规则来进行重试或者报警。
- 以旧库为基准,查询每一条数据在新库是否存在,以及每个字段是否一致。
- 以新库为基准,查询每一条数据在旧库是否存在,以及每个字段是否一致。
如果数据同步是代码实现的话,那么可以在同步的时候顺便实现数据结果的一致性校验。
如果数据是通过同步框架实现,一般我们会在任务完成后校验数据总量是否一致。对于一个几亿条数据的同步,一般会存在少量丢失的情况。如果存在较多数据不一致的情况或者数量总量偏差达较高,那么我们会认为这次数据同步不完整,需要再次同步数据并进行校验,尽可能减少数据的不一致。
2、增量数据校验
接口调用验证双写功能是否完善。增量数据可以通过夜间定时任务读表对比校验。
- 定时任务每5分钟校验,查询最近5+1分钟旧库和新库更新的数据,做diff。
- 差异数据进行二次、三次校验(由于并发和数据延迟存在),三次校验都不同则报警。
下图是我们一次数据对比校验的过程,数据变更后,从业务场景获取到变更项,从而查询到该库的自增主键id,分别取数据库和ES中获取全部字段,逐一检验。
- 对于简单表,数据校验主要有两种。
- 数据量不是很大的话可以直接在dbv中对比验证,单次可以查询百万级别的数据,对于千万级别的数据库可以通过脚本简单实现,同时dbv也提供了数据对比功能。
- 执行数据字段校验。这里需要脚本实现,可以参考搜索稳定性——数据校验&数据订正 及定制的数据迁移数据迁移测试经验总结。
- 对于数据量比较大的,包括分库分表的,建议交给大数据组去验证。脚本订阅实现会复杂且验证时间过长。

五、测试验证
测试验证会在不同阶段做不同的方式验证,会结合开关状态进行。影响范围确定后,即可以从测试角度思考如果保障整体迁移过程中的稳定性。可以从以下几个方面分别去实践:
- 数据层面,迁表过程中的数据一致性。这里既需要验证DTS数据同步后的一致性,还需要验证双写过程中的数据一致。数据校验保证数据字段的一致性,尤其对新增数据,在上一部分已提及,不多赘述。
- 服务层面,接口测试。受影响的服务较多,每次验证时需要保证当前接口测试通过且结果一致。这里可以考虑使用diff平台进行流量回放。
- 业务层面,主流程回归。观察核心服务各个功能是否依旧完善。一般建议内网迁移后可以在sit观察一段时间,充分暴露出问题。在任意数据同步结束或开关切换时,回归全部主流程及相关影响功能,保障业务不受影响
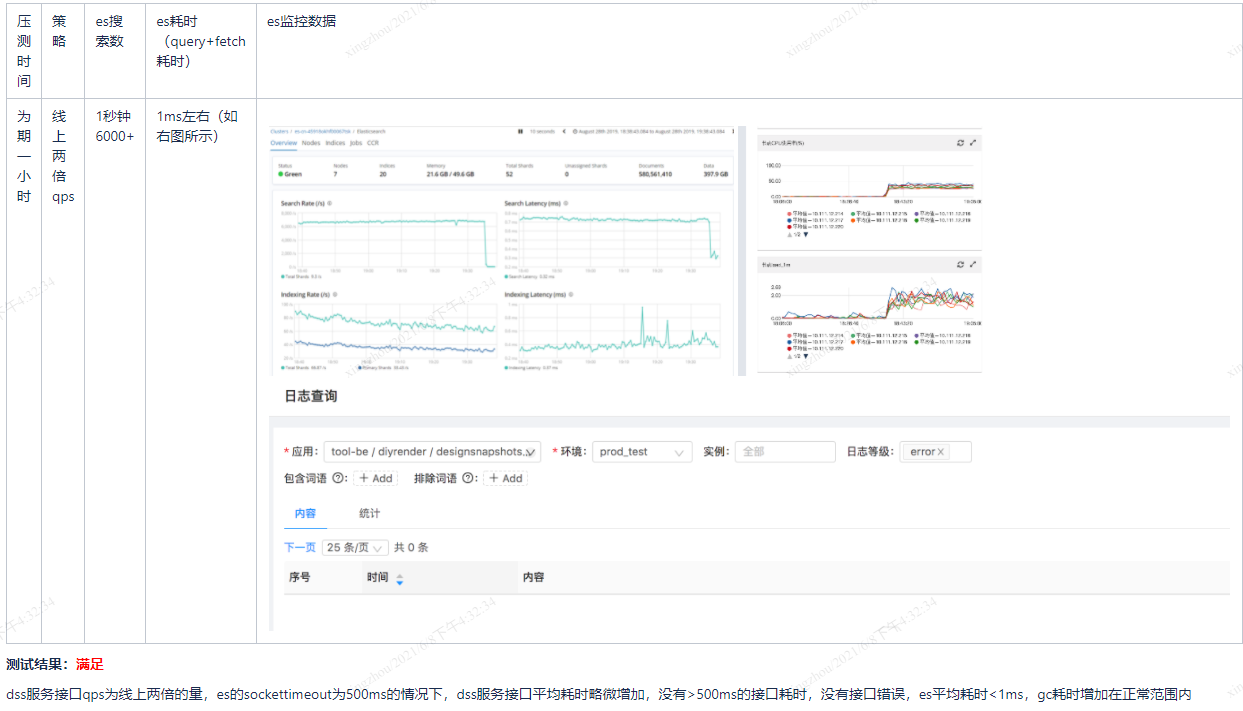
- 性能测试,确保数据迁移后性能较之前有所提升,并达到期望值。尤其是接入ES等搜索引擎,请求RT会降到毫秒级,稍微一点的抖动对线上业务影响都是巨大的。如下图,在接入ES期间,我们会根据实际接入状况进行多次不同数据的压测
六、上线与开关操作
在内网测试环境,可以放心大胆的执行数据变更与开关操作,这个时候我们期望尽可能的把问题暴露出来。一般内网执行步骤:
开启双写开关→内网数据同步→内网数据校验→切换内网读开关到新库→单写新库→开关与代码清理
而在预发环境,则需要慎重了,因为和prod环境用的同一套存储,会直接影响线上使用。
线上开关操作则是整个迁移过程最简单却最有风险的一环。尤其是读开关切换到新的数据源时,会直接影响线上用户。
理想情况是开关支持一定程度上的灰度,可以在持续稳定一段时间后完全迁移。不过数据层很少支持,一般会在功能层面支持。
下图是我们数据迁移过程中定义的若干开关方法,在适当的时机选择控制开关操作非常重要。

七、总结
出于业务稳定考虑,整个数据迁移过程会持续比较久,每一个阶段会在线上观察一段时间后再进行下一步。
实际工作中迁移时间有限,我们需要在有限的时间内讨论出不同迁移方案,并选择一套最可靠最稳妥的方案。对于过程中的任何问题不放过,才能更好的保障线上业务。
实际迁移过程中的细节有很多,从数据迁移的准备工作到数据同步测试,从灰度流程确定到正式线上切换,尤其是结合业务和数据的特点,有很多需要考虑的细节,这里就不一一介绍了。
推荐阅读

公众号:酷家乐技术质量 知乎:酷家乐技术质量
TesterHome:kujiale-qa (酷家乐质量效能)