
1. 背景说明
在酷家乐 serverless 体系中,faas 服务通过请求同 namespace 下的 gateway-service 服务来实现服务转发,达到与公司内部 SOA 服务相通的交互目的
整体链路为: knative istio gw → faas (node.js) → gateway-service → Java (SOA) ,
其中 faas 服务通过 k8s service name 的方式去访问 gateway-service (http://gateway-service, 并不带域名后缀)
这个 dns 问题就发生在 faas → gateway-service 之间,更确切的说,是 faas → kube-dns 之间,这里借用知乎上的一张图来展示下细节链路:
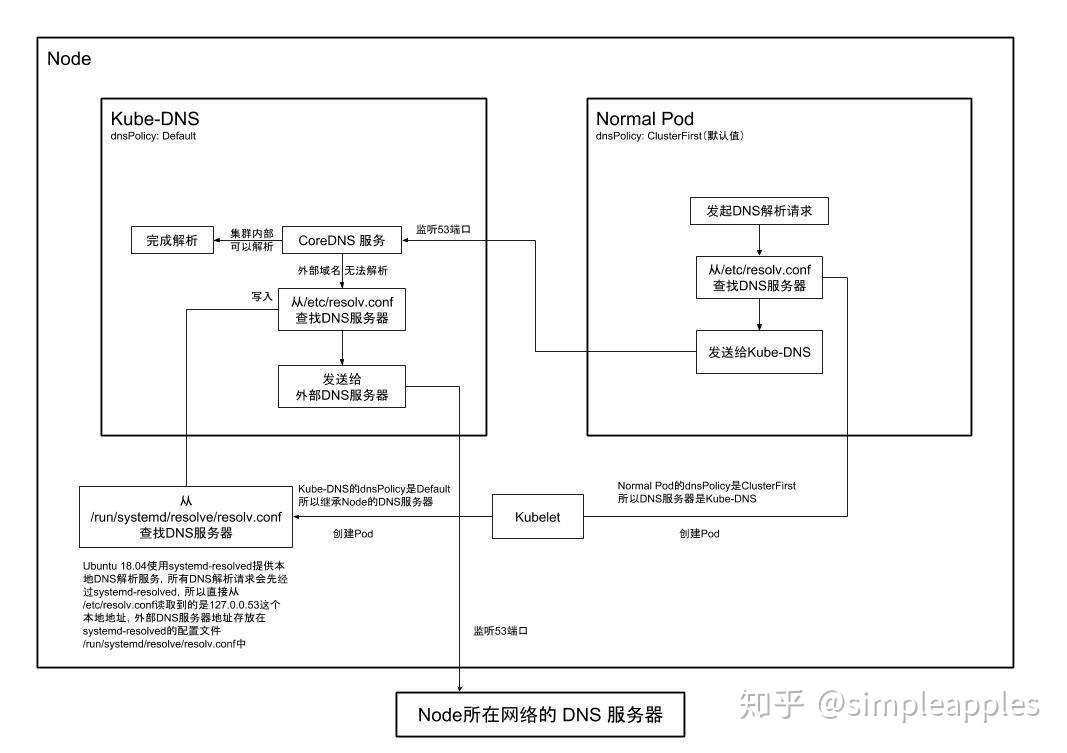
在集群中,当我们通过 k8s-service name做服务间请求时,会先发送 dns 解析请求到 kube-dns,然后 kube-dns 会返回 dns 解析结果给请求方,
在此期间,如果 kube-dns 没有返回,就会造成 nodejs 服务 dns lookup timeout。
2. 问题描述
该 faas 服务高峰期 QPS 在 80+ 左右,3 个 1C 实例, http client 使用的是 got (Weekly Downloads 16,310,782)
服务上线后发现会偶现 500 的返回错误,错误日志显示是: Request Timeout, 通过添加 timing 打印定位到是 dns 解析阶段超时导致的:

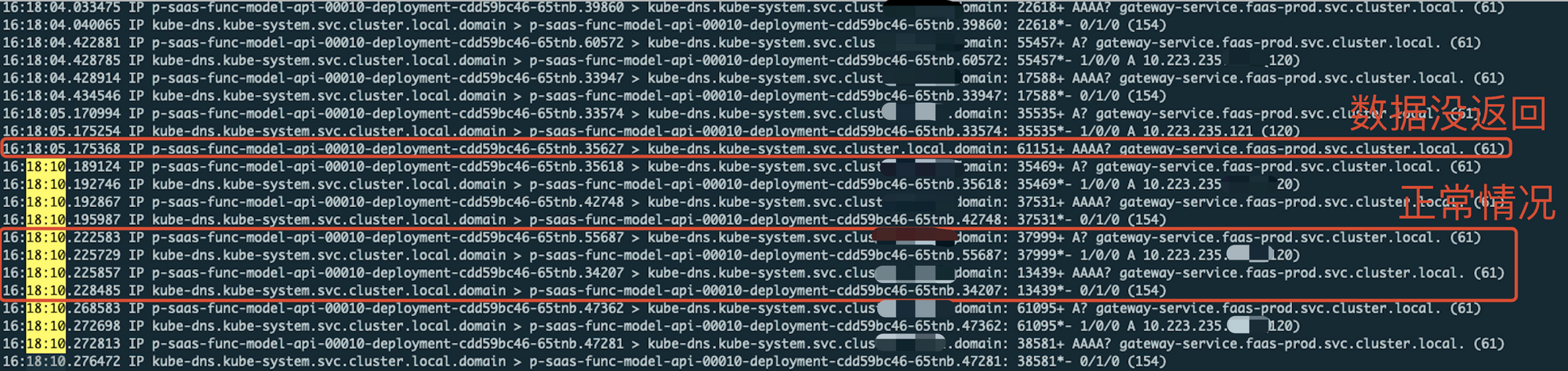
我们开始对集群内其中一个实例做 tcpdump 日志抓包,发现 kube-dns 在 ipv6 阶段会有偶现数据不返回:
2.1 问题分析
在网上查了资料,主要有以下几个可能的原因:
2.1.1 猜测 1
有说是 Alpine 镜像版本过低 或 kubelet dns search 限制 等基础设施问题
https://kubernetes.io/zh/docs/tasks/administer-cluster/dns-debugging-resolution/
ps: 我们使用的镜像是 centos 7.2,使用的版本都不在问题版本范围之内,故排除此项
2.1.2 猜测 2
或者是 ipv6 模块解析慢导致的,
https://yuerblog.cc/2019/09/02/k8s-%e4%bc%98%e5%8c%96dns%e8%a7%a3%e6%9e%90%e6%97%b6%e9%97%b4/
需要关闭 ipv6 选项来解决这个问题。
ps: 服务的 dns family 解析可有客户端自行定义,可以控制避免 ipv6 的解析请求,故排除此项
2.1.3 猜测 3
也有说是 Linux conntrack内核模块在 GNU C库和musl libc都并行执行A和AAAA DNS查找时;由于竞争,内核可能会丢弃其中一个UDP数据包,从而导致超时
https://bbs.huaweicloud.com/blogs/192337
https://cloud.tencent.com/developer/article/1583706
通过 1. udp 改 tcp (dns 查询是 udp) 2. 修改 /etc/resolv.conf 来避免相同五元组 DNS 请求的并发 3. 集群添加 NodeLocal DNSCache 任意一种方案来解决
ps: 这个答案比较贴合我们场景的,可能由于 dns 并发导致的处理超时,但是公司内集群架构暂无安装 nodelocal cache 的打算,我们需要为服务额外新增 dns cache 方式
2.2 尝试方案
找到上面一些疑点和经验,我们开始排查、定位问题并尝试多种方案,书写顺序按实践时间升序
2.2.1 禁用内核 ipv6 参数
设置 net.ipv6.conf.default.disable_ipv6 = 1 来禁用 ipv6
结论:通过抓包分析,ipv6 dns 请求并没有禁止掉,依旧在发送,验证失败
2.2.2 改为串行 DNS 请求,禁用并发
通过写入 “/bin/echo 'options single-request-reopen' >> /etc/resolv.conf” 改为串行发送 A 类型和 AAAA 类型请求,避免五元组冲突
结论:通过抓包分析,串行设置生效,能解决一定程度上的超时,但并没有从根本上解决问题
2.2.3 服务添加 dnsCache & 限制 ipv6 dns 请求发送
通过 dns 抓包并结合上述两次方案尝试,我们发现有两个问题需要去解决:
- dns 发送频率过高,单机每秒十几次的请求
- 禁止 ipv6 解析(每次请求都默认有 ipv6 dns 解析, 而我们集群并没有使用 ipv6,并且 ipv6 解析容易超时)
我们开始分析服务使用的 client 包,想添加 dnsCache 来解决问题 1,以及通过限制 ipv6 dns 请求发送来解决问题 2
此处主要关于 npm got 和 nodejs dns 模块的使用分析,其他语言开发者可跳过:
我们使用的 got 包,其默认带有 dnsCache 功能,当我们设置 options.dnsCache = true 时,底层会默认创建一个 dnsCache 类来维护 cache 状态并重写 lookup:
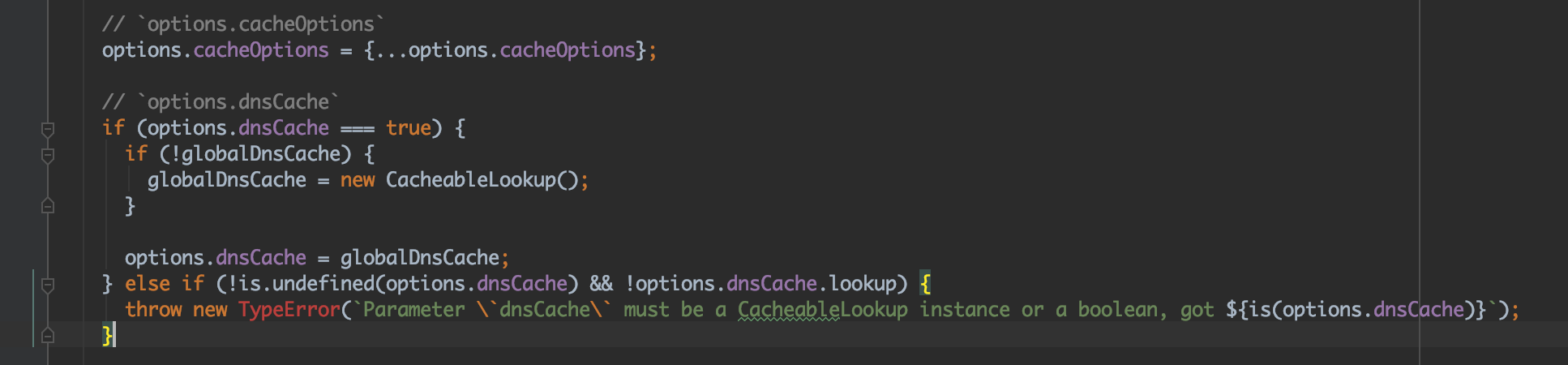
但结果不尽人意,dns 并没有被缓存,于是我们对其引用的 cacheable-lookup 三方包添加日志打印,发现:dns.resolve* 总是被解析失败,导致每次请求都走一遍 dns.lookup

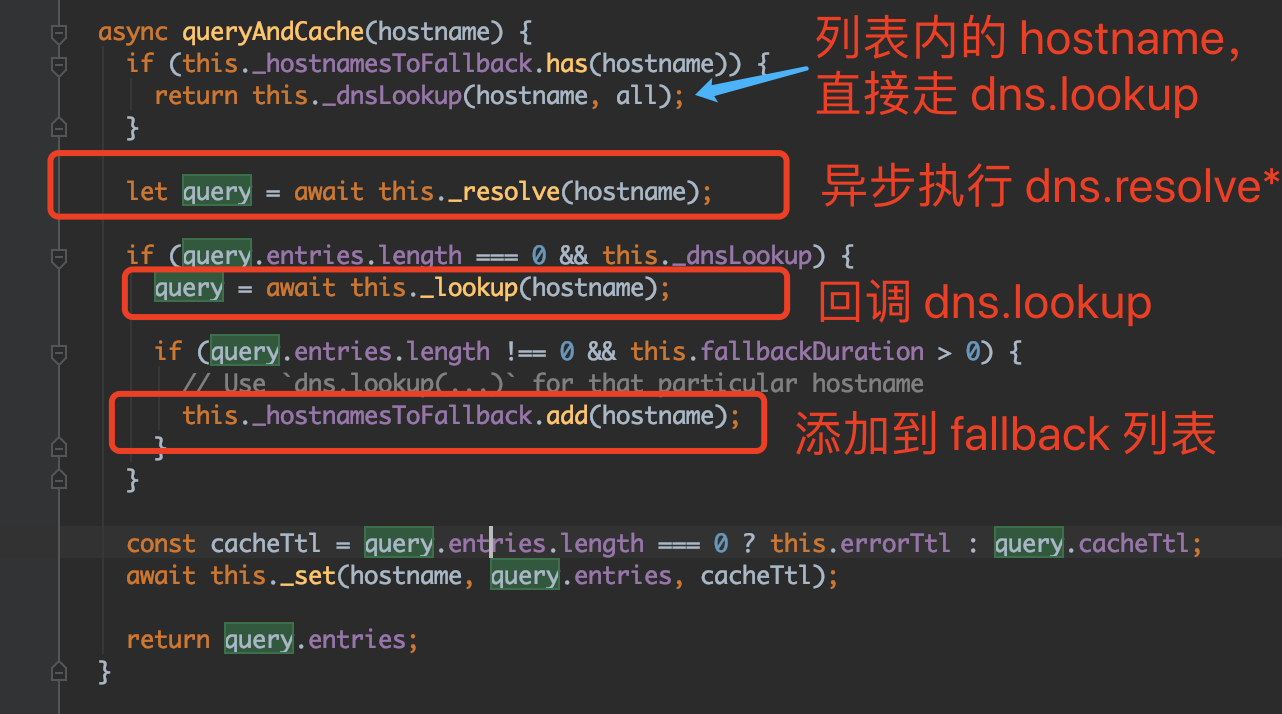
这里大致描述下它的缓存方案:
- 根据 hostname,判断是否存在于 fallback 列表
- 若 hostname 存在,直接异步执行 dns.lookup 并返回
- 若 hostname 不存在,判断是否存在于 cached
- 接3,若 cached 存在,返回缓存信息
- 接3,若 cached 不存在,重新执行 queryAndCache 查找函数并返回查找结果
- 然后 queryAndCache 函数会先异步执行 dns.resolve4 和 dns.resolve6
- 接6, 如果找到,缓存到 cached;
- 接6, 若未找到,异步执行 dns.lookup 继续查找(若依旧失败则抛错),并添加到 fallback 列表(默认 1h 的缓存失效时间)
以下是核心代码:
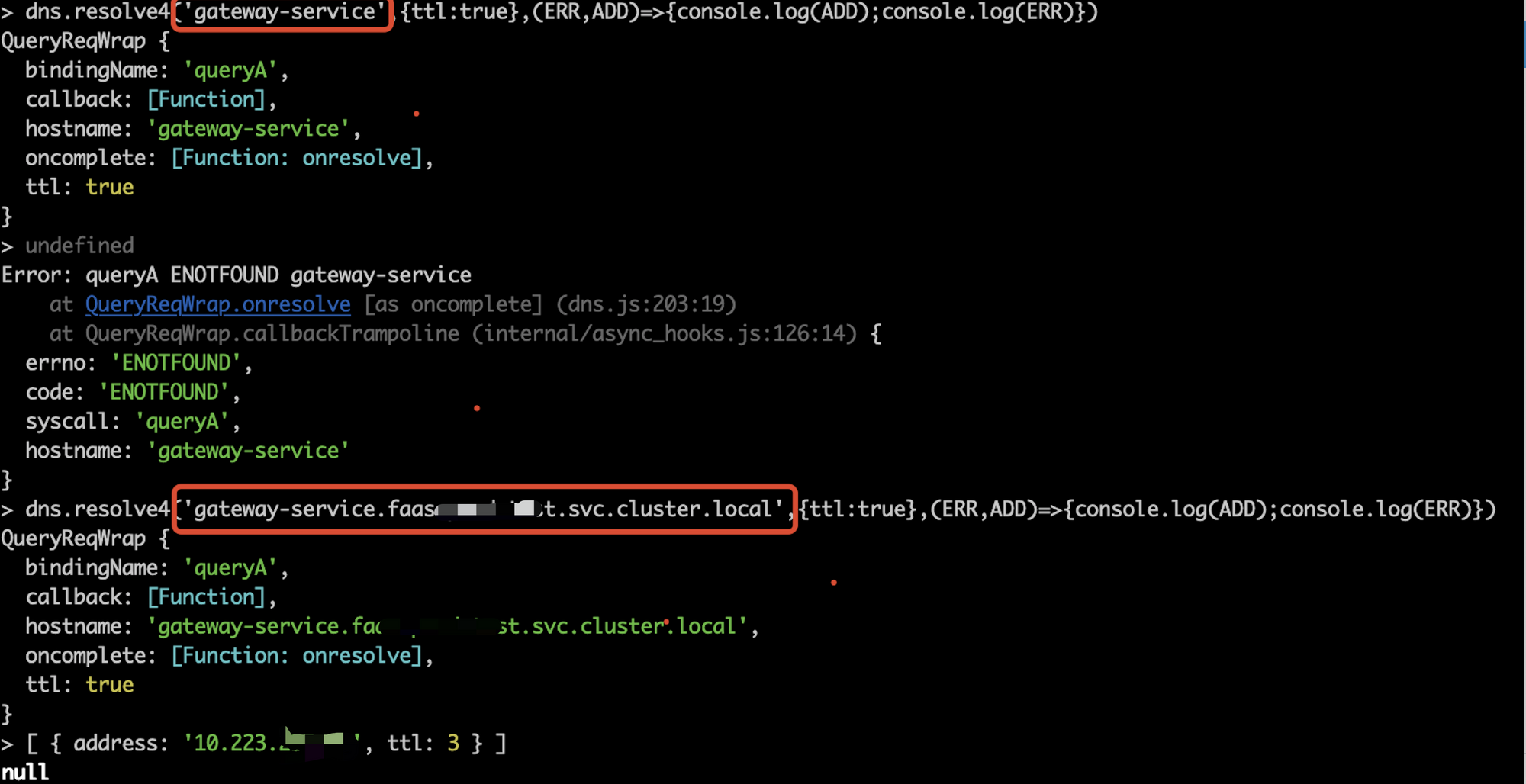
结合上述错误日志,我们可以发现 dns.resolve* 对于我们 hostname 并不生效,
经调试发现 dns.resolve* 在 k8s 集群内无法解析出 gateway-service 这样的 service name,
必须使用完成的内部域名(gateway-service.**.svc.cluster.local)才能被正确解析
其实这个问题其实不能全怪 dns.resolve*,大家可以先看下 dns.resolve* 和 dns.lookup 的区别: https://nodejs.org/api/dns.html#dns_implementation_considerations
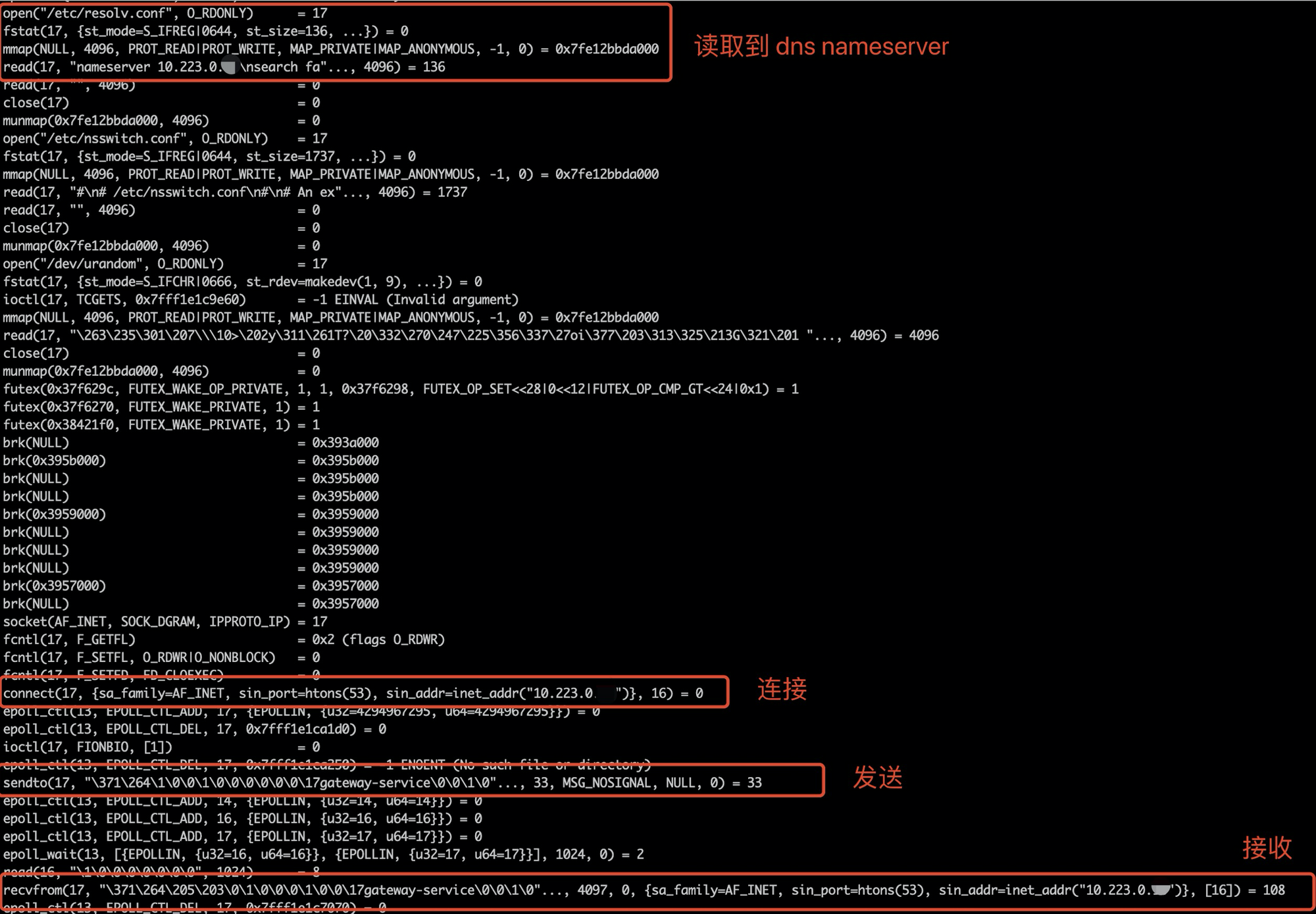
简单的说,dns.resolve* 是调用的是 c-ares (C library for asynchronous DNS requests) ares_query 执行的网络 DNS 查询,其请求最终是发送到 kube-dns 代理服务器,
但 kube-dns 无法解析 gateway-service 这样的 hostname,所以总是返回 NXDomain

解析完成的内部域名是可以的,但是仅服务名是无法被解析的:
以下是 dns.resolve* 的 strace dns 请求过程,可以看到在 c-ares 里会读取 /etc/resolv.conf 的 nameserver 配置并发起查询请求:

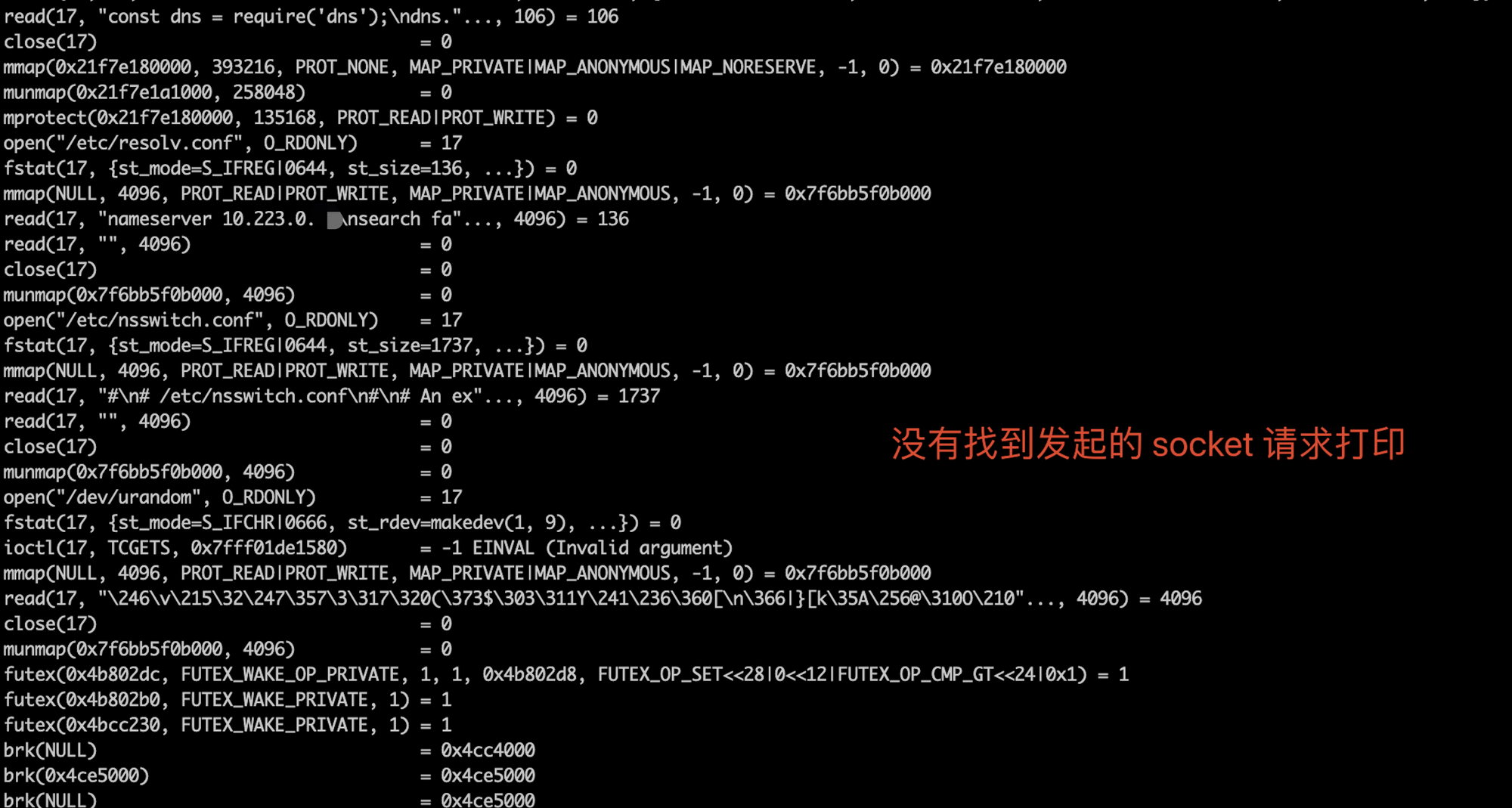
那么为什么 dns.lookup 就可以了呢?是因为 lookup 调用的是系统底层的 getaddrinfo(3),是由系统内置库发起的 socket 连接,
中间有什么区别呢?
我们来对比下 strace dns 请求过程:
首先在执行 dns.lookup 后,跟踪进程日志里并没有 socket 信息
然后通过增加 strace -f 指令去跟踪目标进程以及目标进程创建的所有子进程后,找到了对应的 dns socket 连接及请求,
发现此时的 hostname 使用的是完整的内部域名发送到 kube-dns ,所以可以正确的解析到 host ip。
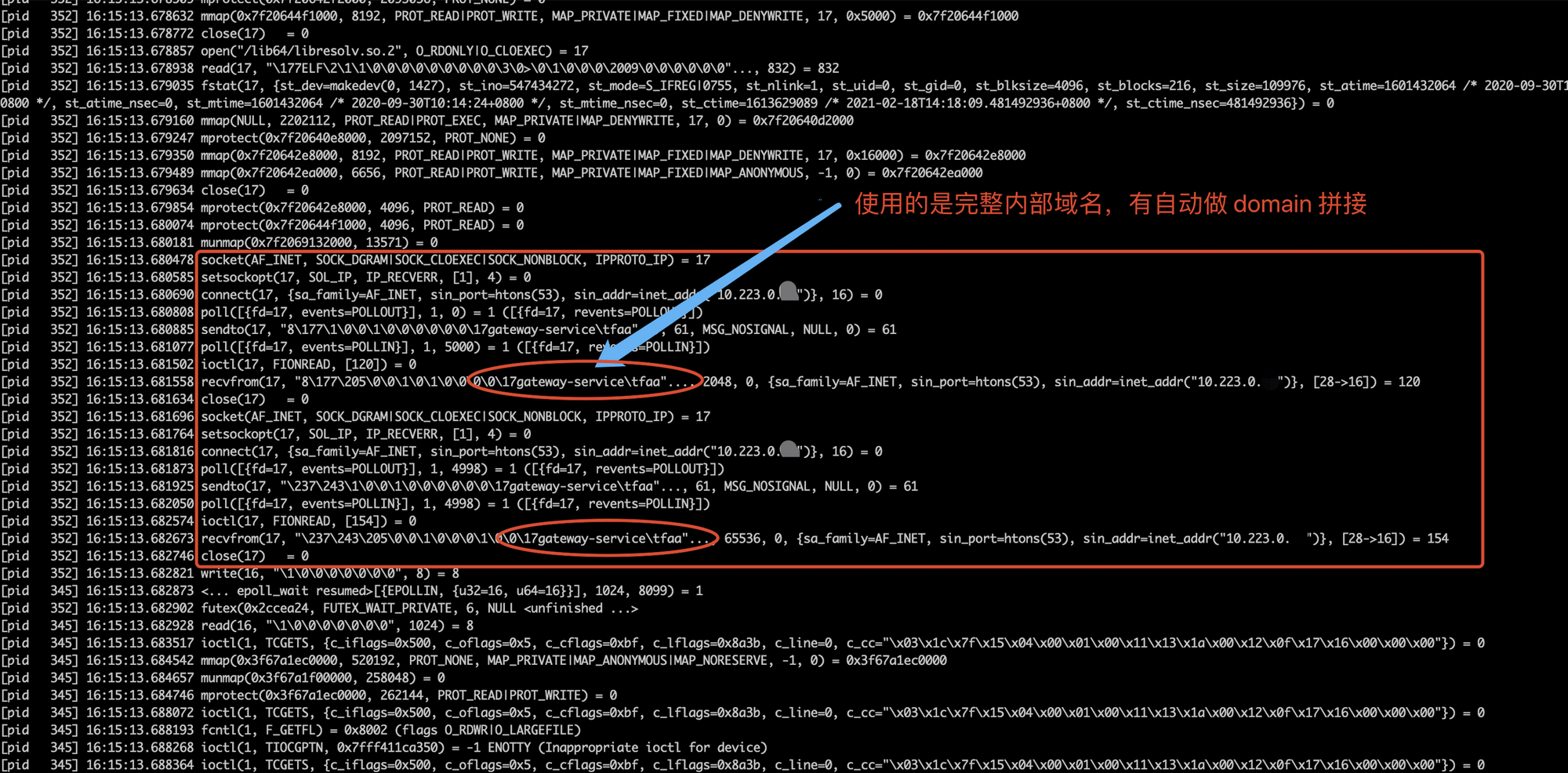
综上,除非我们使用完整的内部域名(不使用的原因本文就不细述了),否则 got 自带的 dnsCache 就相当于是失效的,
所以我们修改了 cacheable-lookup 的代码包,大致改动就是 除去 ipv6 resolver、增加 dns.lookup 缓存结果、自定义设置缓存失效时间 (默认10s)
以下是优化后的 tcpdump 日志,可以看到 dns 解析已改成 10 秒一次,并且仅执行 ipv4 dns 解析,达到预期功能。

通过灰度上线并逐步增大流量,新版本服务没有再出现 dns timeout 的错误,问题算是得到解决。
3. 总结
通过查找资料,发现在实际应用场景中, nodejs dns 超时现象还是比较多的,但原因各有千秋。
目前我们使用的大多数 nodejs http client 三方包不带有 dnsCache 功能,这也使得在部分场景下容易导致 dns 超时现象的发生。
虽然造成本次超时的根本原因是 Linux 内核 conntrack 模块在不同线程通过同一套接字同时发送两个相同 UDP 时可能会概率造成数据包丢失情况。
但是我们是可以通过添加 dns 缓存 + 重试机制 来较为完美的避免这种情况发生(当然如果您的服务是走 服务注册和服务发现 路数的,也不用关心这类问题)。
在此,比较推荐 got 这个三方包,其 hook 机制、重试、会输出 node 原生错误日志等 相对于其他包做的还是比较好的。
{kind=link}