
一、当前UI自动化存在的问题
1.1 自动化元素定位比较麻烦
- 通过xpath或selector定位比较麻烦,要手动定位很多元素,写一条用例耗时比较久
- 业务如果更新频繁,元素重新定位调试起来比较耗时
1.2 特殊元素通过传统方式定位比较困难
- 对于像全景图、漫游图等展示类的场景来说,元素定位很难
- 在工具视图中,想要找到某些元素但无法通过selector来定位,比如方案中的柜子
1.3 自动化执行的结果校验比较困难
- 图片对比失败率较高,之前大多数都是对比整张图片,无关的部分变化也会导致case失败
- 还有一些特殊的场景,不好判断用例执行的结果是否正常,比如渲染效果的展示,柜体上铺贴材质的正确性
二、通过图像识别来解决
思路:在UI自动化的运行过程中,截取图片,对当前图片进行处理,定位&校验元素
2.1 基于目标检测的模型训练与识别
2.1.1 名词解释
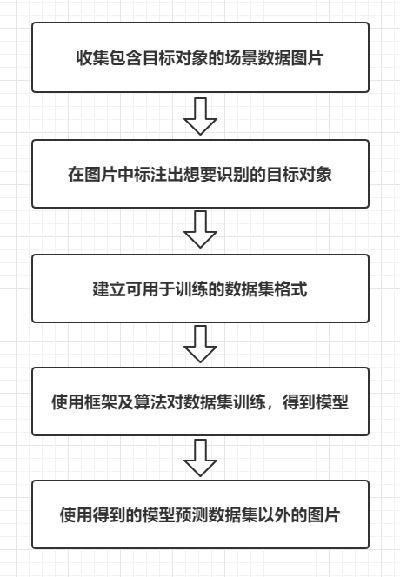
机器学习中大概有如下步骤:确定模型----训练模型----使用模型。模型简单说可以理解为函数。
确定模型是说自己认为这些数据的特征符合哪个函数。
训练模型就是用已有的数据,通过一些方法(最优化或者其他方法)确定函数的参数,参数确定后的函数就是训练的结果。
使用模型就是把新的数据代入函数求值,获取预测的结果。
目标检测:识别图片中有哪些物体以及物体的位置(坐标位置)。
目标检测的位置信息:一般由中心点坐标表示:(x_center, y_center, w, h),其中x_center,y_center为目标检测框的中心点坐标,一般都以图片左上角为原点(0,0),向右方向为x轴正方向,向下方向为y轴正方向;w,h目标检测框的宽、高。
假设这个图像是1000x800,所有这些坐标都是构建在像素层面上:

那么图中三个框的中心点坐标结果如下:
Dog:(100,600,150,100)
Horse:(700,300,200,250)
Person:(400,400,100,500)
了解了上述概念后,接下来就需要找到合适的 算法模型+训练框架,来实现我们的目标。
目前常用的目标检测算法主要有两种类型:
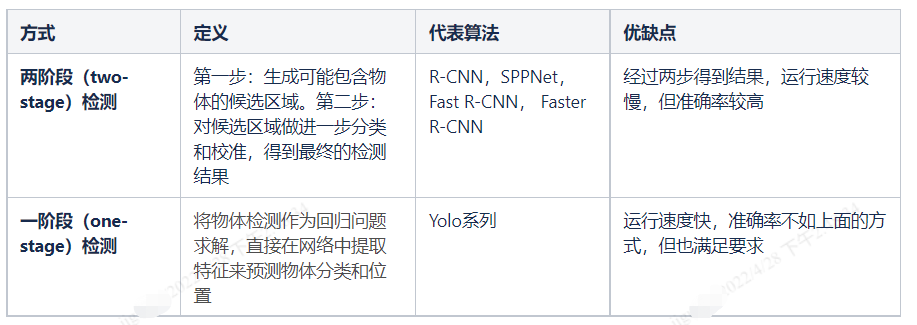
Yolo(you only look once):one-stage的目标检测算法,将物体的定位和分类在一起完成,在一个输出层回归bounding box的位置和bounding box所属类别。
目前常用的训练框架有:TensorFlow,Caffe,PyTorch,Darknet等,其中Darknet是一个较为轻型的完全基于C与CUDA的开源深度学习框架,
功能虽然不如Tensorflow和Caffe等框架那么强大,但是该框架还是有一些独有的优点:
- 易于安装
- 没有任何依赖项
- 结构明晰,源代码查看、修改方便
- 提供了方便的python接口
而且Darkent是专门为训练yolo算法而开发的框架,训练步骤简单,适配性强。
因此采用 YOLO(算法模型)+Darknet(训练框架)
2.1.2 流程图
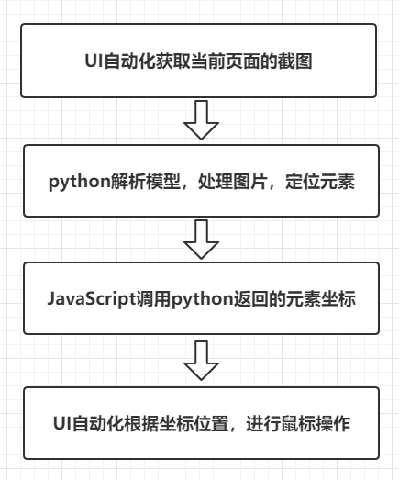
2.1.3 UI自动化实践
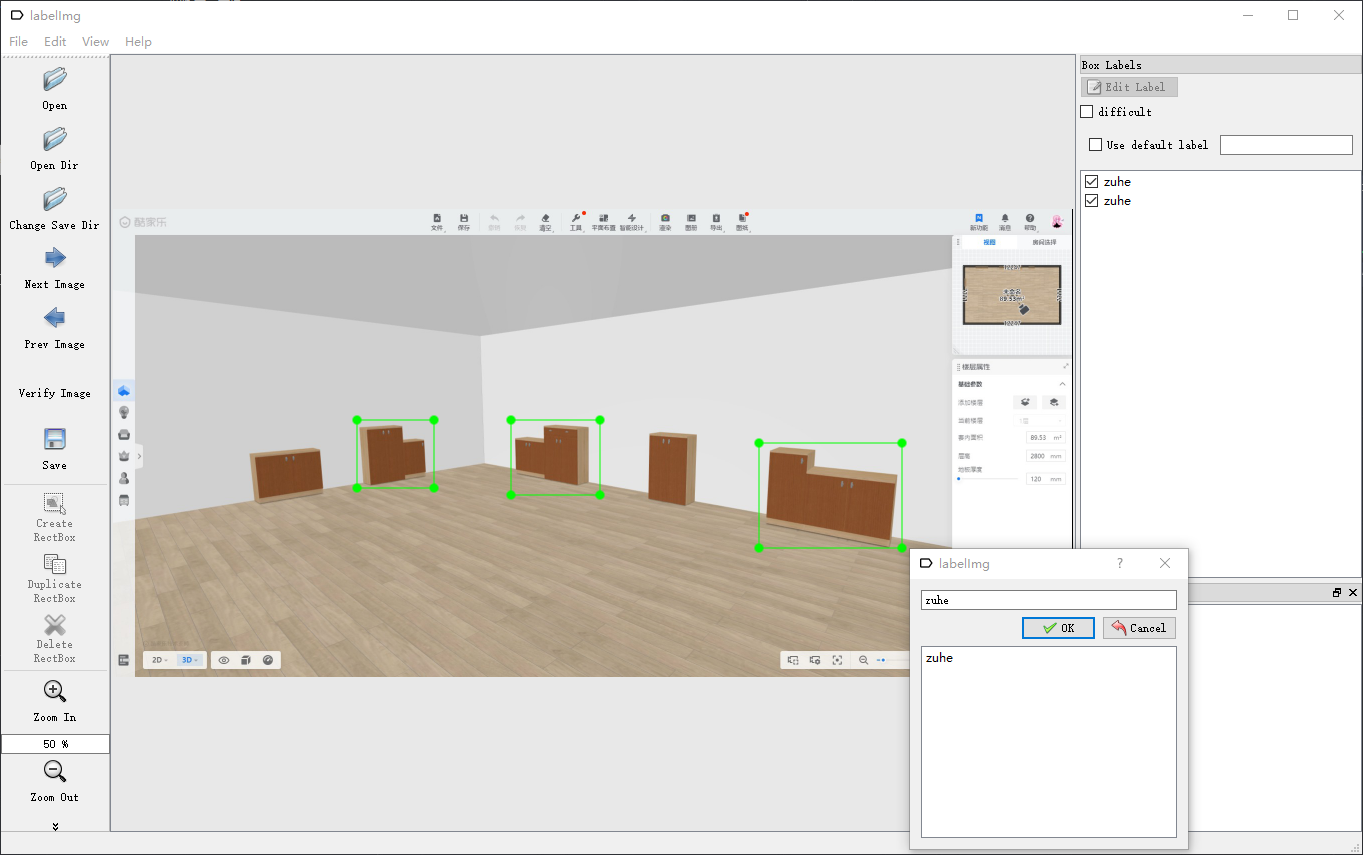
为了识别出方案中的组合柜,先获取了一些含有组合柜的场景图片,然后使用Labelimg软件手动标注一下方案中的组合柜数据,生成可用于框架训练的数据集格式,用于后续训练。
收集数据:


标注想要识别的元素:
全部标注完成之后,就建立了完整的数据集,然后使用目标检测的神经网络框架对该数据集进行训练,得到想要的模型。通过训练会得到 网络结构.cfg文件,权重.weights文件和模型类别标签文件.names 三个文件,后续应用模型的话,只需要解析这三个文件就能够从未知图片中成功识别出想要的元素。
训练之后的检测效果如图:
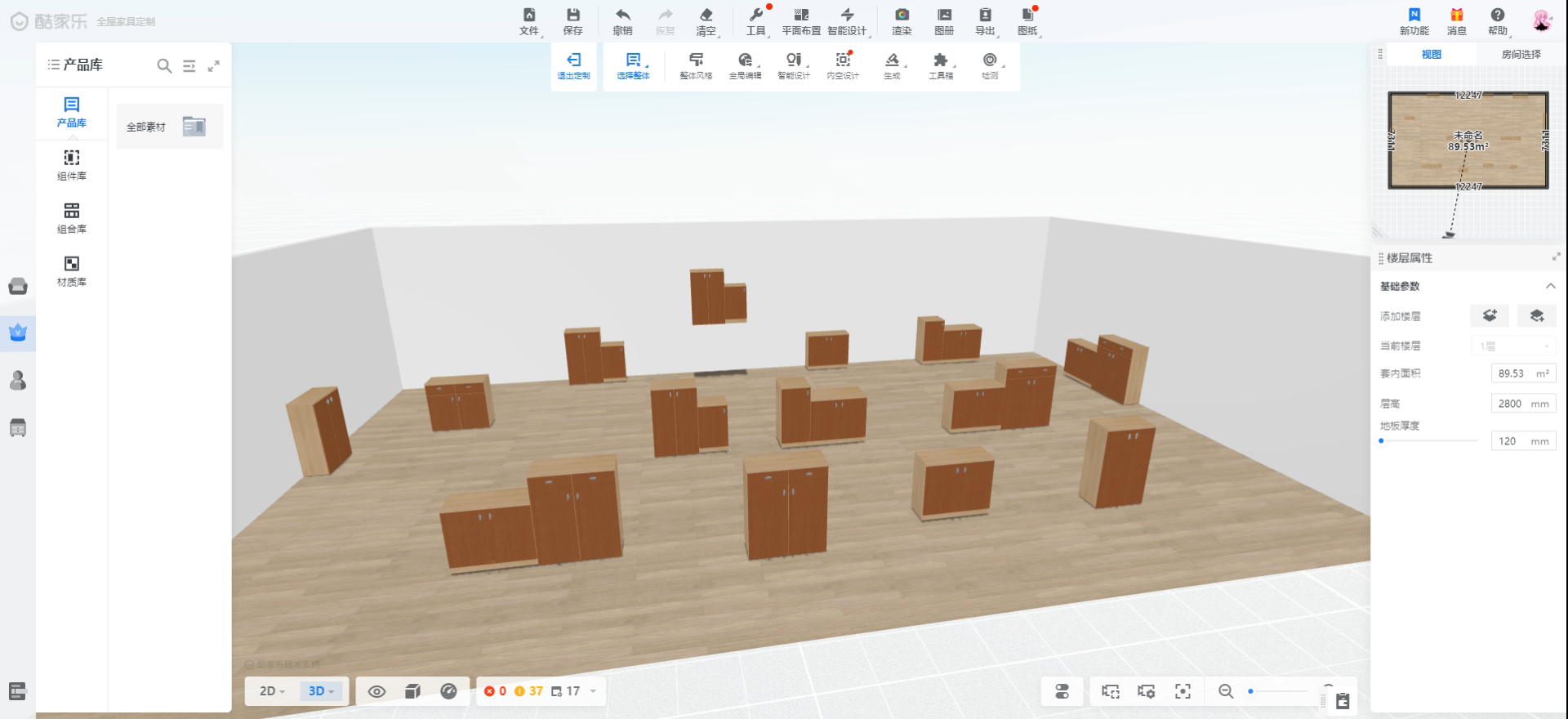
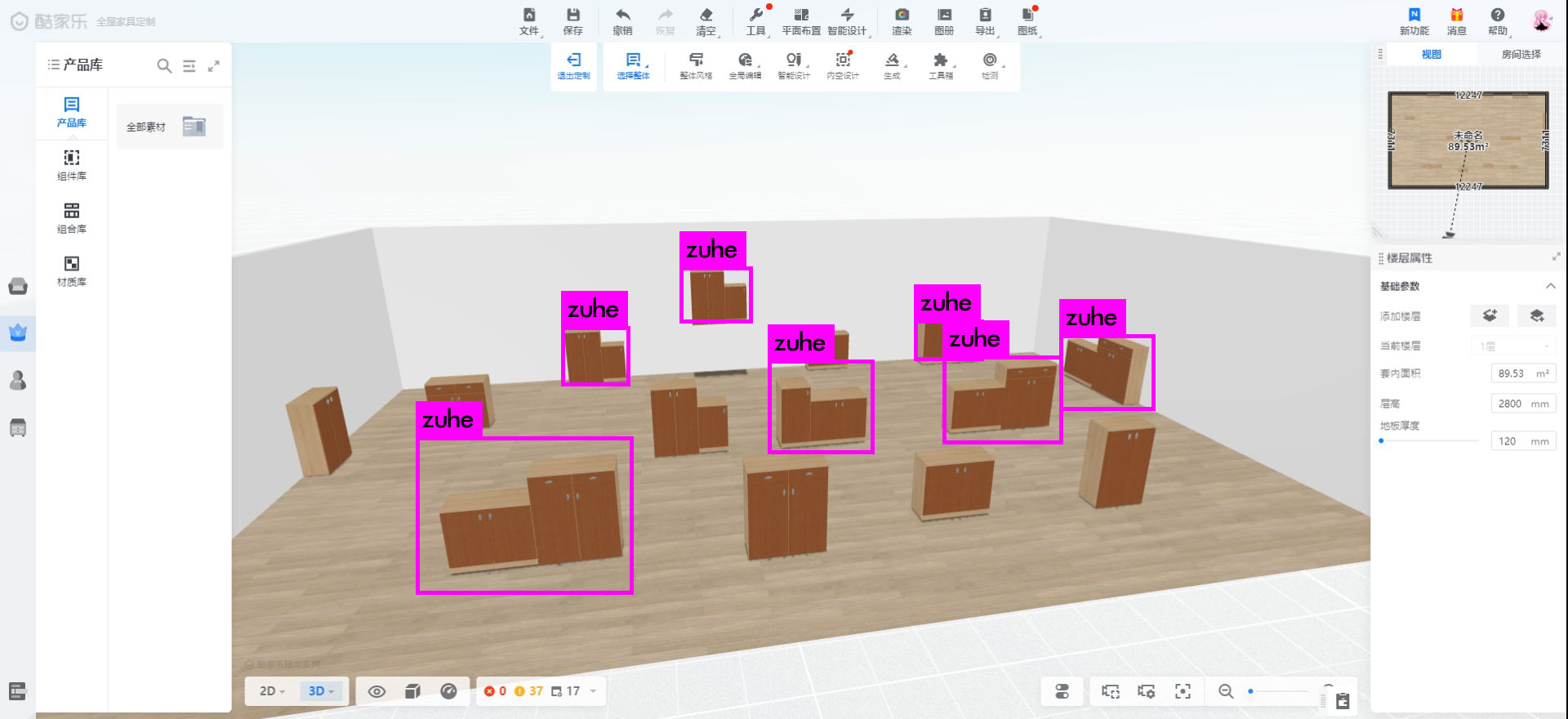
由于本次训练只收集了100张图片(包含200多个目标)用于训练,因此识别的精度不是很高,有些组合模型没有被识别出来,但是从中可以看出大多数情况下是可以把组合模型和单个模型区分出来的。
因为解析训练得到的三个文件需要opencv的库,而python对于引入opencv库很方便,因此需要安装python环境,来运行python代码,而且还需要安装opencv的库:
pip install opencv-python
pip install opencv-contrib-python
同时由于UI自动化框架用的是js代码,也需要安装Nodejs环境,来保证UI自动化框架的运行。最终就可以使用js代码,调用执行python文件获取想要的结果:
调用python文件的代码
const { execSync } = require("child_process"); //调用child_process模块(同步进程)
const syncGet = (url) => {
var data = execSync(`python ${url}`).toString(); //执行python文件,获取结果到data
data = data.split(/\s*[\r\n]+\s*/).filter(function(n){return n}) //将data以换行符分割,并去除空数组
position=data[0].split(" ")
return position;
};
var position = syncGet("test-xiugai.py");
console.log(position)
然后在UI自动化框架中,完成一个case,启动浏览器,进入方案,识别出场景中的组合柜,拖动组合柜到指定坐标位置
test("获取组合柜的坐标并移动到指定坐标", async () => {
let buffer = await pyBell.screenshot()
await pyBell.screenshot({path: "./screenshot/11.png"}) //截图存到指定目录
const { execSync } = require("child_process");
const syncGet = (url) => {
var data = execSync(`python ${url}`).toString();
data = data.split(/\s*[\r\n]+\s*/).filter(function(n){return n})
position=data[0].split(" ")
return position.map(Number);
};
var position = syncGet("__tests__/test-xiugai.py"); //执行python文件,返回坐标
await pyBell.mouseClick({x:position[2], y:position[3]}, {button: "left"}) //鼠标左键点击返回的坐标
await pyBell.sleep(2000)
await pyBell.mouseDown({button: "left"}) //鼠标在当前坐标左键按下
await pyBell.mouseMove(undefined,{x:position[2]+300, y:position[3]}, 50) //鼠标从当前坐标移动到x值+300的位置
await pyBell.mouseUp({button: "left"}) //鼠标左键松开
}, 150000)
最终运行效果:
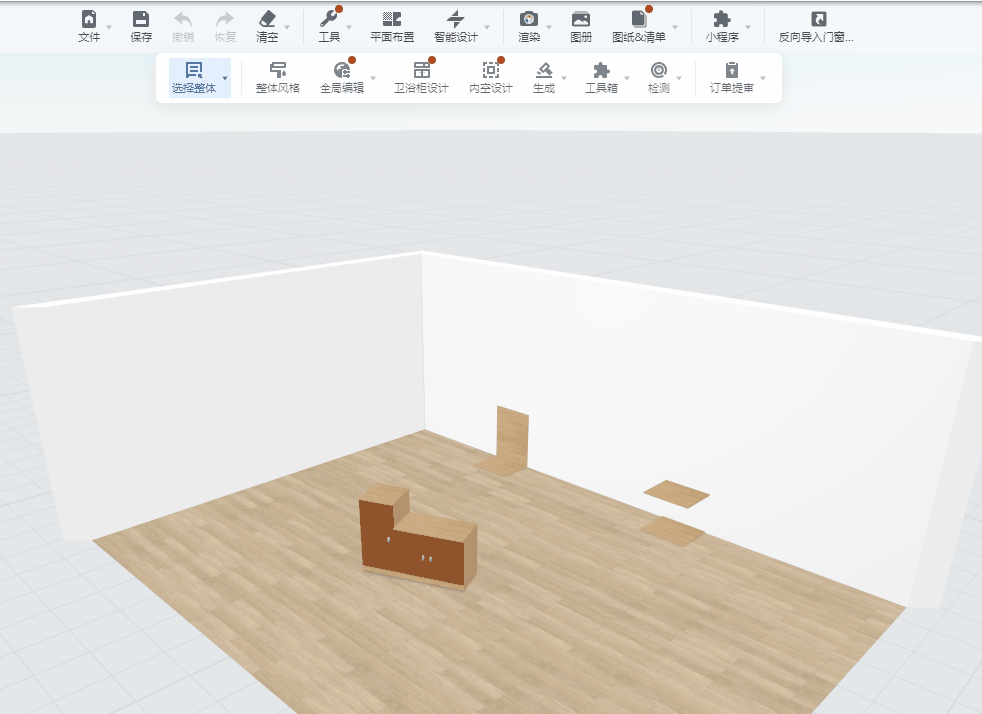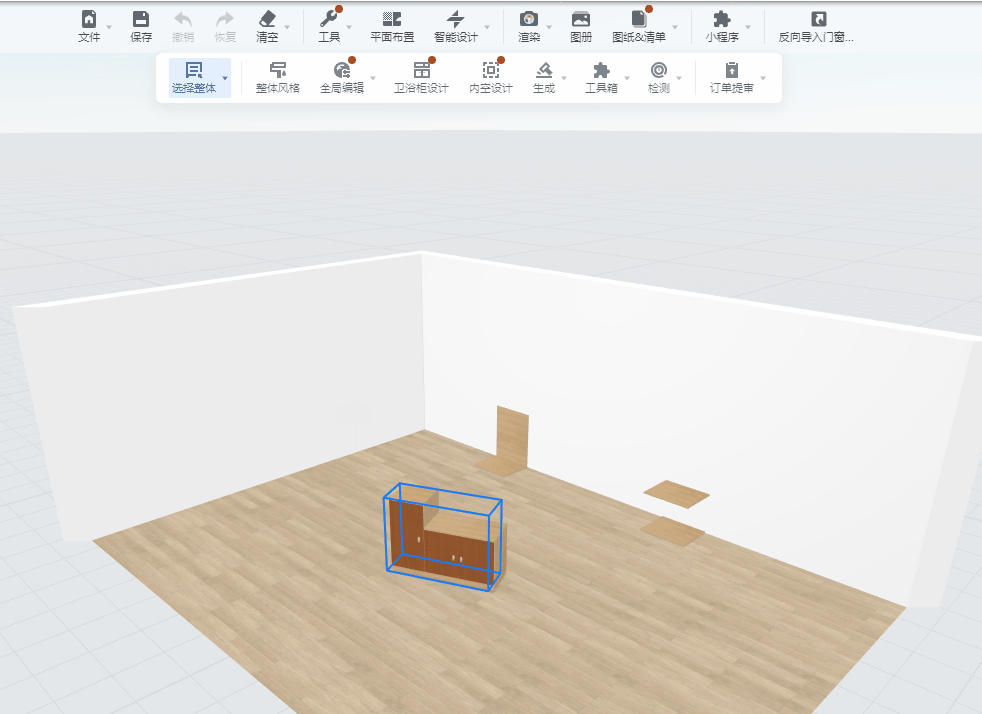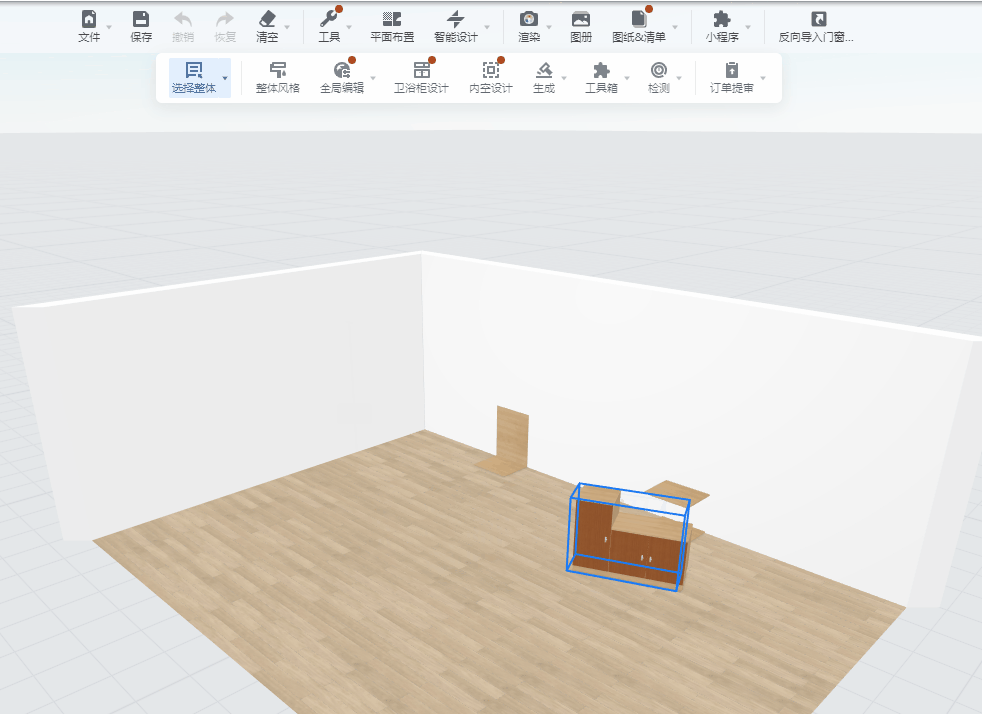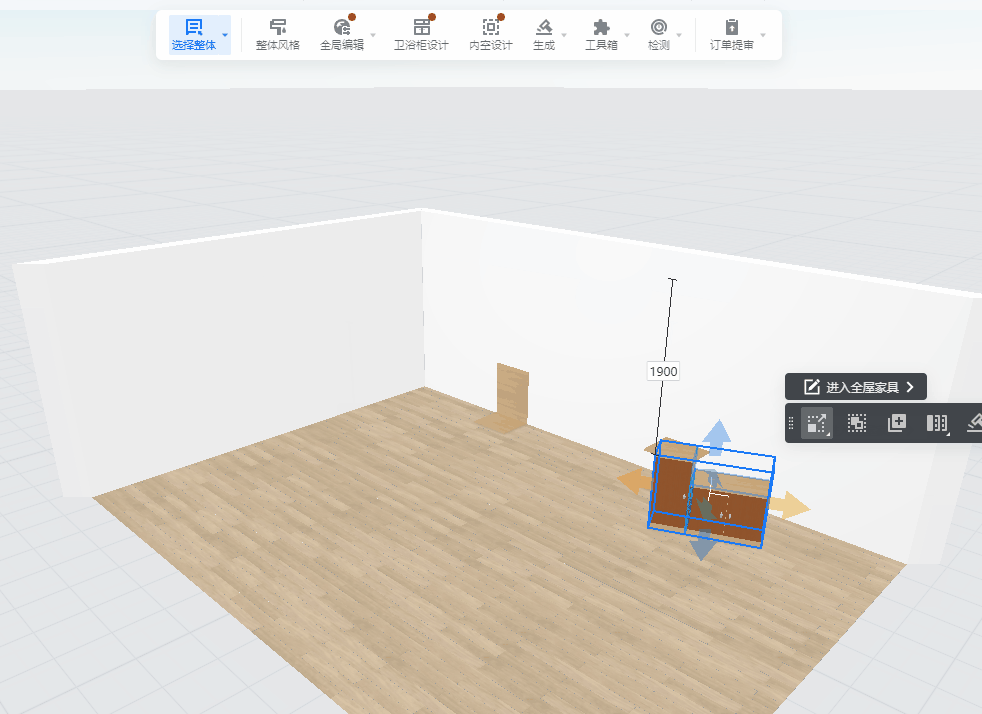
2.2 基于opencv的模板匹配与识别
2.2.1 名词解释
OpenCV是一个跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,
同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
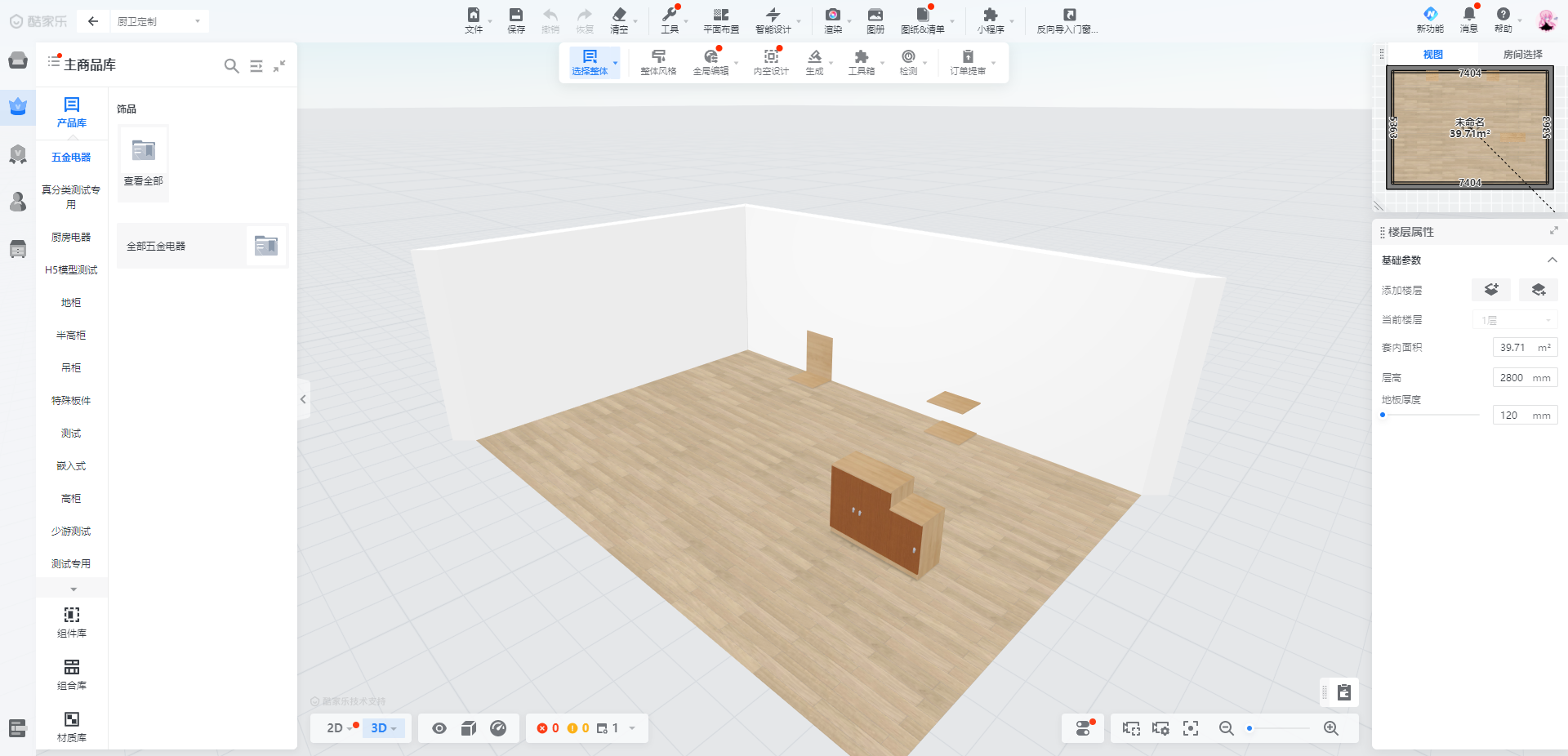
模板就是一副已知的小图像,而模板匹配就是在一副大图像中搜寻目标,已知该图中有要找的目标,且该目标同模板有相同的尺寸、方向和图像元素,通过一定的算法可以在图中找到目标,确定其坐标位置。
原图:
模板:

匹配后的图:
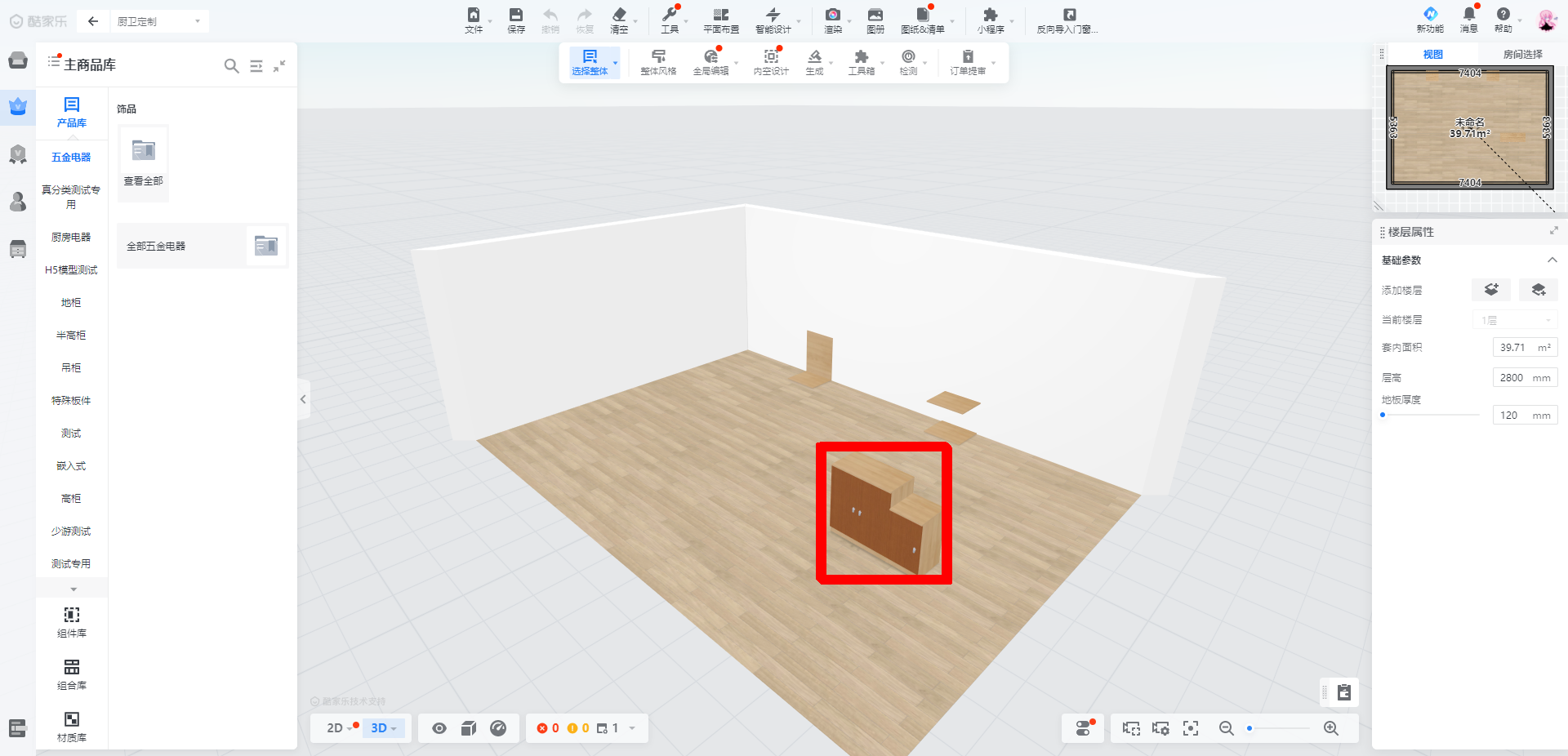
通过模板匹配可以获得该模板图片在原图中的位置坐标。
2.2.2 流程图
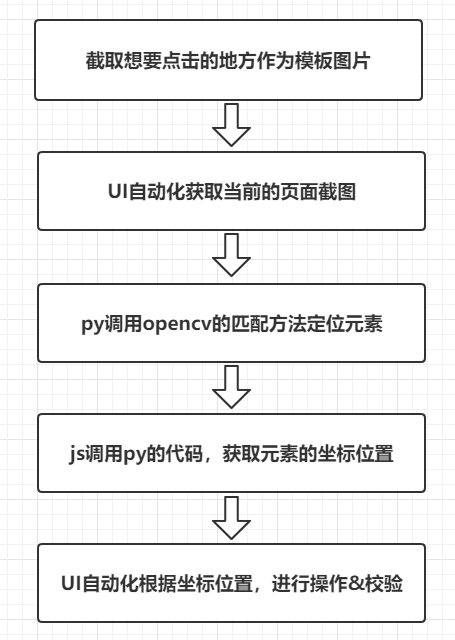
2.2.3 UI自动化实践
以“测试定制安装编码”case来举例说明,进入定制环境后,首先需要hover”文件“,然后hover”导出安装编码“,再点击”全屋家具“,最后判断是否出现生成完成的图标,来决定case的通过与否。
当前场景中的鼠标的操作有两种:hover和click。因此可以封装两个函数HoverByPicture和ClickByPicture,只需要传入想要点击的模板图片即可。为了验证结果的正确性,还需要一个函数CheckByPicture,来判断case的正确性。

实际的case如下:
test("opencv检测test", async () => {
await HoverByPicture('./template/wenjian.png'); //hover 文件
await HoverByPicture('./template/daochuanzhuang.png'); //hover 导出安装编码
await ClickByPicture('./template/quanwujiaju.png'); //点击 全屋家具
await pyBell.sleep(5000)
let bool = await CheckByPicture('./template/jieguo.png') //判断结果中是否出现 预期的结果图
expect(bool).toBe(true)
}, 150000)
通过传入模板图片来进行点击的ClickByPicture函数为:(HoverByPicture与CheckByPicture原理相同)
async function ClickByPicture(str) { //通过传入模板图片,判断模板在图片中的坐标,并鼠标左键点击
await pyBell.screenshot({path: "./screenshots/click.png"}) //截取当前页面的图存到指定目录
const { execSync } = require("child_process");
const syncGet = (url) => {
var data = execSync(`python `+url+' '+str).toString();
data = data.split(/\s*[\r\n]+\s*/).filter(function(n){return n})
let position=data[0].split(" ")
return position.map(Number);
};
let position = syncGet("pipei.py ./screenshots/click.png"); //调用执行python文件,返回模板在图片中的坐标
await pyBell.mouseClick({x:position[0], y:position[1]}, {button: "left"}) //鼠标左键点击返回的坐标
}
pipei.py的代码为
import cv2
import numpy as np
import sys
one=sys.argv[1]
two=sys.argv[2]
img_rgb = cv2.imread(one) #读取大图
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY) #转化为灰度图像
template = cv2.imread(two,0) #读取小图
w, h = template.shape[::-1] #获取小图的w和h
res = cv2.matchTemplate(img_gray,template,cv2.TM_CCOEFF_NORMED) #将小图在大图上进行模板匹配,res越接近1,说明匹配程度越高
threshold = 0.9 #设置一个阈值,超过这个阈值时,被认为是需要匹配的对象
loc = np.where( res >= threshold)
x=loc[0]
y=loc[1]
if len(x) and len(y):
for pt in zip(*loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2)
print(pt[0]+w/2,pt[1]+h/2) #如果在大图中匹配到了模板,那么打印出模板在大图中的中心坐标
else:
print(0,0) #如果在大图中没有匹配到模板,那么说明模板在原图中不存在,打印出坐标0,0
最终运行效果:
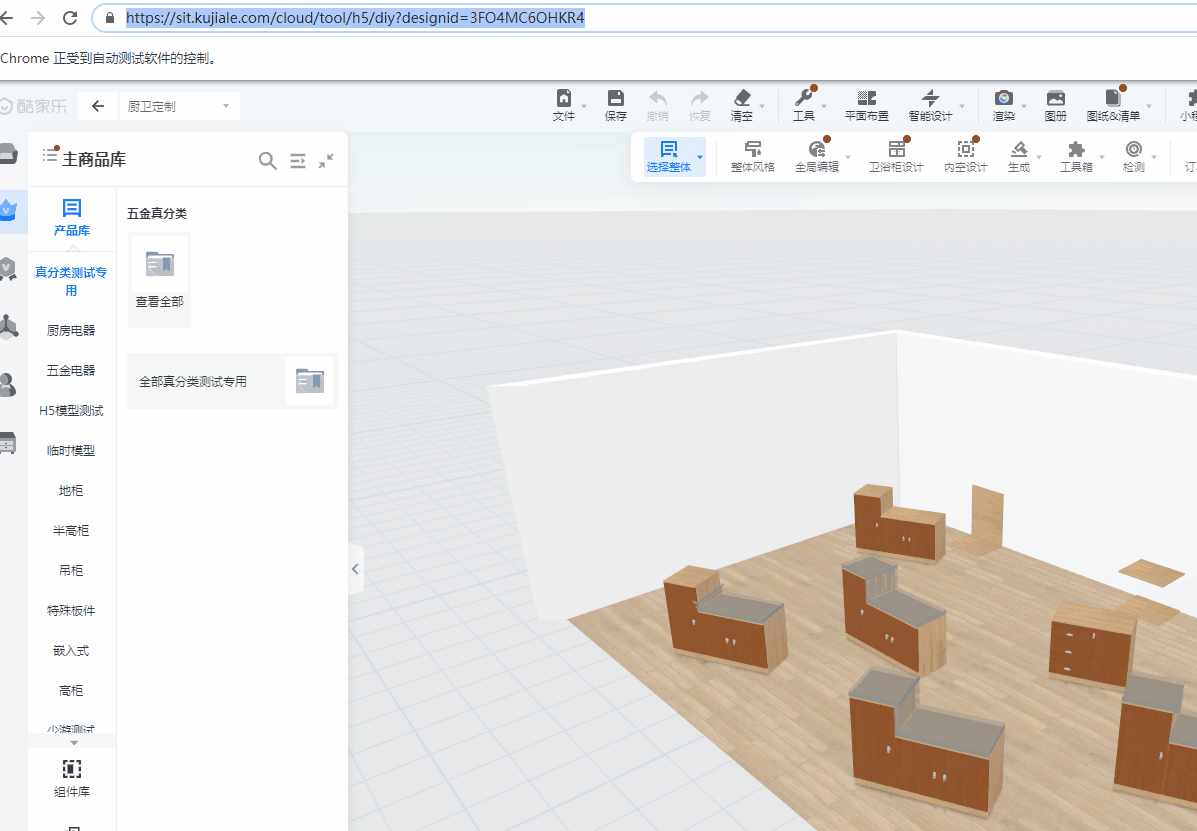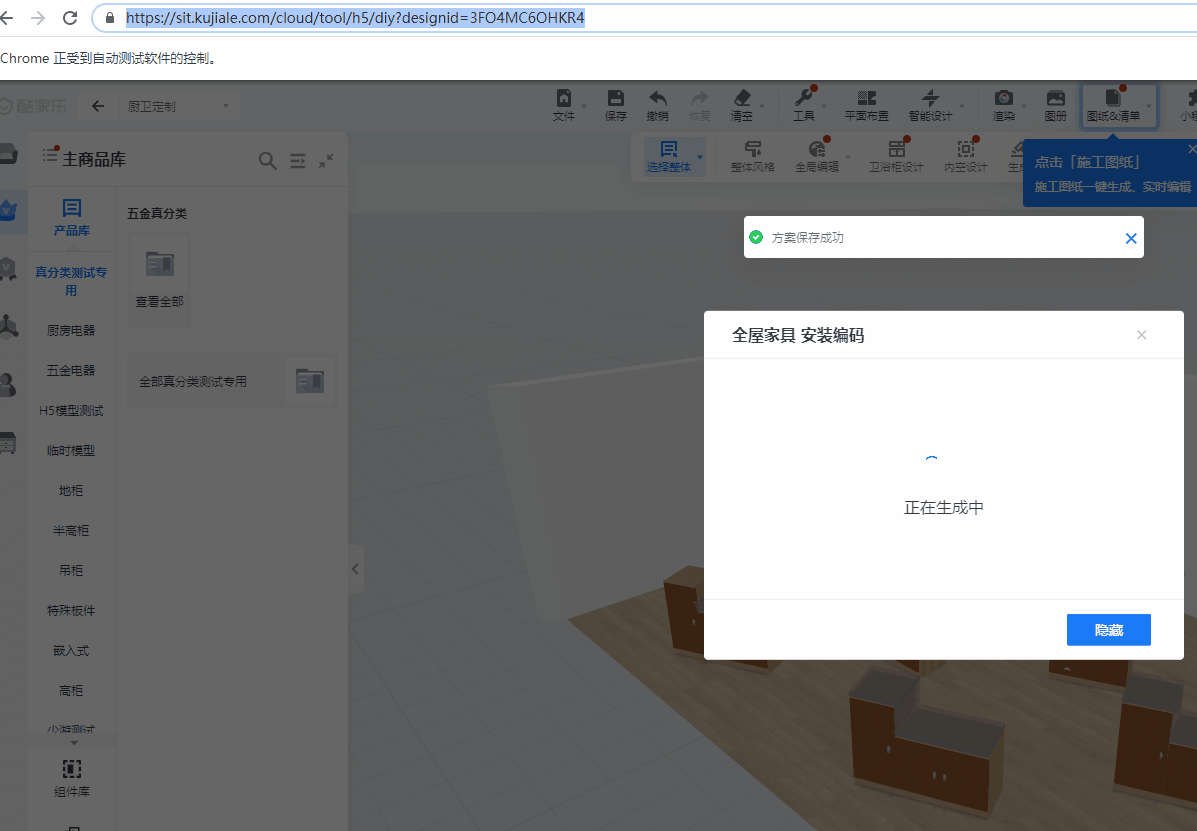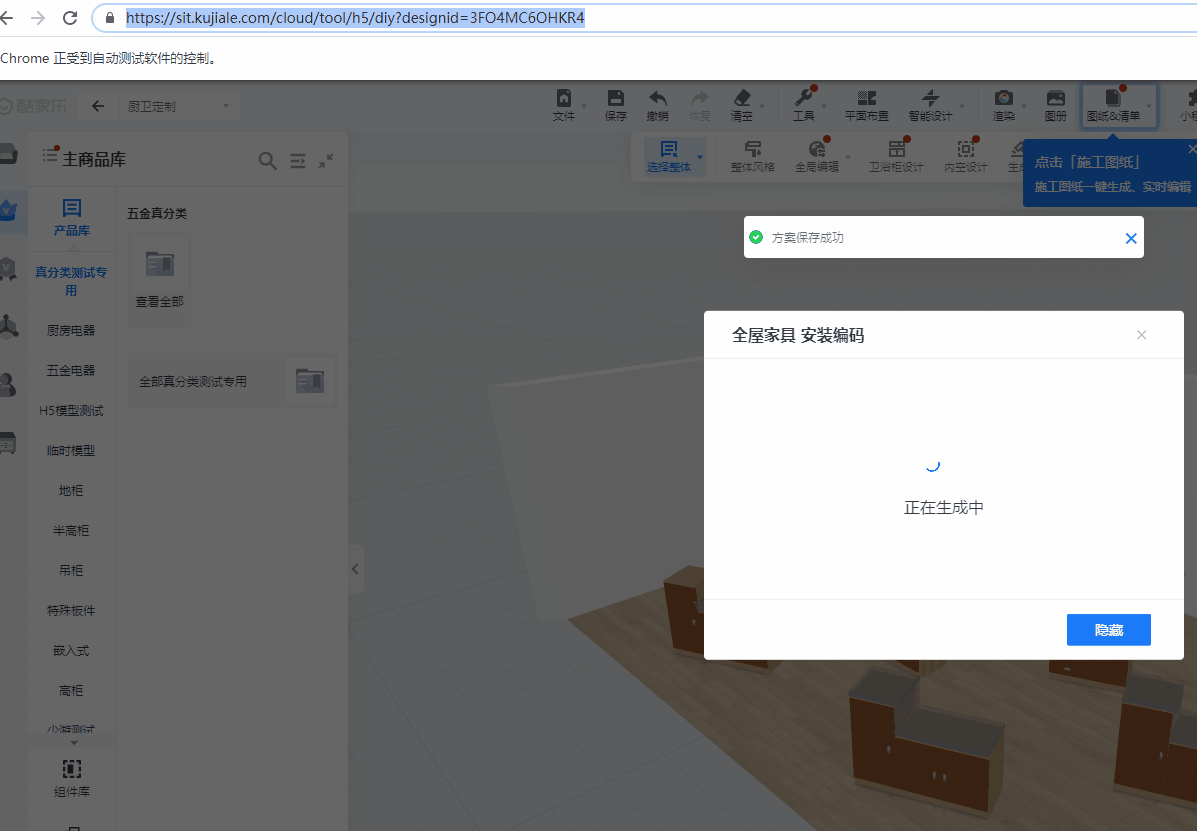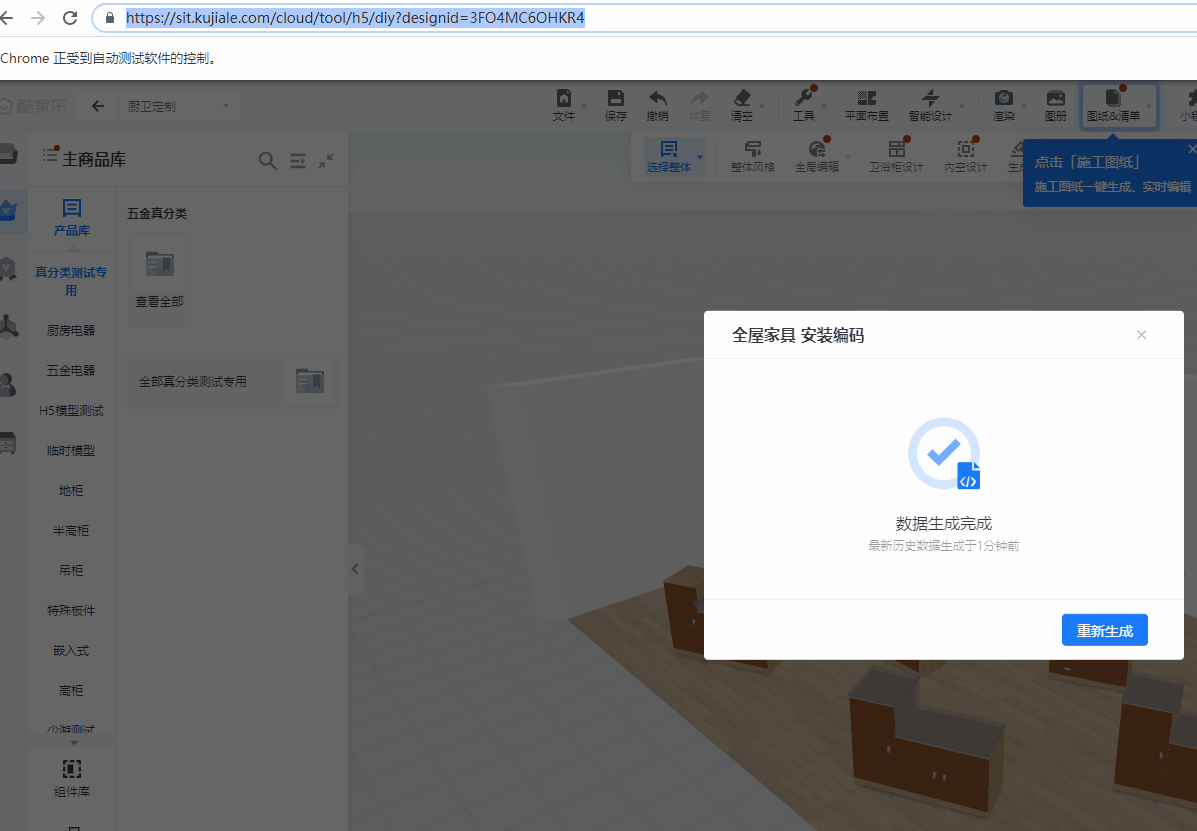
2.2.4 改进优化
将某个case操作路径下所需要鼠标操作地方截图保存下来,放在一个文件夹下,并按照操作顺序命名:01.png,02.png,03.png.........,jieguo.png
然后封装一个函数,执行case的时候自动遍历获取该文件夹下的所有图片,按照命名顺序依次点击,最后一张jieguo.png图用来check,判断结果。
有时候会遇到hover的操作,或点击后由于网络加载需要等一会才能出现结果的情况时,可以在起文件名字的时候加个字母“h”表示是hover操作,加个字母“t”表示执行完click操作后,等待2s。
这样,完成一个UI自动化case只需要截图保存就行了,降低了编写难度,完成速度也更快,后续有变化也只需要维护该文件夹。
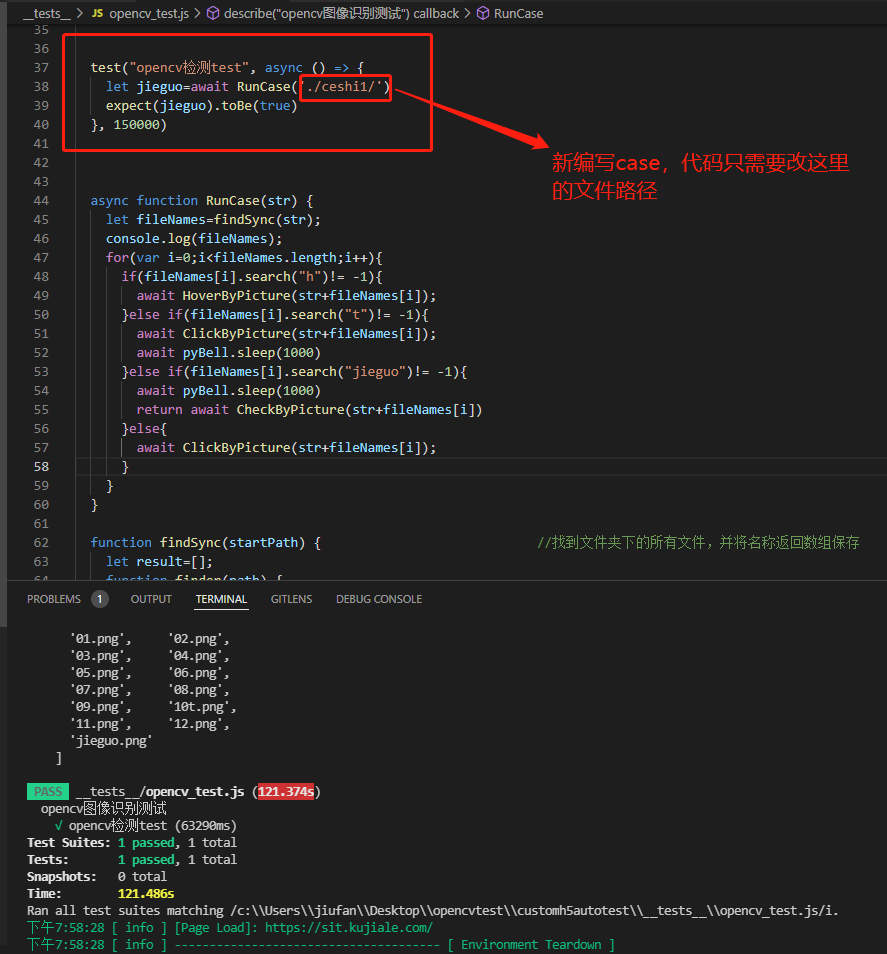
test("opencv检测test", async () => {
let jieguo=await RunCase('./ceshi1/') //运行函数,只需要传入case的文件夹地址
expect(jieguo).toBe(true)
}, 150000)相关函数:
async function RunCase(str) { //按顺序读取文件夹下的图片,并判断要对图片进行什么操作
let fileNames=findSync(str);
console.log(fileNames);
for(var i=0;i<fileNames.length;i++){ //遍历文件夹中的文件名称,确定要操作的模板图片
if(fileNames[i].search("h")!= -1){ //如果文件名字包含h,那么执行hover操作
await HoverByPicture(str+fileNames[i]);
}else if(fileNames[i].search("t")!= -1){ //如果文件名字包含t,那么执行完click操作后,等待1s
await ClickByPicture(str+fileNames[i]);
await pyBell.sleep(2000)
}else if(fileNames[i].search("jieguo")!= -1){ //如果文件名包含jieguo,那么执行check操作
await pyBell.sleep(2000)
return await CheckByPicture(str+fileNames[i])
}else{ //默认执行click操作
await ClickByPicture(str+fileNames[i]);
}
}
}
function findSync(startPath) { //找到文件夹下的所有文件,并将名称返回数组保存
let result=[];
function finder(path) {
let files=fs.readdirSync(path);
files.forEach((val,index) => {
let fPath=join(path,val);
let stats=fs.statSync(fPath);
if(stats.isDirectory()) finder(fPath);
let fPath1=path0.basename(fPath);
if(stats.isFile()) result.push(fPath1);
});
}
finder(startPath);
return result;
}根据以上思路,试验一个case,测试”自由编辑下绘制矩形后生成台面“是否正常的case;该case的操作路径比较长:
在厨卫定制下,
1.点击生成,2.点击台面,3.点击自由编辑,4.点击绘制矩形,
5.点击方案中一点,6.点击方案中另一点(5,6是自由绘一个矩形),7.点击开始生成,8.点击选择前挡水,
9.点击选择前挡水类型,10点击选择材质,11.点击选择材质类型,12.点击生成
查看最后结果;这个case总共需要点击12次;建立文件夹如下:
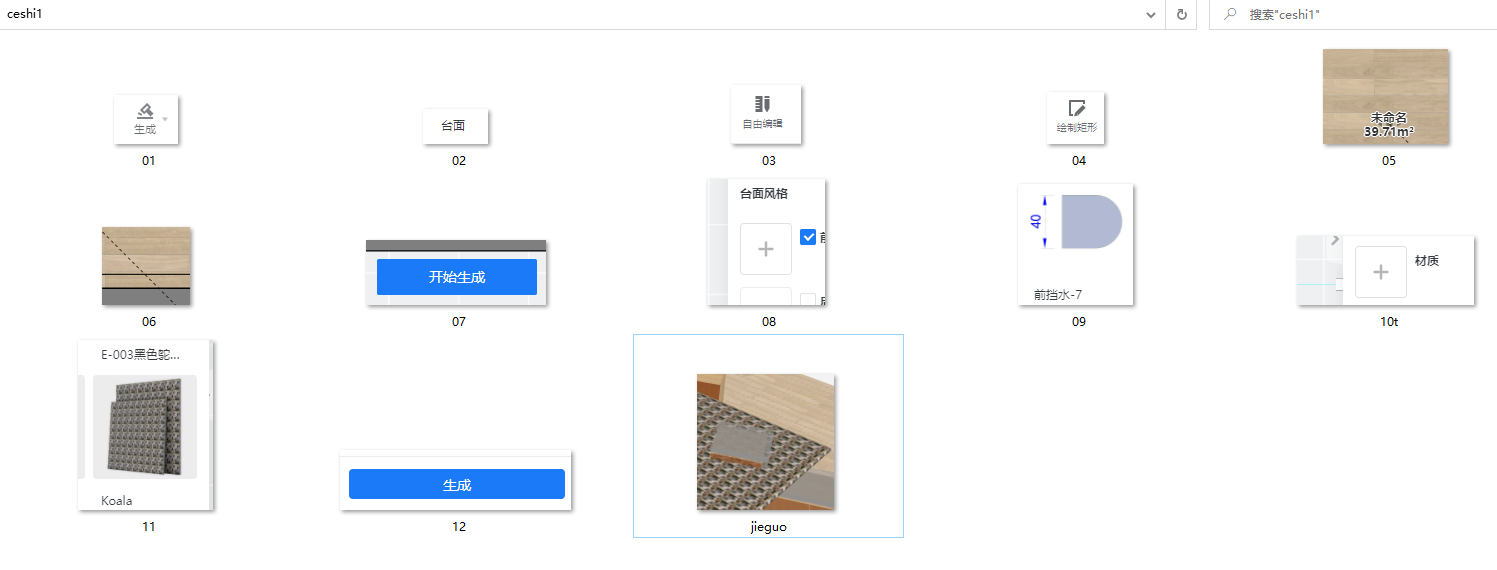
编写case:
最终case的运行效果如下:
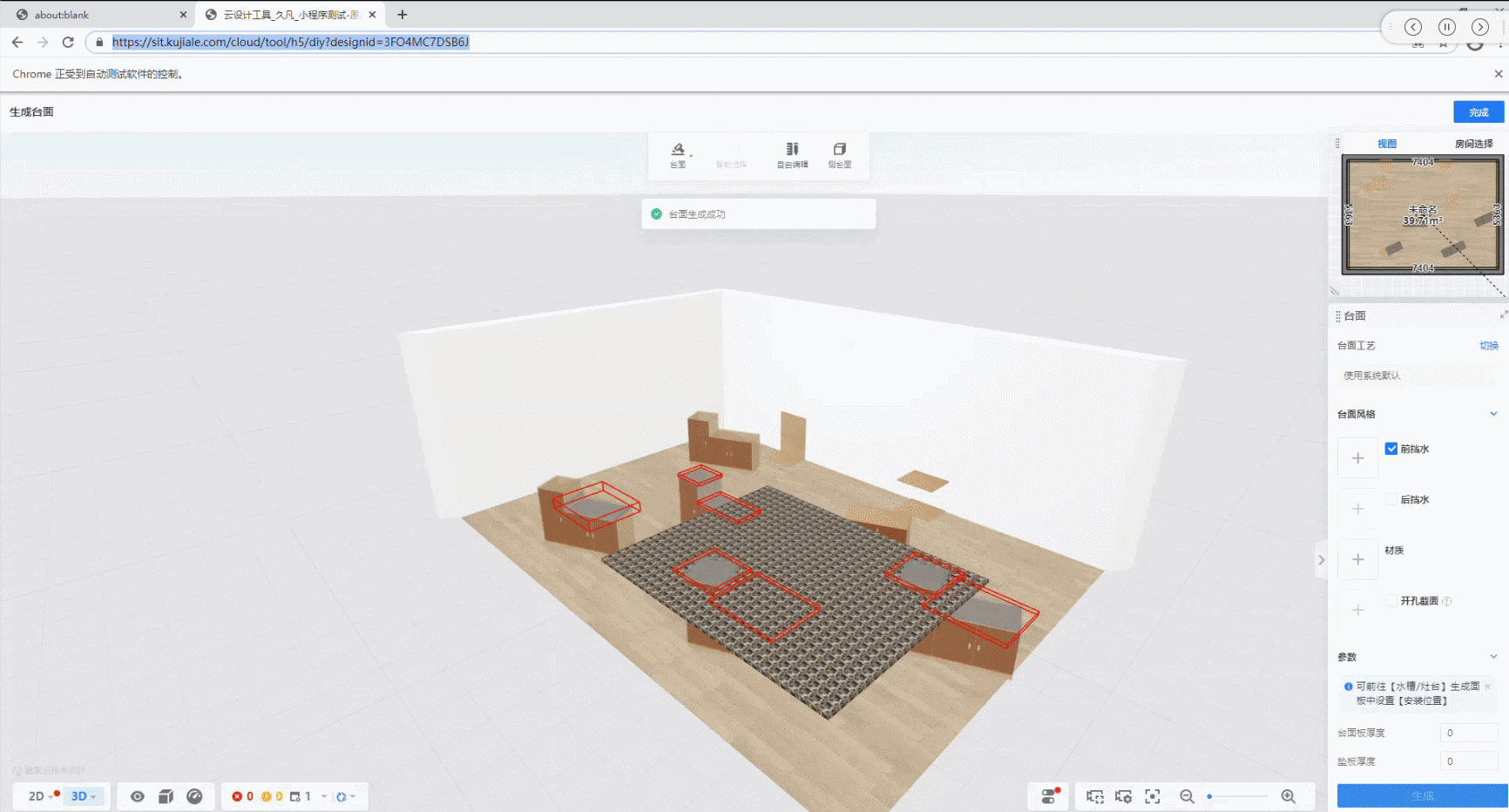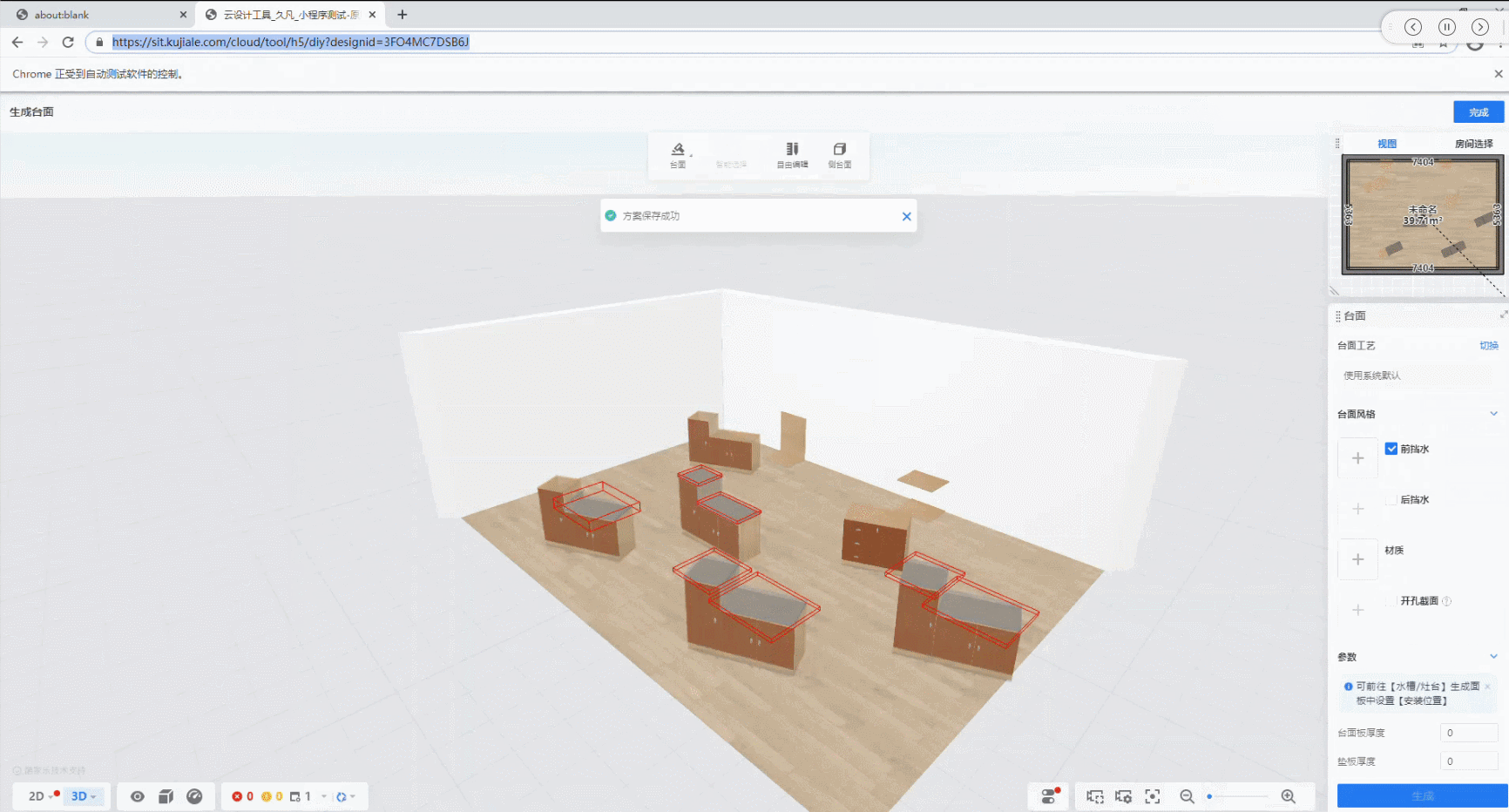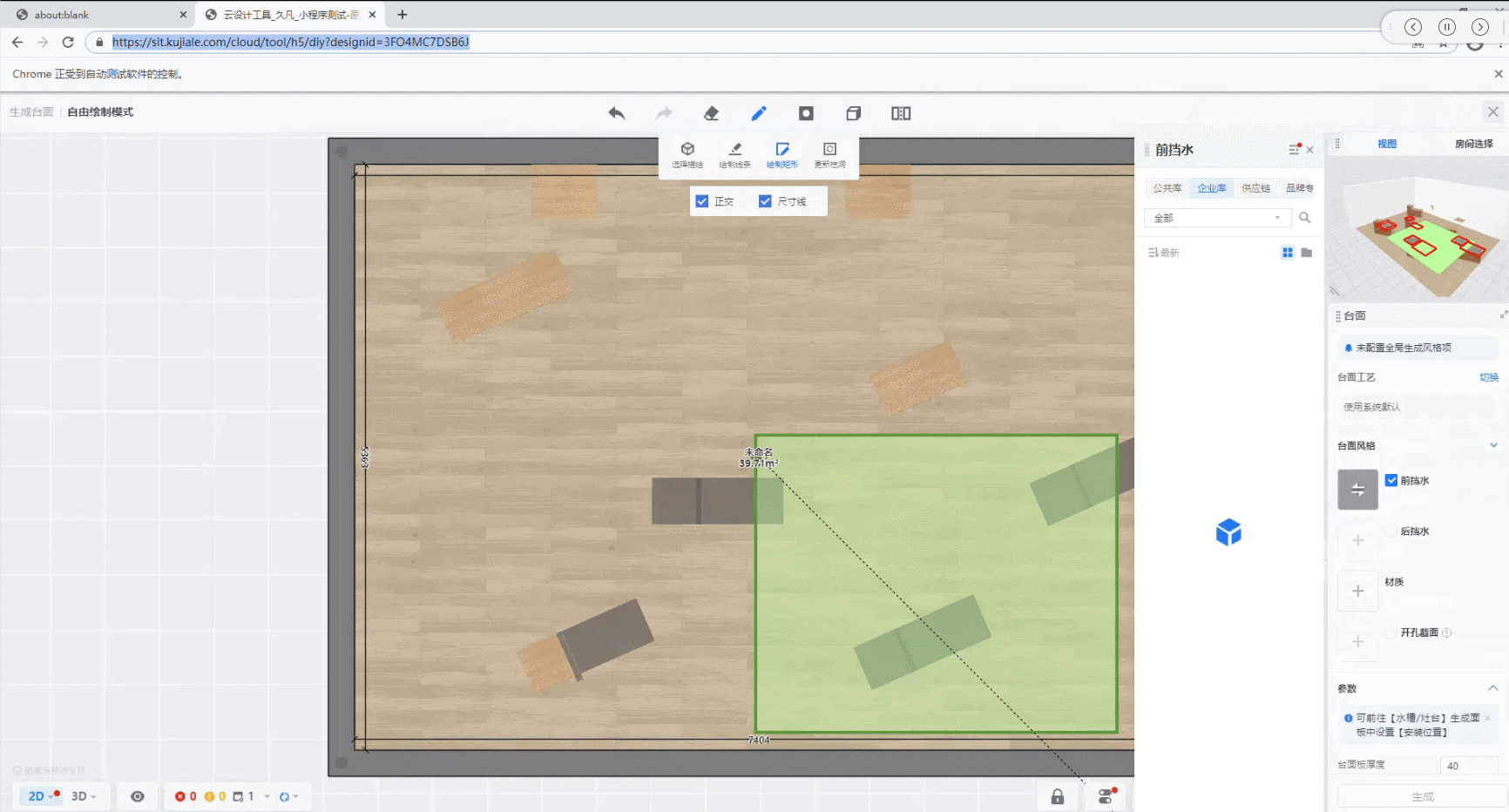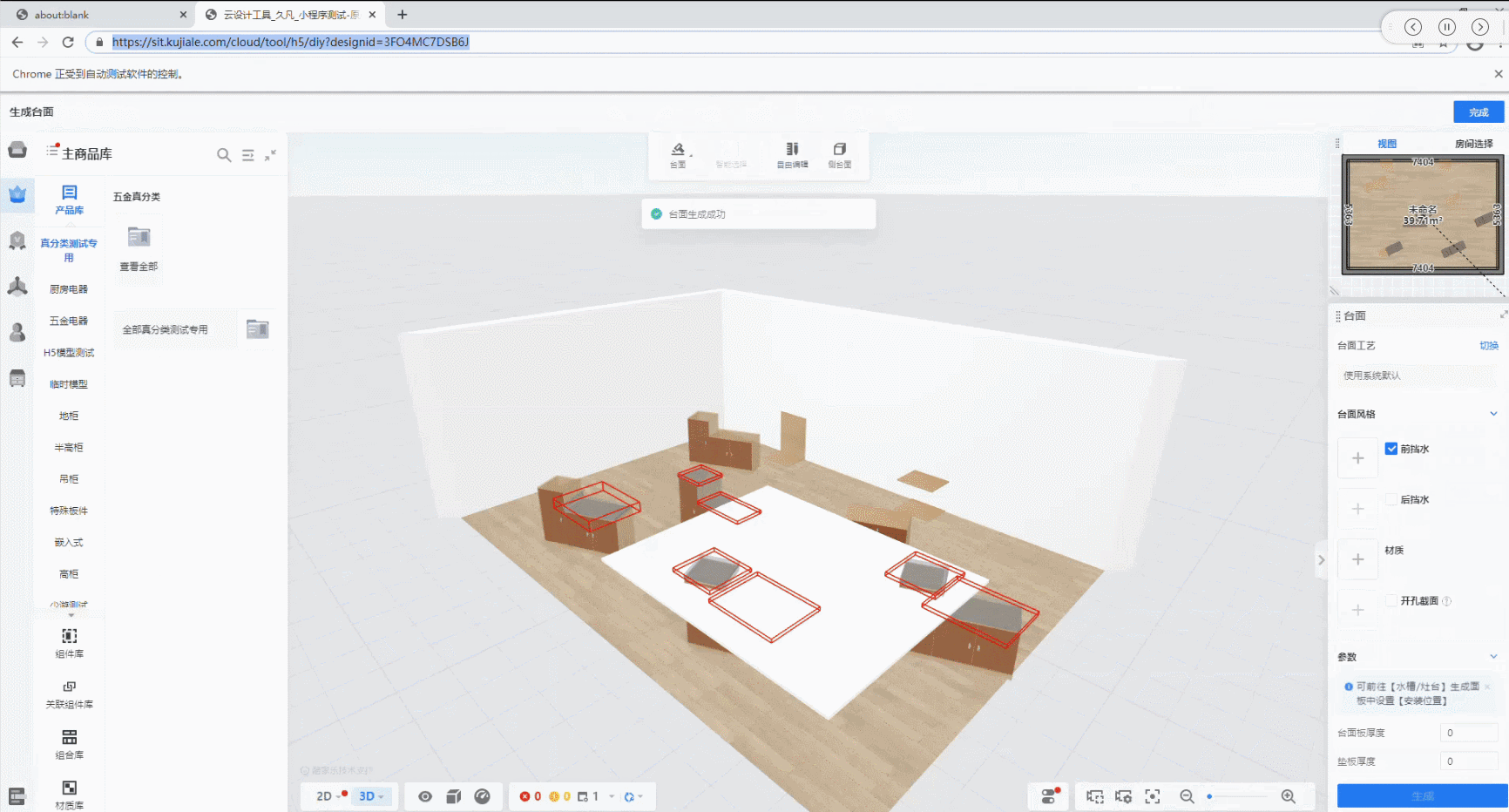
从中可以看出,只要在操作点击路径上的元素变化不大,编写一个UI自动化case,使用该方法只需要保存点击操作路径上的截图,然后保存在同一个文件夹下,对函数传入该文件夹地址,最后校验结果就行;这种方法只适用于所有操作都是鼠标点击的情况,有些case中间还会输入文本,这种情况后续还要再想办法解决。
相比于以前通过Xpath定位,至少需要定位十几次,而且定位比较麻烦,找很多selector,并且需要写很多行代码,完成这样一条操作路径比较长的case,需要花费更多时间。而截图的方法能很快完成一条UI自动化case。
三、总结
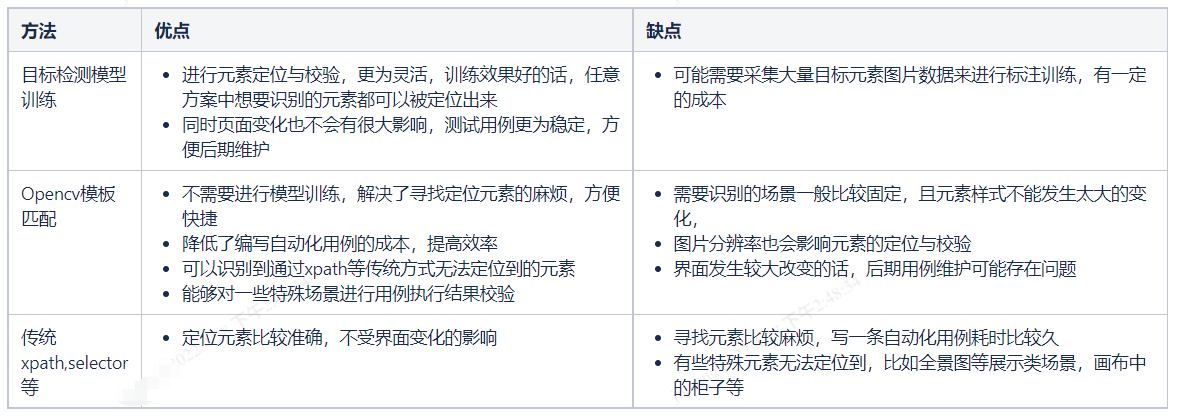
基于图片识别的UI自动化适用于那些界面UI变化不大的业务场景,可以很大提升UI自动化case的编写效率,降低UI自动化的复杂度;对于一些定位比较困难的元素和用例执行结果的校验上,也能够提供很大的帮助。但是对于UI变化比较频繁的业务,用该方法可能需要维护的成本更大。需要结合自身的业务场景来选择最适合的方法,或者多种方法结合使用,提升UI自动化的效能,发挥更大的作用。
推荐阅读
