
一、背景
- 随着公司的业务规模逐渐扩大,用户量和业务的复杂度日益增加,各业务组需要把统一库中业务相关的表迁移到自己的库中,方便维护。
- 随着中台业务的发展,模数据的日益增加,单一的DB架构就会出现一系列问题,比如响应过慢,有时候甚至会出现超时,分库分表,接es改造,被提上日程。
二、分析与设计
2.1 采用水平拆分
原因:表的数据会越来越大,查询速度会慢,所以需要针对这些表进行水平切分,单表中数据量增长出现的压力。如图水平拆分示意图:把一张表根据主键id,拆分成多张表。
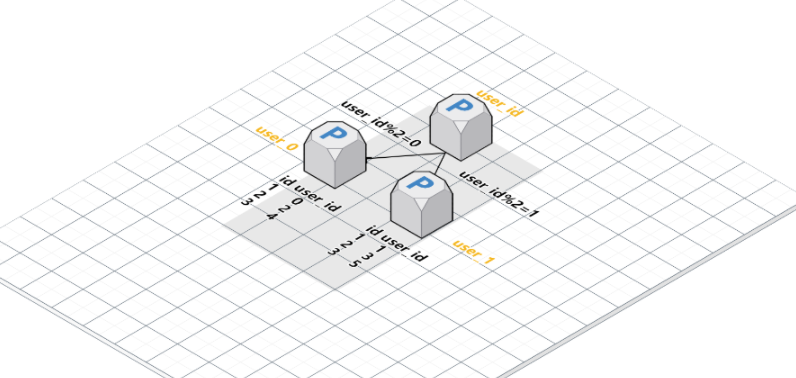
问题:多张表使用唯一的自增id。
解决方式:使用tddl-sequence。每个节点的内存取的ID段都是不同的,能保证主键不会冲突。
风险考虑:使用tddl-sequence就能完全保证主键不会冲突么?为此也通过学习一些会冲突的案例,来帮助排查问题的根本原因。
思路:
- 是否有手动的插入数据,造成了主键冲突
- 是否修改过sequence的value,造成了主键冲突
- 是否是代码的多线程原因,造成主键冲突
2.2 分表数量,分表字段
主要是x、y拆分出来,并做水平分表处理
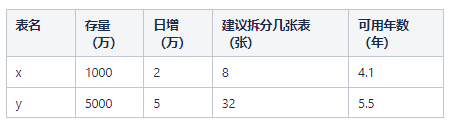
计算方式:一张表最大存储500万数据,以x表为例:8*5000=4000万-1000万(存量数据)=3000万/2(日增)=1500天/365天=4.1年
分表后字段原样继承,不做删改。
风险考虑:避免溢出,主键等重要字段都定义成bigint,数据库和es都需要考虑。
2.3 分表策略
此次迁移的分表策略。因为迁移过来只有一个库,所以分库策略需根据实际分库情况计算。
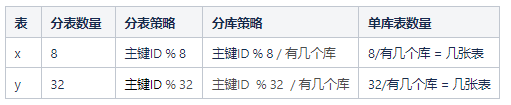
风险考虑:
- 从分库分表策略本身来说,是根据分表策略公式计算,从策略本身来说,合理的策略,不会存在数据倾斜的风险。
- 从业务属性来说,是根据非强业务属性ID作为分表键,ID本身也是自增的方式产生的,且不带有强烈的业务属性。不会像类似用户ID那么具有强烈的业务属性,包括用户的访问也会存在有用户ID会访问频繁,有些会很少。如果是强业务属性,需要从业务上考虑是否会有数据倾斜。
2.4 接入es分析
优点:海量查询。
缺点:延迟,查询耗时是数据库的至少十倍级。稳定性没有数据库稳定。
方案:
- y表的查询主要是根据主键进行条筛选查询,基于这样的查询语句以及es的缺点,最终决定y表的查询主要还是查库,查询字段较多的做索引。
- x表的查询会经常采用全表扫面的语句,基于这样的查询语句以及es的优点,决定把x表接入es。
风险考虑:接入es会有风险,没有另外存储一份数据,自然也没有降级策略,反而也不能有降级,如果降级数据库查询,接近于全表扫描的语句会给数据库造成很大压力。只把这样的查询接入es,一个是因为这样的查询语句是基本都用在轮询查询,可以有一定的延迟,不一定马上要求返回结果,就算es真的出现问题,不会有较大的感知,业务可能出现的感知就是进行中的状态,通常这样的业务也是允许有一定的延迟,其次,这样的查询比较少,权衡之后,可以接入es。
三、分库分表测试思路
3.1 测试质量整体把控
保障整体的分库分表的过程以及结果的质量保障,从以下几个方面进行考虑:
- 服务层:服务接口众多,再来此服务的接口没有不重要的,接口层需要保障接口正常,返回信息正确,考虑用流量回放测试。
- 数据层:首先需要保证迁移过程中的数据一致性,其次是启用后的双写一致性。
- 业务层:在业务应用方面,服务被其他业务方调用的流量较大,先在中台这边回归主流程,再部署上测试环境,让业务方回归主流程。
- 性能:此服务是底层的查询服务,对性能有一定的要求,在各个开关节点都需要进行性能的评估。
3.2 测试过程的关键点及细节
数据的一致性测试
- oceanus进行数据源的同步,只要oceanus不挂,数据源的同步就基本没什么问题,当oceanus同步任务停止后,最简单的方式就是查询条数,两边库的数据条数是否一致,还有一个就是双写的一致性,开启双写后,对比数据条数。
接口一致性
- 换言之,就要验证数据内容的一致,同理 oceanus进行数据源的同步的时候,基本是没问题的,当同步任务停止之后,如何保障接口的一致性呢?
- 还可以使用流量回放的方式,但是录制和回放中有时间差,数据发生了改变,输出的diff结果可能并不正确,这时候还需要手动的去新老库重新查一遍来验证。
- 同步任务停止后开启
QueryCheckResult开关,开关打开后,拿到数据,代码会比较新老库同一条数据,某个时间点是否一致,并输出日志,并输出日志,这个时候主要关注日志即可。
业务正确性
- 准备工作:数据一致性、接口一致性验证完成。
- 部署:代码部署测试环境,双写开关,读开关,check开关都开启
- 回归材质模型相关主流程,告知业务方,回归下接入此服务的主流程。
性能测试
- 应用性能摸底压测:刚开始进行了应用现存情况的性能压测,做后续的指标参考。
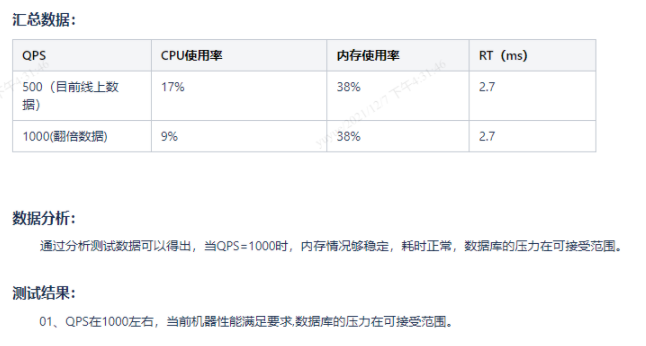
- 针对改造接入summerCache、对缓存压缩级别的压测,除metaspace一直在升外,未见其他异常。同时对应接口rt有明显下降。所以针对集群换gc收集器。
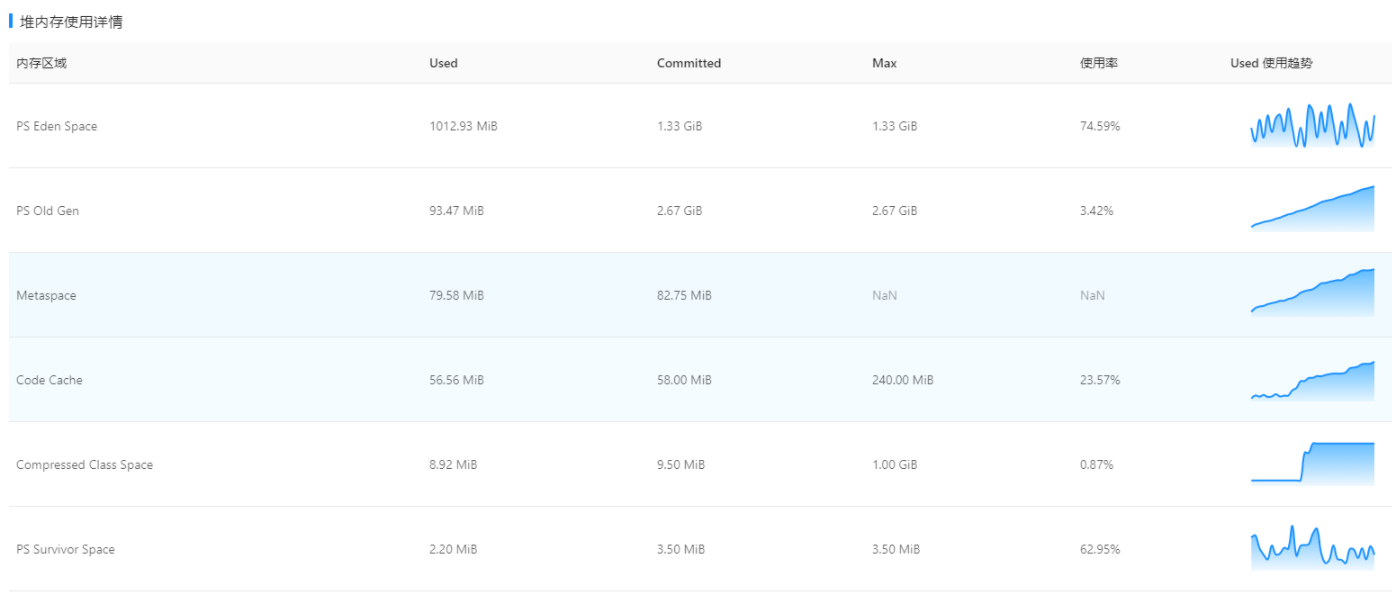
- 针对集群换gc收集器后再次压测,问题得到解决,并符合预期

- 新建测试prod库+分表改造的容量规划压测,cpu飚高,qpm上不去,新的数据库配置不够是主要瓶颈,新增一个读库,同时改造代码,扩大接入缓存的情况范围
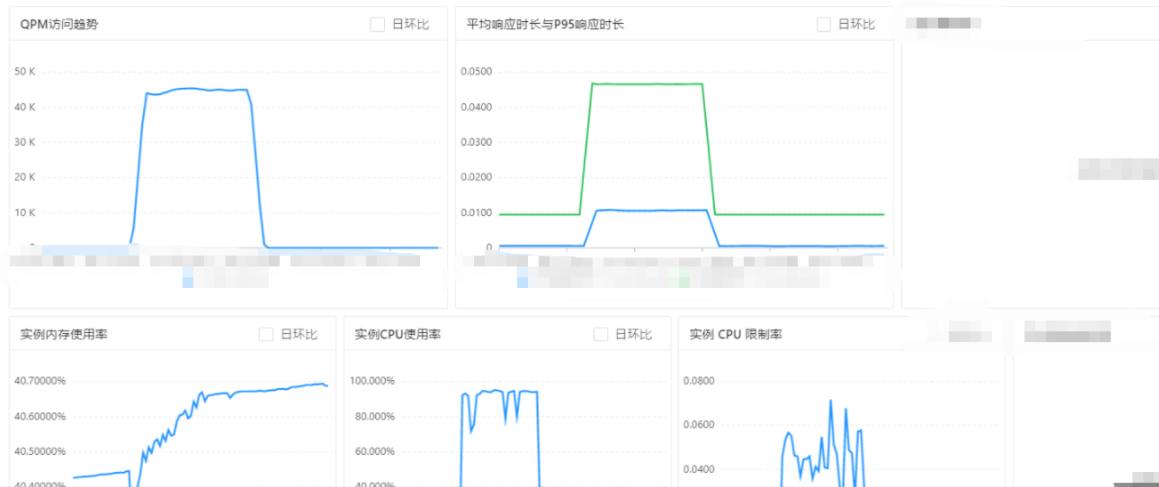
- 新拉一个读库后,改造2.0对应的压测,压测结果符合目标。
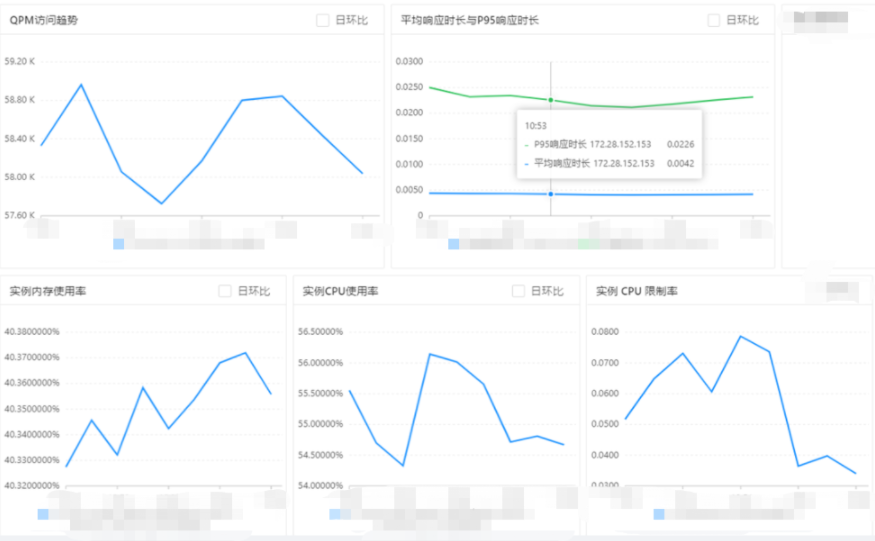
- 更新线上真实prod库容量配置后+分表改造3.0(相关接口完全接入缓存)的beta压测,压测结果符合预期,代码可以发布上线。
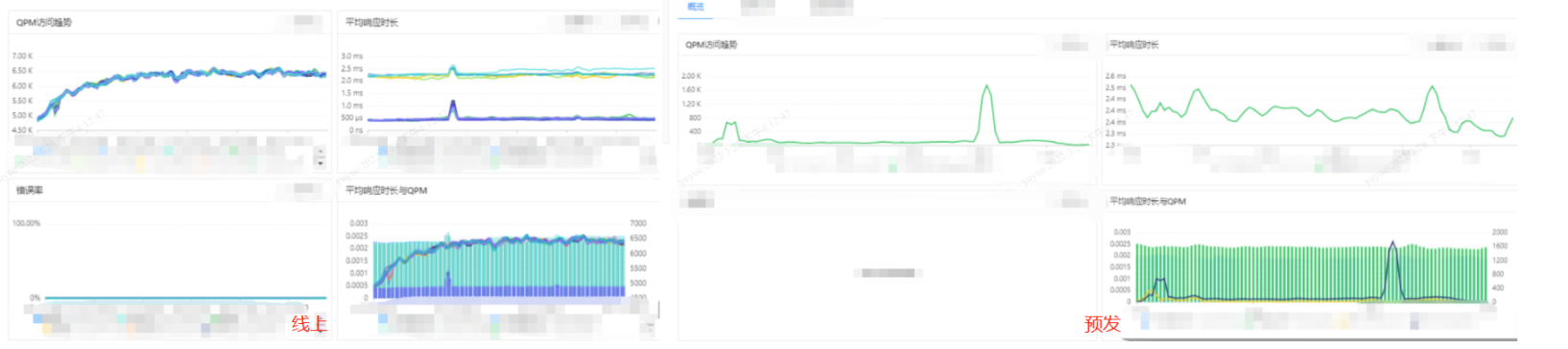
从图中可以看出,beta的数据库压力很小,中间有上升是因为,缓存失效了,重新有开始查库了,再加上beta有一定的非压测的流量进来,但总体看,对数据库的压力还是很小
prod数据可以看出平均压力在6.5k左右,数据库压力一直持续,随着QPM的增长而增长。
四、开关切换计划
第一步:配置开关和序列,序列开关是控制主键自增还是序列;搜索配置开关是搜索配置最大返回1000条数据,有空结果的会重试;summerCache开关:线上开关开启走缓存;写开关是控制双写还是单写;读开关是控制读取的数据源
第二步:一开始是打开序列,开启双写。
第三步:关闭数据源同步任务,持续至少一天,通过dbv(可阅读文章:BVT系统建设)统计count大概。确保数量级没有问题。
第四步:把读开关接es查询的开启。相当于读是读新建业务数据库和es的数据,读开始切换为新数据源
第五步:等待业务方对公共库的读全部完成接入,读写全部切换到新建业务数据库。不再继续往公共库中插入数据。
五、整体迁移过程架构示意图
- 换主键序列
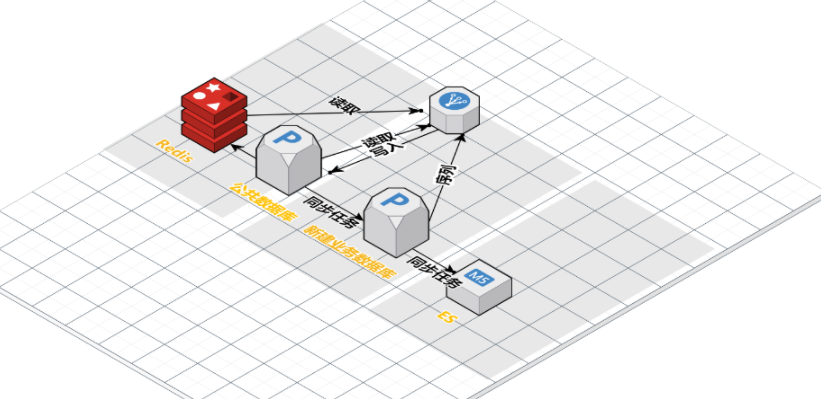
- 开启双写,往公共数据库和新建的业务数据库都写入数据
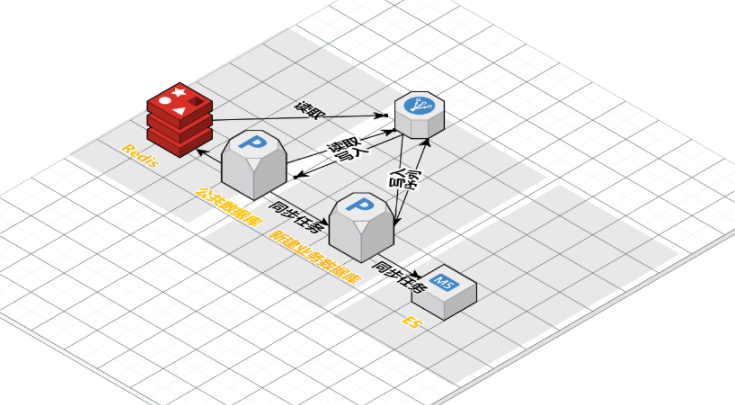
- 切读,读取新建业务库数据,为了以防万一,公共数据库做一致性兜底措施。
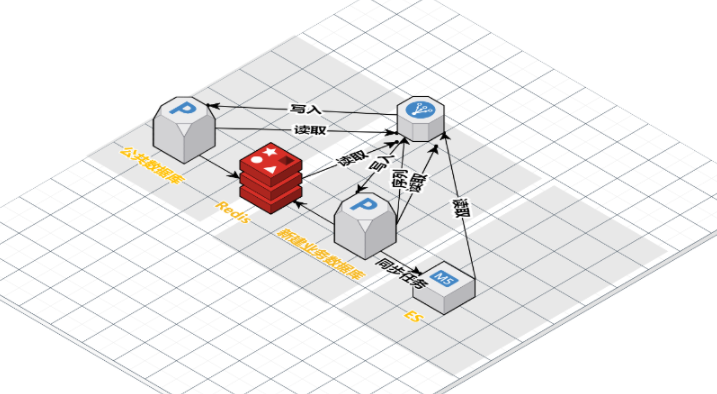
- 完全读取新建业务数据库
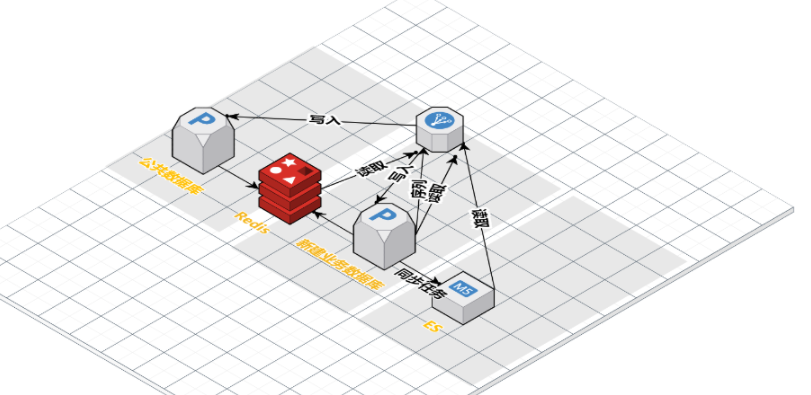
- 停写公共数据库,完成全部迁移工作

六、上线质量情况
- 通过对应用压测和容量规划,应用稳定性很高,报警和错误日志极少,业务方接入过程中顺利丝滑。
- 核心接口耗时平均降低50%+:a接口耗时降低:60%、b接口耗时降低:63%、c接口耗时降低:58%、d耗时时降低:59%,e接口耗时降低:54%,f接口耗时降低:61%,g接口耗时降低:46%。
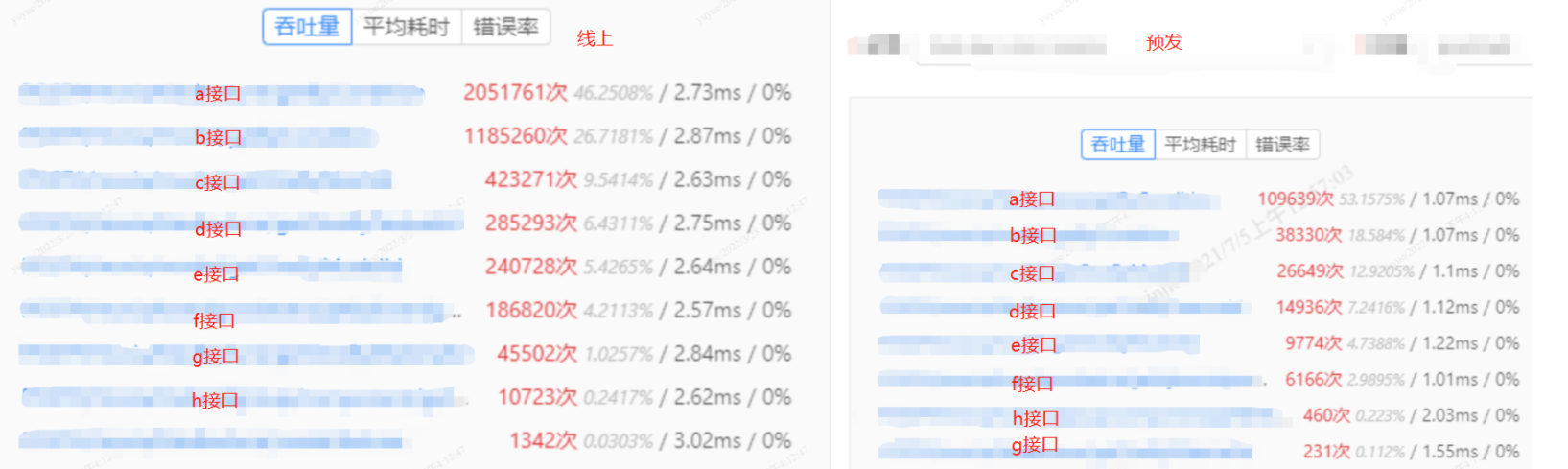
- 容量规划后整个应用对公共数据库依赖几乎完全剔除,风险又降低了许多,中间件、业务方同学给予肯定。

推荐阅读

微信公众号:酷家乐技术质量 知乎:酷家乐技术质量
TesterHome:kujiale-qa (酷家乐质量效能)